一个完整的大作业
Posted 杨小宏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个完整的大作业相关的知识,希望对你有一定的参考价值。
本次爬取小说的网站为136书屋。
先打开花千骨小说的目录页,是这样的。
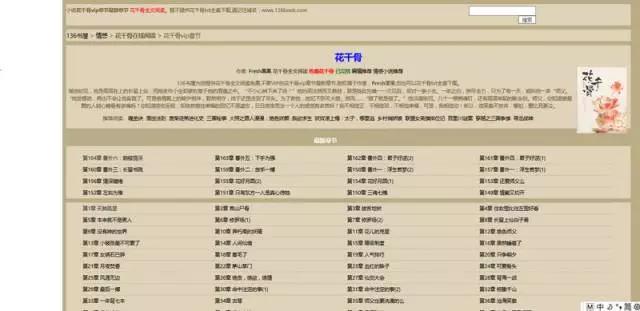
我们的目的是找到每个目录对应的url,并且爬取其中地正文内容,然后放在本地文件中。
2.网页结构分析
首先,目录页左上角有几个可以提高你此次爬虫成功后成就感的字眼:暂不提供花千骨txt全集下载。
继续往下看,发现是最新章节板块,然后便是全书的所有目录。我们分析的对象便是全书所有目录。点开其中一个目录,我们便可以都看到正文内容。
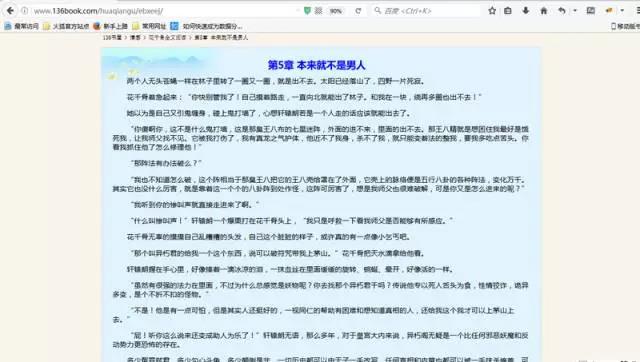
按F12打开审查元素菜单。可以看到网页前端的内容都包含在这里。
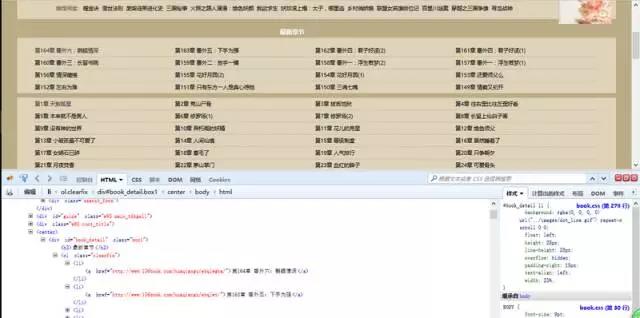
我们的目的是要找到所有目录的对应链接地址,爬取每个地址中的文本内容。
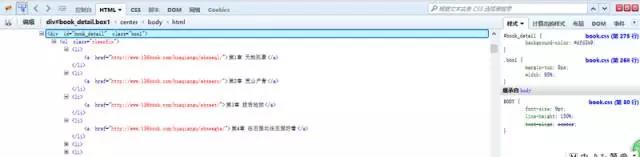
有耐心的朋友可以在里面找到对应的章节目录内容。有一个简便方法是点击审查元素中左上角箭头标志的按钮,然后选中相应元素,对应的位置就会加深显示。
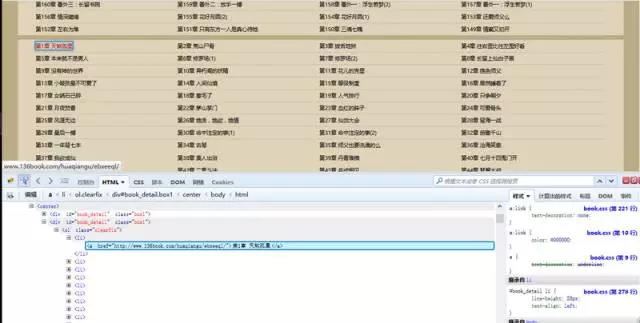
这样我们可以看到,每一章的链接地址都是有规则地存放在<li>中。而这些<li>又放在<div id=”book_detail” class=”box1″>中。
我不停地强调“我们的目的”是要告诉大家,思路很重要。爬虫不是约pao,蒙头就上不可取。
3.单章节爬虫

刚才已经分析过网页结构。我们可以直接在浏览器中打开对应章节的链接地址,然后将文本内容提取出来。
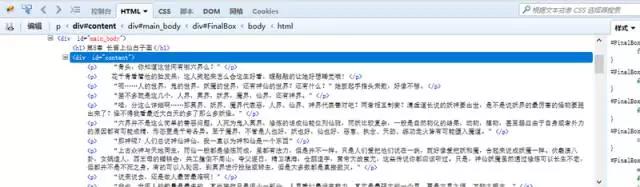
我们要爬取的内容全都包含在这个<div>里面。
代码整理如下
from urllib import request from bs4 import BeautifulSoup if __name__ == \'__main__\': # 第8章的网址 url = \'http://www.136book.com/huaqiangu/ebxeew/\' head = {} # 使用代理 head[\'User-Agent\'] = \'Mozilla/5.0 (Linux; android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (Khtml, like Gecko) Chrome/18.0.1025.166 Safari/535.19\' req = request.Request(url, headers = head) response = request.urlopen(req) html = response.read() # 创建request对象 soup = BeautifulSoup(html, \'lxml\') # 找出div中的内容 soup_text = soup.find(\'div\', id = \'content\') # 输出其中的文本 print(soup_text.text)
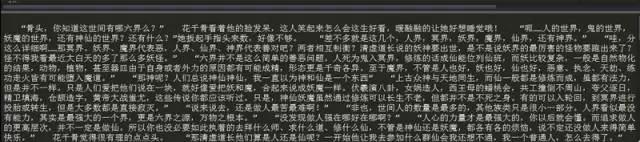
运行结果如下:
以上是关于一个完整的大作业的主要内容,如果未能解决你的问题,请参考以下文章