130242014023+李甘露美+第2次实验
Posted lglmlg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了130242014023+李甘露美+第2次实验相关的知识,希望对你有一定的参考价值。
一、实验目的
1.熟悉体系结构的风格的概念 2.理解和应用管道过滤器型的风格。 3、理解解释器的原理 4、理解编译器模型
二、实验环境
硬件:联想笔记本一台
软件:Python
三、实验内容
1、实现“四则运算”的简易翻译器。
结果要求:
1)实现加减乘除四则运算,允许同时又多个操作数,如:2+3*5-6 结果是11
2)被操作数为整数,整数可以有多位
3)处理空格
4)输入错误显示错误提示,并返回命令状态“CALC”
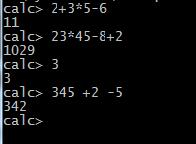
图1 实验结果示例
加强练习:
1、有能力的同学,可以尝试实现赋值语句,例如x=2+3*5-6,返回x=11。(注意:要实现解释器的功能,而不是只是显示)
2、尝试实现自增和自减符号,例如x++
2、采用管道-过滤器(Pipes and Filters)风格实现解释器
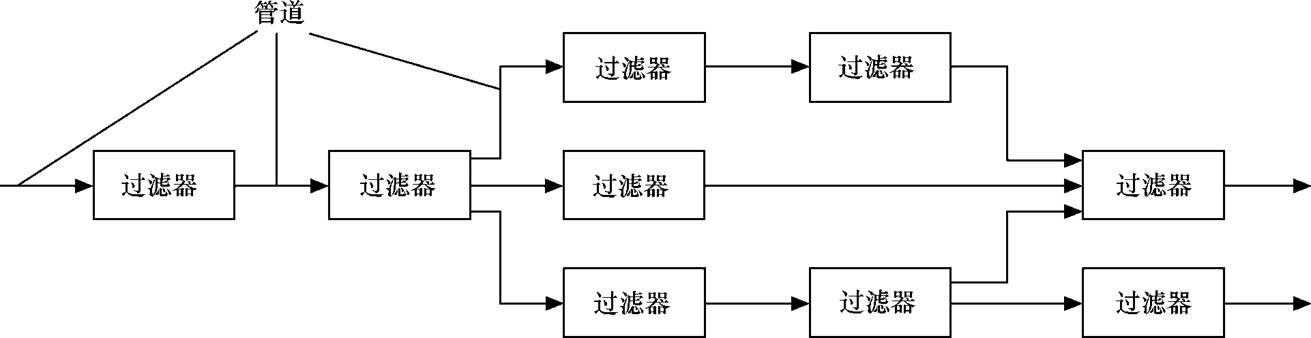
图2 管道-过滤器风格

图 3 编译器模型示意图
本实验,实现的是词法分析和语法分析两个部分。
四、实验步骤:
1 #预先定义类型(整型,加,减,乘,除,左右括号,还有结束标记 2 INTEGER,PLUS,MINUS,MUL,DIV,LPAREN,RPAREN,EOF=( 3 \'INTEGER\',\'PLUS\',\'MINUS\',\'MUL\',\'DIV\',\'LPAREN\',\'RPAREN\',\'EOF\') 4 5 #给字符打标记(标出它的类型与值) 6 class Token(object): 7 def __init__(self,type,value): 8 self.type=type 9 self.value=value 10 def __str__(self): 11 return \'Token({type},{value})\'.format( 12 type=self.type, 13 value=repr(self.value) 14 ) 15 16 #词法分析器(让输入的字符一个一个地打标记,即“认出”这些词) 17 class Lexer(object): 18 19 #给每个词打标记 20 def __init__(self,text): 21 self.text=text 22 self.pos=0 23 self.current_char=self.text[self.pos] 24 25 #错误的处理 26 def error(self): 27 raise Exception(\'Invalid Char\') 28 29 #往下走 30 def advance(self): 31 self.pos+=1 32 if self.pos>len(self.text)-1: 33 self.current_char=None 34 else: 35 self.current_char=self.text[self.pos] 36 37 #处理多位整数 38 def integer(self): 39 40 result=\'\' 41 while self.current_char is not None and self.current_char.isdigit(): 42 result=result+self.current_char 43 self.advance() 44 return int(result) 45 46 #对空格的处理 47 def deal_space(self): 48 while self.current_char is not None and self.current_char.isspace(): 49 self.advance() 50 51 #处理下一个词 52 def get_next_token(self): 53 #打标记:1)pos+1,2)返回Token(类型,数值) 54 while self.current_char is not None: 55 #如果处理的是空格 56 if self.current_char.isspace(): 57 self.deal_space() 58 #如果处理的是数字 59 if self.current_char.isdigit(): 60 return Token(INTEGER,self.integer()) 61 #如果处理的是加号 62 if self.current_char==\'+\': 63 self.advance() 64 return Token(PLUS,\'+\') 65 #如果处理的减号 66 if self.current_char==\'-\': 67 self.advance() 68 return Token(MINUS,\'-\') 69 #如果处理的是乘号 70 if self.current_char==\'*\': 71 self.advance() 72 return Token(MUL,\'*\') 73 #如果处理的是除号 74 if self.current_char==\'/\': 75 self.advance() 76 return Token(DIV,\'/\') 77 #如果处理的是左括号 78 if self.current_char==\'(\': 79 self.advance() 80 return Token(LPAREN,\'(\') 81 #如果处理的是右括号 82 if self.current_char==\')\': 83 self.advance() 84 return Token(RPAREN,\')\') 85 #如果都不是 86 self.error() 87 return Token(EOF,None) 88 89 #句法分析 90 class Interpreter(object): 91 92 def __init__(self,lexer): 93 self.lexer=lexer 94 self.current_token=self.lexer.get_next_token() 95 96 def error(self): 97 raise Exception(\'Invalid Syntax\') 98 #判断这个位置的字符是否符合类型的要求,符合则去找下一个字符 99 def eat(self,token_type): 100 if self.current_token.type==token_type: 101 self.current_token=self.lexer.get_next_token() 102 else: 103 self.error() 104 #下面处理计算,根据括号最优先,先乘除后加减,factor比term优先,term比expr优先 105 #这里处理的是factor(即算式中的用于进行乘除运算的元素,如整数和括号表达式) 106 def factor(self): 107 token=self.current_token 108 #如果这个factor是整数 109 if token.type==INTEGER: 110 self.eat(INTEGER) 111 return token.value 112 #如果这个factor是括号表达式 113 elif token.type==LPAREN: 114 self.eat(LPAREN) 115 result=self.expr() 116 self.eat(RPAREN) 117 return result 118 #这里处理的是term(即应该优先运算的乘除操作) 119 def term(self): 120 result=self.factor() 121 while self.current_token.type in (MUL, DIV): 122 token=self.current_token 123 #进行乘运算 124 if token.type==MUL: 125 self.eat(MUL) 126 result=result*self.factor() 127 #进行除运算 128 if token.type==DIV: 129 self.eat(DIV) 130 result=result/self.factor() 131 return result 132 #这里处理的是expr(即处理加减操作) 133 def expr(self): 134 result=self.term() 135 while self.current_token.type in (PLUS, MINUS): 136 token=self.current_token 137 if token.type==PLUS: 138 self.eat(PLUS) 139 result=result+self.term() 140 if token.type==MINUS: 141 self.eat(MINUS) 142 result=result-self.term() 143 return result 144 145 146 def main(): 147 #先接受输入的算式 148 while True: 149 try: 150 text=input(\'calc_> \') 151 except EOFError: 152 break 153 if not text: 154 continue 155 #词法分析 156 lexer=Lexer(text) 157 #句法分析 158 interpreter = Interpreter(lexer) 159 #根据句法分析进行计算 160 result=interpreter.expr() 161 print(result) 162 163 if __name__==\'__main__\': 164 main()
在该代码的执行过程中涉及到的结构图如下:
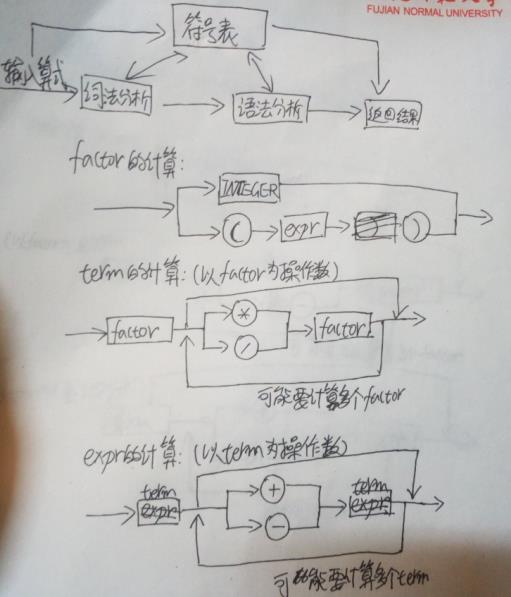
五、实验总结
首先要感谢这次的实验,有幸能接触到Python语言,算是一种新的了解和尝试吧。Python是一种比较通俗易懂,语法也比较特别的脚本语言,比较适合这次的管道——过滤器风格的层层递进的结构,这次的例子也是浅显易懂的,“麻雀虽小,五脏俱全”,步骤和顺序是很清晰的:接收字符集,对每个字符进行词法分析,判断整个算式的语法,一层一层的计算,返回最后的结果。
通过这次的实验,我对管道——过滤器风格有了更深刻更具体的了解。
以上是关于130242014023+李甘露美+第2次实验的主要内容,如果未能解决你的问题,请参考以下文章
130242014032 ++“电商系统搜索功能模块”需求分析与设计实验课小结