01_zookeeper简介
Posted shayzhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了01_zookeeper简介相关的知识,希望对你有一定的参考价值。
1. 分布式系统及其问题
zookeeper是帮助我们构建分布式系统的一个软件(协调员的角色)
首先,我们要明白分布式系统以及它的问题,之后才能理解为什么有zookeeper
1.1 分布式系统

分布式系统,就是多台机器通过网络互连,形成1个系统,对系统外的用户提供服务,用户看到的是1个服务,并不会感知到内部的多台机器
1.2 分布式系统的难点(问题)
考虑一下,如何对这个系统中不同机器上的进程进行协同或者说调度:
1)假设第1台机器上挂载了1个资源,3个不同机器上的进程都需要对该资源进行访问
2)对资源的访问就需要协调,做到不能同时访问,就需要1个协调员
3)单机上不同进程对资源的访问,可以通过锁机制
进程1访问资源,先获得锁,之后会该资源保持独占
进程1访问资源结束,释放锁,其他进程再来获得锁
4)如果分布式系统下,也有类似的锁机制,问题就得到解决
分布式系统下的这个锁机制 = 分布式锁 = zookeeper
2. 分布式锁的实现
2.1 面临的问题
对分布式系统的协调,难点在于网络的不确定性以及很多异常情况的考虑:
1、对服务调用的失败,并不一定是真失败;可能是返回值由于网络的原因,没有传回
2、AB都去调用C服务,并不是谁先调用,谁先执行,要考虑网络拥堵和延迟
3、类似的其他很多的问题,代码都要考虑
同时,如果给每一个分布式系统都去写一个协调软件,就是重复造轮子,更需要1个可靠、通用地协调机制
2.2 市面上哪家强?
目前比较好的分布式锁有两家:
1 Google chubby (非开源,自己用)
2 Apache zookeeper (Yahoo开发,捐赠给了Apache)
3. zookeeper概述
3.1 zookeeper是针对分布式系统设计的高可用,高性能的协调服务
zookeeper的系统模型

zookeeper系统中的三种角色
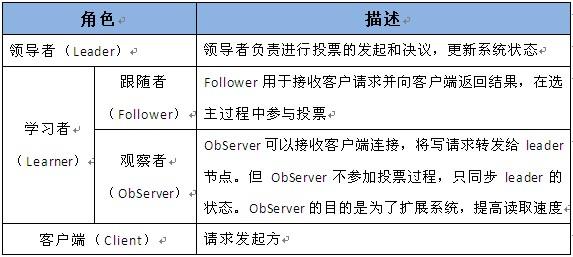
最开始zookeeper只提供分布式锁服务,后续又摸索出了其他用法:配置维护,消息订阅/分发,集群选主等;zookeeper提供这些服务,依赖于3个重要元素:
1)znode数据结构
2)对znode进行操作的函数(原语)
3)watcher通知机制
3.2 znode数据结构
zookeeper维护了1个类似文件系统目录树的数据模型
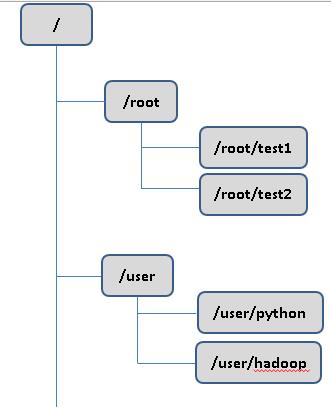
zookeeper树中的每一个成员,称为节点,znode; 和文件系统目录树还是存在区别
1)只有绝对路径
树中的每一个节点,只能使用绝对路径表示
2)znode兼备文件和目录两种特征
*文件:znode能够记录元数据(主要是版本号),数据,ACL,时间戳等
*目录:每个节点是路径标识的一部分
每个znode由3部分组成:
(1)stat: 状态信息,该znode的版本,权限等信息
(2)data: 该znode关联的数据
(3)children: 该znode下的子节点
znode虽然能够关联数据,但并不是被设计来存储大量数据,相反znode只能存储和管理调度数据(要协调的分布式应用的数据),这些数据的数据量都很小,kB级别, znode能关联的数据最大为1MB
3)znode节点类型
3种:临时节点、永久节点、顺序节点;
(1) 节点类型在创建时被确定,不能改变
(2) 临时节点:节点的生命周期依赖于Client和zk间的会话(session); 会话结束,临时节点被自动删除;每个临时节点和某一个client绑定,但所有client都能看到这个节点;临时节点不能有子节点
(3) 永久节点:节点的生命周期不依赖于会话(session),只有被Client显示删除时才会消失
(4) 顺序节点:client创建顺序节点时,指定一个路径,zookeeper自动在路径尾部添加1个递增的计数器,计数值对于此节点的父节点唯一(10位数字); 需要注意的是,删除1个顺序节点,编号005,再增加一个顺序节点,新节点的编号从006开始
3.3 znode版本和zookeeper时间
ZooKeeper有多种记录时间的形式,主要几个属性如下:
(1) Zxid格式时间戳
znode节点状态改变的每一个操作,都会在znode元数据中记录1个Zxid格式时间戳
Zxid时间戳全局有序:Zxid1<Zxid2, 则Zxid1标记的事件发生在Zxid2标记的事件之前
Zxid时间戳的本质:64位数字
(2) znode上的3个Zxid格式事务ID
每个znode, 维护3个Zxid值: cZxid、mZxid、pZxid
*cZxid: 节点被创建的Zxid格式事务ID
*mZxid: 节点被修改的Zxid格式事务ID
*pZxid: 节点的子节点最新被修改的Zxid格式事务ID
(3) znode版本号
znode节点有三个版本号,对znode的操作会导致相应的版本号发生变化
* version:节点数据版本号
* cversion:子节点版本号
* aversion:节点ACL版本号
3.4 znode元数据汇总
*cZxid: 节点被创建的Zxid事务ID
*mZxid: 节点被修改的Zxid事务ID
*pZxid: 节点被最新修改的Zxid事务ID
*ctime: 节点被创建的时间
*mtime: 节点被修改的时间
* version:节点的数据版本号
* cversion: 子节点版本号
* aversion: 节点ACL版本号
*numChildren: 子节点个数
*dataLength: 节点数据的长度
* ephermeralOwner: 临时节点所对应的会话(session)的ID;非临时节点则值为0
3.5 znode操作
对znode的操作(zk提供的原语)主要为9类:
*create 创建znode,父节点必须已经存在
*delete 删除znode, 该znode没有子节点
*getACL/setACL: 获取/设置znode的ACL
*sync: 同步客户端和zk的视图(更新client端看到的zk树)
*exists: 判断znode是否存在,并获取其元数据;客户端使用该原语,将在zk中注册1个watcher
*getData/setData: 获取/设置znode关联的数据;客户端使用该原语,将在zk中注册1个watcher
*getChildren: 获取子节点列表;客户端使用该原语,将在zk中注册1个watcher
3.5 watcher机制
(1) watcher概述
* Client端对znode的读操作,会自动在zk中注册1个watcher.
* 读操作包括:exists(), getData(), getChildren()
* 当znode发生变化, 将触发一些对应的事件event, zk自动发给事件给相应的Client端(异步发送)
(2) watcher类型
ZooKeeper中的watcher分为两类:
* 数据watcher: getData和exists会自动注册这类watcher到zk
* 孩子watcher: getChildren会自动注册这类watcher到zk
节点操作,可能会触发多个watcher事件
(1)setData,将触发该znode的数据watcher
(2)create, 将触发该znode的数据watcher, 以及其父节点的孩子watcher
(3)delete, 将触发该znode的数据watcher, 以及其父节点的孩子watch
(3) Client端在zk注册watcher和watcher事件触发

(1) exists操作上的watch,在被监视的Znode创建、删除或数据更新时被触发
(2) getData操作上的watch,在被监视的Znode删除或数据更新时被触发。在被创建时不能被触发,因为只有Znode一定存在,getData操作才会成功。
(3) getChildren操作上的watch,在被监视的Znode的子节点创建或删除,或是这个Znode自身被删除时被触发。可以通过watch事件类型, 区分出是Znode还是子节点被删除:NodeDelete表示Znode被删除,NodeDeletedChanged表示子节点被删除
节点事件的触发,通过函数exists,getData或getChildren来处理这类函数,有双重作用:
(1) 向zk服务器注册触发事件
(2) 函数本身的功能
(4) Watcher的本地维护和一次触发特点
1、Watcher在ZooKeeper服务器本地维护,设置、管理和分派。
2、Client和zk服务器断开连接后,watcher将不再被接收
3、Client和zk服务器重新建立连接后,任何先前注册过的watcher都会被重新注册
4、watcher具有一次性,在被触发一次后,就需要client端重新注册该watcher
4. zookeeper应用一: 分布式系统选主
传统的主备检测和倒换机制

zookeeper下的主备检测和倒换
(1) 启动阶段
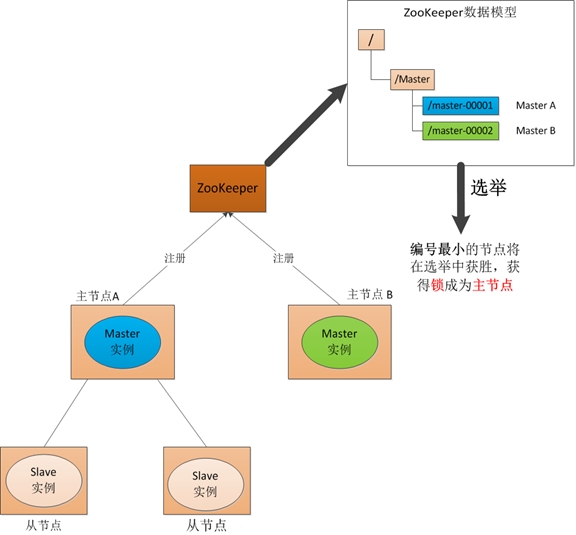
(2) Master故障
如果"主节点-A"故障,它所注册的节点将被zk自动删除,zk会然后再次发出选举,这时候"主节点-B"将在选举中获胜,成为主节点

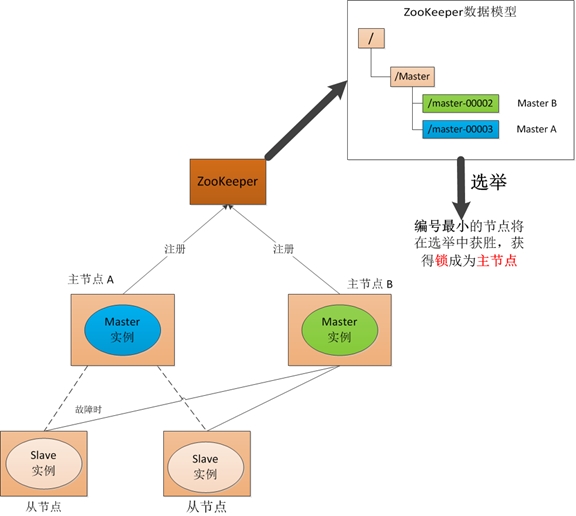
(3) 主节点恢复
如果主节点恢复,则会再次向ZooKeeper注册一个节点,此时注册的节点编号将会是"master-00003",ZooKeeper会再次发动选举,"主节点-B"会再次获胜并继续担任"主节点","主节点-A"会担任备用节点
5、zookeeper实现配置管理
集中式的配置管理在应用集群中是非常常见的,一般商业公司内部都会实现一套集中的配置管理中心,应对不同的应用集群对于共享各自配置的需求,并且在配置变更时能够通知到集群中的每一个机器。
Zookeeper很容易实现这种集中式的配置管理,比如将APP1的所有配置配置到/APP1 znode下,APP1所有机器一启动就对/APP1这个节点进行监控(zk.exist("/APP1",true)),并且实现回调方法process,当zookeeper上/APP1 znode节点数据发生变化的时候,每个机器都会收到通知,Watcher实例调用process方法,各个机器去获取最新的数据即可(zk.getData("/APP1",false, stat);
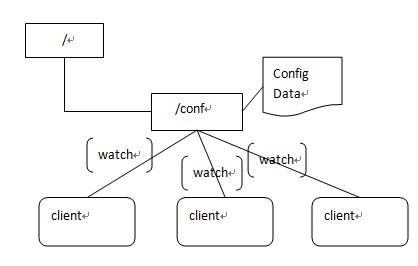
6、zookeeper实现集群管理
多台机器构成的应用系统,我们可能需要让每一个机器知道集群中(或依赖的其他某一个集群)哪些机器是live的,并且能够在不人工介入的场景下自动将节点down的事件通知到每一个机器。
Zookeeper可以容易地实现这个功能: 比如zookeeper服务器端有一个znode叫/APP1Servers, 应用集群中每台机器启动时,都去这个节点下创建一个临时节点,比如server1创建/APP1Servers/Server1(可以使用ip,保证不重复),server2创建/APP1Servers/Server2, 所有应用集群的机器都关注 /APP1Servers这个节点的数据变化或者子节点列表变化,当有某一台应用集群的机器down机,触发子节点列表发生变化的event, zk集群自动通知关注该事件的所有zk客户端。本质上,是利用了当zk客户端和zk服务器断连或者session过期就会自动删除临时节点的特性
另外有一个应用场景就是集群选master,一旦master挂掉能够马上能从slave中选出一个master,实现步骤和前者一样,只是机器在启动的时候在APP1SERVERS创建的节点类型变为EPHEMERAL_SEQUENTIAL类型,这样每个节点会自动被编号,
我们默认规定编号最小的为master,所以当我们对/APP1SERVERS节点做监控的时候,得到服务器列表,当编号最小的master宕机,znode自动消失,zk客户端在收到event后,再次获取最新的子节点列表,并且设置最小编号的节点为master,就完成了动态master选举

【参考博客】http://www.cnblogs.com/sunddenly/p/4033574.html
【参考博客】http://cailin.iteye.com/blog/2014486/
以上是关于01_zookeeper简介的主要内容,如果未能解决你的问题,请参考以下文章