JPA的学习
Posted OverZeal
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JPA的学习相关的知识,希望对你有一定的参考价值。
JPA是Java Persistence API的简称,中文名Java持久层API。是Java EE5.0平台中Sun为了统一持久层ORM框架而制定的一套标准,注意是一套标准,而不是具体实现,不可能单独存在,需要有其实现产品。Sun挺擅长制定标准的,例如JDBC就是为了统一连接数据库而制定的标准,而我们使用的数据库驱动就是其实现产品。JPA的实现产品有HIbernate,TopLink,OpenJPA等等。值得说一下的是Hibernate的作者直接参与了JPA的制定,所以JPA中的一些东西可以与Hibernate相对比。
JPA特点:
- JPA可以使用xml和注解映射源数据,JPA推荐使用注解来开发。
- 它有JPQL语言也是面向对象的查询语言,和hql比较类似。
环境搭建
我们使用Hibernate作为JPA的实现产品,需要导入的jar包有:
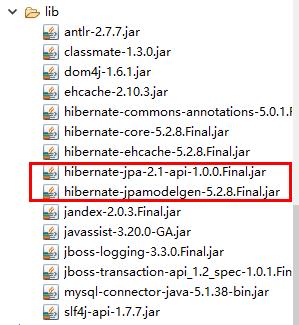
其实也就是Hibernate的required包下的jar,重点在于有Hibernate-jpa-api这个jar的存在
注意:不要忘了我们的数据库驱动jar
Persistence.xml文件的编写
JPA规范要求在内路径下META-INF目录下放置persistence.xml文件,文件名称是固定的。这个文件在于spring整合之后就可以取消了。
一个简单persistence.xml文件配置:
<?xml version="1.0" encoding="UTF-8"?> <persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"> <persistence-unit name="jpa-1" transaction-type="RESOURCE_LOCAL"> <!-- 配置使用什么 ORM 产品来作为 JPA 的实现 1. 实际上配置的是 javax.persistence.spi.PersistenceProvider 接口的实现类 2. 若 JPA 项目中只有一个 JPA 的实现产品, 则也可以不配置该节点. --> <!-- <provider>org.hibernate.ejb.HibernatePersistence</provider> --> <provider>org.hibernate.jpa.HibernatePersistenceProvider</provider> <!-- 添加持久化类 (推荐配置)--> <class>cn.lynu.model.User</class> <properties> <!-- 连接数据库的基本信息 --> <property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/> <property name="javax.persistence.jdbc.url" value="jdbc:mysql:///jpa"/> <property name="javax.persistence.jdbc.user" value="root"/> <property name="javax.persistence.jdbc.password" value="root"/> <!-- 配置 JPA 实现产品的基本属性. 配置 hibernate 的基本属性 --> <property name="hibernate.format_sql" value="true"/> <property name="hibernate.show_sql" value="true"/> <property name="hibernate.hbm2ddl.auto" value="update"/> </properties> </persistence-unit> </persistence>
name:用于定义持久单元名称,必须。
transaction-type:指定JPA的事务处理策略,RESOURCE_LOCAL 是默认值,数据库级别的事务,只支持一种数据库,不支持分布式事务。如果要支持分布式事务,要使用JTA策略:transaction-type:“JTA”
开始操作实体类
我们可以使用注解来映射源数据了,而不用再编写如Hibernate中的*.hbm.xml文件了,Hibernate中其实就可以使用JPA的注解来映射数据,学习了JPA之后,通过使用JPA来增加Dao层的通用性。
@Entity
标注用于实体类声明语句之前,指出该Java 类为实体类,将映射到指定的数据库表。如声明一个实体类 Customer,它将映射到数据库中的 customer 表上。
@Table
当实体类与其映射的数据库表名不同名时需要使用 @Table 标注说明,该标注与 @Entity 标注并列使用。
常用选项是 name,用于指明数据库的表名。

@Id
标注用于声明一个实体类的属性映射为数据库的主键列,可以使用在属性上,也可以使用在getter方法上
@GeneratedValue
用于标注主键的生成策略,通过 strategy 属性指定。默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:
SqlServer 对应 identity,MySQL 对应 auto increment
在 javax.persistence.GenerationType 中定义了以下几种可供选择的策略(可以看到JPA没有Hibernate的主键生成策略多,因为其只是做一个抽象):
- IDENTITY:采用数据库 ID自增长的方式来自增主键字段,Oracle 不支持这种方式;
- AUTO: JPA自动选择合适的策略,是默认选项;
- SEQUENCE:通过序列产生主键,通过 @SequenceGenerator 注解指定序列名,MySql 不支持这种方式;
- TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。
在我的Mysql使用@GeneratedValue为默认值时,会识别为序列的方式,所以我都是自己指定为IDENTITY方式。

Sequence策略
在Oracle中没有主键自动增长,所以都是使用序列替代这一功能的,GeneratedValue如何通过序列产生主键呢?
首先我们的Oracle数据库中需要创建一个序列
将GeneratedValue的strategy设置为GenerationType.SEQUENCE
还需要使用一个@SequenceGenerator 注解来配置一些序列的信息
@GeneratedValue(generator="seq",strategy=GenerationType.SEQUENCE)
@SequenceGenerator(name="seq",allocationSize=1,sequenceName="master_seq")
@GeneratedValue的generator的值和@SequenceGenerator的name值需要保持一致;allocationSize 表明每次增长1,其实这个属性在数据库中创建序列的时候可以指定步长,所以可以不写;sequenceName需要指明在数据库中我们创建的序列名。
TABLE策略
将当前主键的值单独保存到一个数据库的表中(存主键的表),主键的值每次都是从指定的表中查询来获得 这种方法生成主键的策略可以适用于任何数据库,不必担心不同数据库不兼容造成的问题。
就不是只使用@GeneratedValue注解了,而是使用@TableGenerator和@GeneratedValue配合:

name :表示该主键生成策略的名称,它被引用在@GeneratedValue中设置的generator 值中
table :表示表生成策略所持久化的表名
pkColumnName :表示在持久化表中,该主键生成策略所对应键值的名称(存主键的表中表示id的字段名)
pkColumnValue :表示在持久化表中,该生成策略所对应的主键(也就是该实体类对应的表的主键字段名)
valueColumnName :表示在持久化表中,该主键当前所生成的值,它的值将会随着每次创建累加(存主键的表中表示值的字段名)
所以生成的存主键的表结构为:
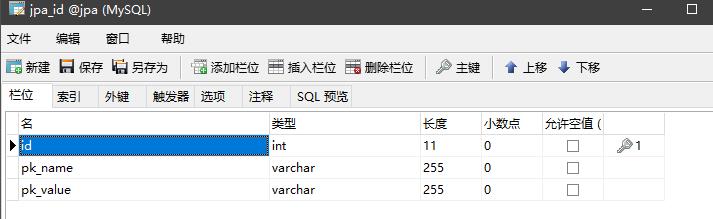
pk_name就是在pkColumnName 中设置的,对应需要使用table方式生成主键的表的id
pk_value就是在valueColumnName 中设置的,其值并非是在设置主键初始值
@Column
当实体的属性与其映射的数据库表的列不同名时需要使用@Column 标注说明,该属性通常置于实体的属性声明语句之前,还可与 @Id 标注一起使用。
@Column 标注的常用属性是 name,用于设置映射数据库表的列名。此外,该标注还包含其它多个属性,如:unique 、nullable、length 等。

@Transient
表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性. 如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则,如果我们使用了自动建表,就会将不需要的属性映射为表的字段。
@Temporal
在核心的 Java API 中并没有定义 Date 类型的精度(temporal precision). 而在数据库中,表示 Date 类型的数据有 DATE, TIME, 和 TIMESTAMP 三种精度(即单纯的日期,时间,或者两者兼备). 在进行属性映射时可使用@Temporal注解来调整精度。

默认将时间类型映射为时间戳类型,也就是有日期有时间的,如果我们只需要日期,如生日字段,就需要使用Date类型,只需要时间,就使用Time类型
JPA API
创建EntityManagerFactory和EntityManager
JPA也是需要先创建一个EntityManagerFactory(类似于Hibernate中的SessionFactory),通过这个工厂再来生成EntityManager(类似于Hibernate的Session)。
EntityManagerFactory是通过Persistence类的静态方法 createEntityManagerFactory生成,方法的参数指定JPA的持久单元名称,也就是我们在persistence.xml文件中写的name名。
EntityManager再通过EntityManagerFactory的createEntityManager方法创建。
开启事务使用的是:entityManager.getTransaction();得到一个EntityTransaction 对象,再通过这个对象的begin方法就可以开启事务了
private EntityManagerFactory entityManagerFactory; private EntityManager entityManager; private EntityTransaction transaction; @Before public void init() { entityManagerFactory=Persistence.createEntityManagerFactory("jpa-1"); entityManager=entityManagerFactory.createEntityManager(); transaction=entityManager.getTransaction(); //开启事务 transaction.begin(); }
我们再来写一个关闭的方法,规范一下代码:
@After public void destroy() { //提交事务 transaction.commit(); entityManager.close(); entityManagerFactory.close(); }
注意:我们使用的JAP的类和注解都是使用的javax.persistence包下的,不要导错了
EntityManager下的方法
find (Class<T> entityClass,Object primaryKey):返回指定的 OID 对应的实体类对象,如果这个实体存在于缓存中,则返回一个被缓存的对象;否则会创建一个新的 Entity, 并加载数据库中相关信息;若 OID 不存在于数据库中,则返回一个 null。第一个参数为被查询的实体类类型,第二个参数为待查找实体的主键值。类似于Hibernate中的get方法。
getReference (Class<T> entityClass,Object primaryKey):与find()方法类似,不同的是:如果缓存中不存在指定的 Entity, EntityManager 会创建一个 Entity 类的代理,但是不会立即加载数据库中的信息,只有第一次真正使用此 Entity 的属性才加载,所以如果此 OID 在数据库不存在,getReference() 不会返回 null 值, 而是抛出EntityNotFoundException,类似于Hibernate中的load方法。
//类似于hibernate 中 session 的 get方法 //调用find方法时就发sql @Test public void testFind() { User user = entityManager.find(User.class, 1); System.out.println("-------------------------"); System.out.println(user); } //类似于Hibernate 中 session 的 load方法 //使用的时候才发sql @Test public void testGetReference() { User user = entityManager.getReference(User.class, 1); System.out.println("-------------------------"); System.out.println(user); }
persist (Object entity):用于将新创建的 Entity 纳入到 EntityManager 的管理。该方法执行后,传入 persist() 方法的 Entity 对象转换成持久化状态。
如果传入 persist() 方法的 Entity 对象已经处于持久化状态,则 persist() 方法什么都不做。
如果对游离状态的实体执行 persist() 操作,可能会在 persist() 方法抛出 EntityExistException(也有可能是在flush或事务提交后抛出),这一点也就是说persist方法不能保存游离态的实体,不同于Hibernate的是,HIbernate可以保存游离态的对象。
//添加方法类似于hibernate 的 session 中的 save方法 //不同点:但是不能添加存在id属性的实例(游离态), hibernate可以 @Test public void testPersist() { User user=new User(); user.setUserName("张三110"); user.setEmail("110@qq.com"); user.setBirth(new Date()); user.setCreateTime(new Date()); entityManager.persist(user); }
remove (Object entity):删除实例。如果实例是被管理的,即与数据库实体记录关联,则同时会删除关联的数据库记录。
与HIbernate不同点在于JPA是不能删除在游离态的对象,HIbernate可以通过删除游离态的对象来影响到数据库中对应的数据,但是不推荐这样做。
//类似于Hibernate 中session 的delete方法 //不同点:remove不可以删除游离态的对象, //hibernate可以删除游离态的对象,并且会影响到数据库中的数据 //hibernate可以操作(插入或删除)游离态的对象,而JPA不可以 @Test public void testRemove() { User user = entityManager.find(User.class, 1); entityManager.remove(user); }
merge (T entity):merge() 用于处理 Entity 的同步。即数据库的插入和更新操作,类似于HIbernate中的SaveOrUpdate方法。
/** * 总的来说: 类似于 hibernate Session 的 saveOrUpdate 方法. */ //1. 若传入的是一个临时对象(没有id) //会创建一个新的对象, 把临时对象的属性复制到新的对象中, 然后对新的对象执行持久化操作(insert). 所以 //新的对象中有 id, 但以前的临时对象中没有 id. @Test public void testMerge1(){ User user=new User(); user.setUserName("张三123"); user.setEmail("123@qq.com"); user.setBirth(new Date()); user.setCreateTime(new Date()); User user2 = entityManager.merge(user); // 返回持久化对象的引用 System.out.println(user.getId()); System.out.println(user2.getId()); } //若传入的是一个游离对象, 即传入的对象有 OID. //1. 若在 EntityManager 缓存中没有该对象 //2. 若在数据库中也没有对应的记录(先进行select查询) //3. JPA 会创建一个新的对象, 然后把当前游离对象的属性复制到新创建的对象中 //4. 对新创建的对象执行 insert 操作. (没查到对应id的对象) @Test public void testMerge2(){ User user=new User(); user.setUserName("张三222"); user.setEmail("222@qq.com"); user.setBirth(new Date()); user.setCreateTime(new Date()); user.setId(100); User user2 = entityManager.merge(user); System.out.println(user.getId()); System.out.println(user2.getId()); } //若传入的是一个游离对象, 即传入的对象有 OID. //1. 若在 EntityManager 缓存中没有该对象 //2. 若在数据库中有对应的记录(先进行select查询) //3. JPA 会查询对应的记录, 然后返回该记录对一个的对象, 再然后会把游离对象的属性复制到查询到的对象中. //4. 对查询到的对象执行 update 操作. (查到对应id的对象) @Test public void testMerge3(){ User user=new User(); user.setUserName("张三333"); user.setEmail("333@qq.com"); user.setBirth(new Date()); user.setCreateTime(new Date()); user.setId(2); User user2 = entityManager.merge(user); System.out.println(user==user2); //false 游离态对象和返回的持久化对象不一致 } //若传入的是一个游离对象, 即传入的对象有 OID. //1. 若在 EntityManager 缓存中有对应的对象(使用find或者是getReference得到) //2. JPA 会把游离对象的属性复制到查询到EntityManager 缓存中的对象中. //3. EntityManager 缓存中的对象执行 UPDATE. @Test public void testMerge4(){ User user=new User(); user.setUserName("张三444"); user.setEmail("444@qq.com"); user.setBirth(new Date()); user.setCreateTime(new Date()); user.setId(2); User user2 = entityManager.find(User.class, 2); //缓存对象 User user3 = entityManager.merge(user); //返回的持久化对象 System.out.println(user==user2); //false 游离态对象和缓存中的对象不一致 System.out.println(user==user3); //false 游离态对象和持久化对象不一致 System.out.println(user2==user3); //true user2和user3是同一个对象(缓存中已经存在) }
映射关联关系
双向一对多及多对一映射
双向一对多关系中,必须存在一个关系维护端,在 JPA 规范中,要求 many 的一方作为关系的维护端(owner side),可以少发update语句。 one 的一方作为被维护端(inverse side)。 可以在 one 方指定 @OneToMany 注释并设置 mappedBy 属性(类似于HIbernate中的inverse属性),以指定它是这一关联中的被维护端,many 为维护端。 在 many 方指定 @ManyToOne 注释,并使用 @JoinColumn 指定外键名称。
Order类(多):
//多的一方 @ManyToOne @JoinColumn(name="user_id") //外键名 public User getUser() { return user; }
User类(一):
//一的一方 @OneToMany(mappedBy="user") //使用mappedBy 放弃维护关系(一般都让一的一方放弃,多的一方维护关系) public Set<Order> getOrders() { return orders; }
保存一对多(没有设置级联,建议先保存一再保存多,可以减少update语句)
//如果保存多对一关系时,如果没有设置级联, //建议先保存一的一方,再保存多的一方(与保存的顺序有关),就不会出现多余的update //设置级联为CascadeType.PERSIST(级联保存) 就可以通过保存Order来级联保存User @Test public void testPersistOrder() { Order order1=new Order(); order1.setOrderName("FF1"); User user=new User(); user.setUserName("李四"); user.setBirth(new Date()); user.setCreateTime(new Date()); user.setEmail("666@qq.com"); order1.setUser(user); entityManager.persist(user); entityManager.persist(order1); }
我们也可以通过设置级联,来保存一方的时候同时保存另一方:
@ManyToOne(cascade= {CascadeType.PERSIST}) @JoinColumn(name="user_id") //外键名 public User getUser() { return user; }
@Test public void testPersistOrder2() { Order order1=new Order(); order1.setOrderName("GG1"); User user=new User(); user.setUserName("李四光"); user.setBirth(new Date()); user.setCreateTime(new Date()); user.setEmail("666@qq.com"); order1.setUser(user); entityManager.persist(order1); }
删除(没有设置级联删除)
//删除时 删除关系维护端没有问题 删除被维护端报错(存在外键约束) //如果想删除,就不要设置放弃维护关系(这里是不要设置mappedBy) /** @OneToMany @JoinColumn(name="user_id") */ @Test public void testRemoveOrder() { //Order order = entityManager.find(Order.class, 3); //entityManager.remove(order); User user = entityManager.find(User.class, 16); entityManager.remove(user); }
因为我们在一的一方设置了mappedBy放弃维护关系,所以删除一的一方会出错(存在外键约束),解决办法我知道的有:
- 不要设置mappedBy属性,但是不注意保存先后顺序级就会出现多余的update
- mappedBy和cascade= {CascadeType.REMOVE}属性配合使用,但是就只能级联删除了
- 手工将多方的外键改为null
还有没什么办法可以很好的解决这个放弃维护带来的删除问题?
其实仔细一想这个异常是存在一定道理的,因为我们都知道建表或插入数据的时候是先主表,后从表;而删除的时候想删除从表,再删除主表。如果我们不先处理多的一方,而直接删除一的一方,数据库是不允许的,因为外键字段的值必须在主表中存在,这个异常也在提示我们这样的操作存在问题
一对多双向关联查询
这里有一个规律:凡是以many结尾的都默认使用懒加载,而以one结尾的默认使用立即加载。如OneToMany 默认使用的就是延迟加载,而ManyToOne,OneToOne默认使用的是立即加载
我们可以在ManyToOne(以one结尾,默认使用立即加载)设置fetch属性:fetch=FetchType.LAZY ,将其设置为懒加载
//查询关系维护端(主控方)会发一条左外连接(left outer join)的查询sql //设置了fetch 为lazy 延迟加载就不会连接查询了 @Test public void testFindOrder() { Order order = entityManager.find(Order.class, 3); System.out.println(order.getUser()); }
双向多对多关联关系
在双向多对多关系中,我们必须指定一个关系维护端(owner side),可以通过 @ManyToMany 注释中指定 mappedBy 属性来标识其为关系维护端。
Item类:
@ManyToMany @JoinTable(name="item_category", joinColumns= {@JoinColumn(name="item_id")}, inverseJoinColumns= {@JoinColumn(name="categroy_id")}) public Set<Category> getCategories() { return categories; }
@JoinTable 设置中间表
name="中间表名称",
joinColumns={@joinColumn(name="本类的外键")}
inversejoinColumns={@JoinColumn(name="对方类的外键") }
Category类:
@ManyToMany(mappedBy="categories") //根据需求让一方放弃维护 public Set<Item> getItems() { return items; }
多对多删除
//多对多的删除 @Test public void testManyToManyRemove(){ Item item = entityManager.find(Item.class, 1); entityManager.remove(item); }
没有设置级联的时候,删除时先根据删除方的id去中间表查询,查询到之后,先删除中间表,然后删除删除方的记录
双向一对一映射
基于外键的 1-1 关联关系:在双向的一对一关联中,需要在关系被维护端(inverse side)中的 @OneToOne 注释中指定 mappedBy(没有外键的一端,类似于主表),以指定是这一关联中的被维护端。同时需要在关系维护端(owner side 有外键存在的一端,类似于从表)建立外键列指向关系被维护端的主键列。
Dept和Manager是一对一关系,外键存在于Dept表中,所以然Manager放弃维护
Manager类:
@OneToOne(mappedBy="mgr") //放弃维护 public Dept getDept() { return dept; }
Dept类:
@OneToOne(fetch=FetchType.LAZY) //一对一(维护端) @JoinColumn(name="mgr_id",unique=true) public Manager getMgr() { return mgr; }
这里设置了一对一延迟加载,在使用到被维护端的时候,再去查询,而不是直接发一条left outer join 左外连接
//1.默认情况下, 若获取维护关联关系的一方, 则会通过左外连接获取其关联的对象. //但可以通过 @OntToOne 的 fetch 属性(设置延迟加载)来修改加载策略. //必须设置在维护端(主控方)的fetch属性才有效,设置在被维护端没用 @Test public void testOneToOneFind(){ Dept dept = entityManager.find(Dept.class, 1); System.out.println(dept.getDeptName()); System.out.println(dept.getMgr().getClass().getName()); }
使用二级缓存
在Hibernate中一级缓存是session级别的缓存,是默认带的且开起的,而二级缓存是sessionFactory级别的缓存,是跨session的。同理,JPA中一级缓存是EntityManager级的缓存,而二级缓存是EntityManagerFactory级别的缓存。
使用二级缓存需要配置其实现产品,这里使用的是ehcache。
先在persistence.xml文件中配置:
<!-- 配置二级缓存的策略 ALL:所有的实体类都被缓存 NONE:所有的实体类都不被缓存. ENABLE_SELECTIVE:标识 @Cacheable(true) 注解的实体类将被缓存 DISABLE_SELECTIVE:缓存除标识 @Cacheable(false) 以外的所有实体类 UNSPECIFIED:默认值,JPA 产品默认值将被使用 --> <!--ENABLE_SELECTIVE策略 在需要二级缓存的实体类上使用@Cacheable(true) --> <shared-cache-mode>ENABLE_SELECTIVE</shared-cache-mode> <!-- 二级缓存相关配置(使用的是hibernate二级缓存,缓存产品为ehcache) --> <property name="hibernate.cache.use_second_level_cache" value="true"/> <property name="hibernate.cache.region.factory_class" value="org.hibernate.cache.ehcache.EhCacheRegionFactory"/> <!-- 查询缓存 --> <property name="hibernate.cache.use_query_cache" value="true"/>
这里有个查询缓存,等到JPQL之后再说.
<shared-cache-mode> 节点:若 JPA 实现支持二级缓存,该节点可以配置在当前的持久化单元中是否启用二级缓存,可配置如下值:
- ALL:所有的实体类都被缓存
- NONE:所有的实体类都不被缓存.
- ENABLE_SELECTIVE:标识 @Cacheable(true) 注解的实体类将被缓存
- DISABLE_SELECTIVE:缓存除标识 @Cacheable(false) 以外的所有实体类
- UNSPECIFIED:默认值,JPA 产品默认值将被使用。
我们设置的配置是ENABLE_SELECTIVE,所以一定要在需要二级缓存的类上使用 @Cacheable(true) 注解标识

我们还需要在src下放入一个ehcache的配置文件:ehcache.xml
<ehcache> <!-- 指定一个目录:当 EHCache 把数据写到硬盘上时, 将把数据写到这个目录下. 如:<diskStore path="d:\\\\tempDirectory"/> --> <diskStore path="java.io.tmpdir"/> <!--默认的缓存配置--> <defaultCache maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="120" timeToLiveSeconds="120" overflowToDisk="true" /> <!-- 设定具体的命名缓存的数据过期策略。每个命名缓存代表一个缓存区域 缓存区域(region):一个具有名称的缓存块,可以给每一个缓存块设置不同的缓存策略。 如果没有设置任何的缓存区域,则所有被缓存的对象,都将使用默认的缓存策略。即:<defaultCache.../> Hibernate 在不同的缓存区域保存不同的类/集合。 对于类而言,区域的名称是类名。如:cn.lynu.entity.Dept 对于集合而言,区域的名称是类名加属性名。如cn.lynu.entity.Dept.emps --> <!-- name: 设置缓存的名字,它的取值为类的全限定名或类的集合的名字 maxElementsInMemory: 设置基于内存的缓存中可存放的对象最大数目 eternal: 设置对象是否为永久的, true表示永不过期, 此时将忽略timeToIdleSeconds 和 timeToLiveSeconds属性; 默认值是false timeToIdleSeconds:设置对象空闲最长时间,以秒为单位, 超过这个时间,对象过期。 当对象过期时,EHCache会把它从缓存中清除。如果此值为0,表示对象可以无限期地处于空闲状态。 timeToLiveSeconds:设置对象生存最长时间,超过这个时间,对象过期。 如果此值为0,表示对象可以无限期地存在于缓存中. 该属性值必须大于或等于 timeToIdleSeconds 属性值 overflowToDisk:设置基于内存的缓存中的对象数目达到上限后,是否把溢出的对象写到基于硬盘的缓存中 --> <cache name="sampleCache1" maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="300" timeToLiveSeconds="600" overflowToDisk="true" /> <cache name="sampleCache2" maxElementsInMemory="1000" eternal="true" timeToIdleSeconds="0" timeToLiveSeconds="0" overflowToDisk="false" /> </ehcache>
开始测试吧:
//开启二级缓存 @Test public IOS开发-OC学习-常用功能代码片段整理