软件体系结构的第二次实验(解释器风格与管道过滤器风格)
Posted 绍华~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件体系结构的第二次实验(解释器风格与管道过滤器风格)相关的知识,希望对你有一定的参考价值。
一、实验目的
1.熟悉体系结构的风格的概念
2.理解和应用管道过滤器型的风格。
3、理解解释器的原理
4、理解编译器模型
二、实验环境
硬件:
软件:Python或任何一种自己喜欢的语言
三、实验内容
1、实现“四则运算”的简易翻译器。
结果要求:
1)实现加减乘除四则运算,允许同时又多个操作数,如:2+3*5-6 结果是11
2)被操作数为整数,整数可以有多位
3)处理空格
4)输入错误显示错误提示,并返回命令状态“CALC”
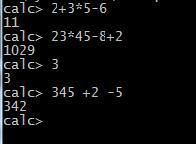
图1 实验结果示例
加强练习:
1、有能力的同学,可以尝试实现赋值语句,例如x=2+3*5-6,返回x=11。(注意:要实现解释器的功能,而不是只是显示)
2、尝试实现自增和自减符号,例如x++
3、采用管道-过滤器(Pipes and Filters)风格实现解释器
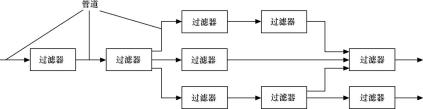
图2 管道-过滤器风格
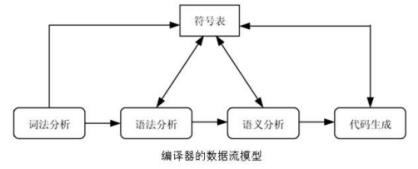
图 3 编译器模型示意图
本实验,实现的是词法分析和语法分析两个部分。
四、实验步骤:
代码部分:
# 初始变量:整形数字,加法,减法,乘法,除法,左括号,右括号,EOF
INTEGER,PLUS,MINUS,MUL,DIV,LPAREN,RPAREN,EOF=(\'INTEGER\',\'PLUS\',\'MINUS\',\'MUL\',\'DIV\',\'LPAREN\',\'RPAREN\',\'EOF\')
# Token类,存放运算的各个单元
class Token(object):
def __init__(self,type,value):
self.type=type
self.value = value
def __str__(self):
return \'Token({type},{value})\'.format(
type = self.type,
value = self.value
)
class Lexer(object):
# 词法分析器
# 给每个词打标记
def __init__(self, text):
self.text=text
self.pos=0
self.current_char=self.text[self.pos]
def error(self):
raise Exception(\'取不到数\')
def advance(self):
#往下走,取值
self.pos+=1
if self.pos>len(self.text)-1:
self.current_char=None
else:
self.current_char=self.text[self.pos]
def integer(self):
#多位整数处理
result=\'\'
while self.current_char is not None and self.current_char.isdigit():
result=result+self.current_char
#往下走,取值
self.advance()
return int(result)
def deal_space(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def get_next_token(self):
#打标记:1)pos+1,2)返回Token(类型,数值)
while self.current_char is not None:
if self.current_char.isspace():
self.deal_space()
if self.current_char.isdigit():
return Token(INTEGER,self.integer())
if self.current_char==\'+\':
self.advance()
return Token(PLUS,\'+\')
if self.current_char==\'-\':
self.advance()
return Token(MINUS,\'-\')
if self.current_char==\'*\':
self.advance()
return Token(MUL, \'*\')
if self.current_char==\'/\':
self.advance()
return Token(DIV, \'/\')
if self.current_char==\'(\':
self.advance()
return Token(LPAREN, \'(\')
if self.current_char==\')\':
self.advance()
return Token(RPAREN, \')\')
self.error()
return Token(EOF,None)
class Interpreter(object):
#句法分析
def __init__(self,lexer):
self.lexer=lexer
self.current_token=self.lexer.get_next_token()
def error(self):
raise Exception(\'无效语法错误\')
def Error1(self):
raise Exception(\'除以0错误\')
def eat(self,token_type):
if self.current_token.type==token_type:
self.current_token=self.lexer.get_next_token()
else:
self.error()
def factor(self):
token=self.current_token
if token.type==INTEGER:
self.eat(INTEGER)
return token.value
elif token.type==LPAREN:
self.eat(LPAREN)
result=self.expr()
self.eat(RPAREN)
return result
def term(self):
result=self.factor()
while self.current_token.type in (MUL,DIV):
token=self.current_token
if token.type==MUL:
self.eat(MUL)
result=result*self.factor()
if token.type==DIV:
self.eat(DIV)
fail = int(self.factor())
if fail == 0:
raise self.Error1()
return
result = result/self.factor()
return result
def expr(self):
result=self.term()
while self.current_token.type in (PLUS,MINUS):
token=self.current_token
if token.type==PLUS:
self.eat(PLUS)
result=result+self.term()
if token.type==MINUS:
self.eat(MINUS)
result=result-self.term()
return result
def main():
while True:
try:
text=input(\'calc_> \')
except EOFError:
Interpreter.error()
break
if not text:
continue
lexer=Lexer(text)
result=Interpreter(lexer).expr()
if(result is not None):
print(result)
if __name__ == \'__main__\':
main()
运行结果:

总体结构图:
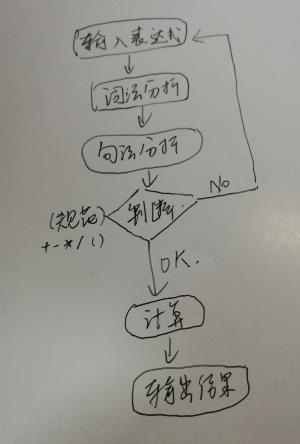
五、实验总结
1.这次实验让我学会了python基本语法,受益匪浅。
2.过程中一直在发生问题,解决问题的过程,让我对编译器有了入门了解。
以上是关于软件体系结构的第二次实验(解释器风格与管道过滤器风格)的主要内容,如果未能解决你的问题,请参考以下文章