130242014066+王伟华+第2次实验
Posted 夕阳下的奔跑啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了130242014066+王伟华+第2次实验相关的知识,希望对你有一定的参考价值。
一、实验目的
1.熟悉体系结构的风格的概念
2.理解和应用管道过滤器型的风格。
3、理解解释器的原理
4、理解编译器模型
二、实验环境
硬件:
软件:Python或任何一种自己喜欢的语言
三、实验内容
1、实现“四则运算”的简易翻译器。
结果要求:
1)实现加减乘除四则运算,允许同时又多个操作数,如:2+3*5-6 结果是11
2)被操作数为整数,整数可以有多位
3)处理空格
4)输入错误显示错误提示,并返回命令状态“CALC”
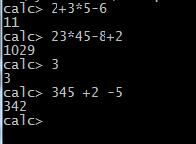
图1 实验结果示例
加强练习:
1、有能力的同学,可以尝试实现赋值语句,例如x=2+3*5-6,返回x=11。(注意:要实现解释器的功能,而不是只是显示)
2、尝试实现自增和自减符号,例如x++
2、采用管道-过滤器(Pipes and Filters)风格实现解释器
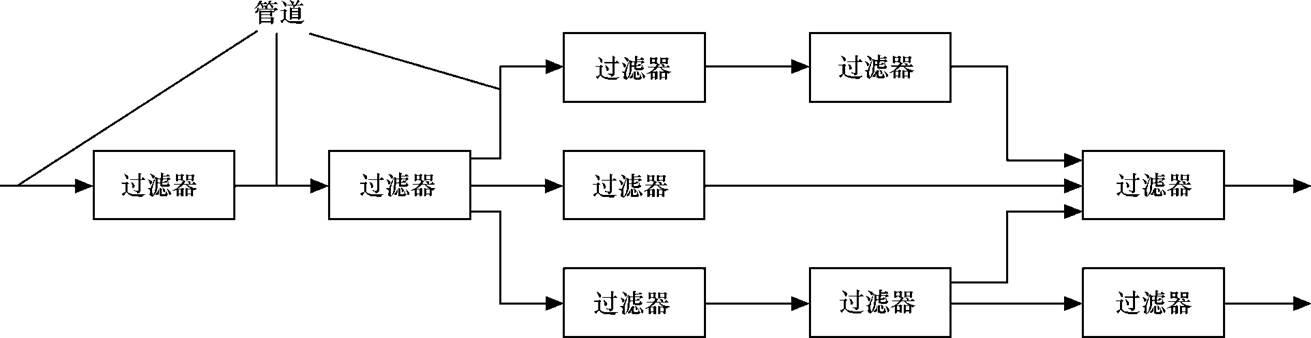
图2 管道-过滤器风格
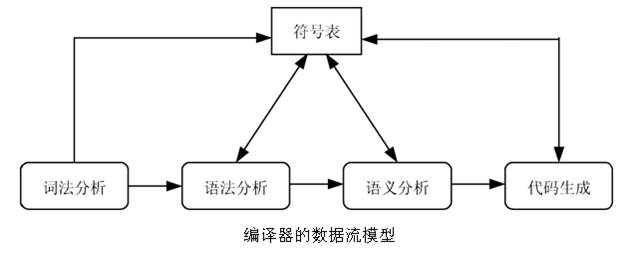
图 3 编译器模型示意图
本实验,实现的是词法分析和语法分析两个部分。
四、实验步骤:
要求写具体实现代码,并根据实际程序,画出程序的总体体系结构图和算法结构图。
总体结构图参照体系结构风格。
#定义加、减、乘号、除、跟结束符 INTEGER, PLUS, MINUS, MUL, DIV, EOF = ( \'INTEGER\', \'PLUS\', \'MINUS\', \'MUL\', \'DIV\', \'EOF\' ) class Token(object): def __init__(self, type, value): # 标记的类型: INTEGER, PLUS, MINUS, MUL, DIV, or EOF self.type = type # 标记的值: 非负整数的值, \'+\', \'-\', \'*\', \'/\', 或者无 self.value = value def __str__(self): return \'Token({type}, {value})\'.format( type=self.type, value=repr(self.value) ) def __repr__(self): return self.__str__() class Lexer(object): def __init__(self, text): self.text = text # self.pos是self.text的索引值 self.pos = 0 self.current_char = self.text[self.pos] def error(self): raise Exception(\'Invalid character\') def advance(self): self.pos += 1 if self.pos > len(self.text) - 1: self.current_char = None # 输入结束 else: self.current_char = self.text[self.pos] def skip_whitespace(self): while self.current_char is not None and self.current_char.isspace(): self.advance() def integer(self): result = \'\' while self.current_char is not None and self.current_char.isdigit(): result += self.current_char self.advance() return int(result)
#判断输入的是什么
def get_next_token(self): while self.current_char is not None: if self.current_char.isspace(): self.skip_whitespace() continue if self.current_char.isdigit(): #如果current_char是数字 return Token(INTEGER, self.integer()) if self.current_char == \'+\': #如果current_char是+ self.advance() return Token(PLUS, \'+\') if self.current_char == \'-\': #如果current_char是- self.advance() return Token(MINUS, \'-\') if self.current_char == \'*\': #如果current_char是* self.advance() return Token(MUL, \'*\') if self.current_char == \'/\': #如果current_char是/ self.advance() return Token(DIV, \'/\') self.error() #如果都不符合就返回错误 return Token(EOF, None) class Interpreter(object): def __init__(self, lexer): self.lexer = lexer # 将当前标记设置为输入的第一次标记 self.current_token = self.lexer.get_next_token() def error(self): raise Exception(\'Invalid syntax\') def eat(self, token_type): if self.current_token.type == token_type: self.current_token = self.lexer.get_next_token() else: self.error() def factor(self): token = self.current_token self.eat(INTEGER) return token.value def term(self): result = self.factor() while self.current_token.type in (MUL, DIV): token = self.current_token if token.type == MUL: self.eat(MUL) result = result * self.factor() elif token.type == DIV: self.eat(DIV) result = result / self.factor() return result def expr(self): result = self.term() while self.current_token.type in (PLUS, MINUS): token = self.current_token if token.type == PLUS: self.eat(PLUS) result = result + self.term() elif token.type == MINUS: self.eat(MINUS) result = result - self.term() return result def main(): while True: try: text = raw_input(\'calc> \') except EOFError: break if not text: continue lexer = Lexer(text) interpreter = Interpreter(lexer) result = interpreter.expr() print(result) if __name__ == \'__main__\': main()
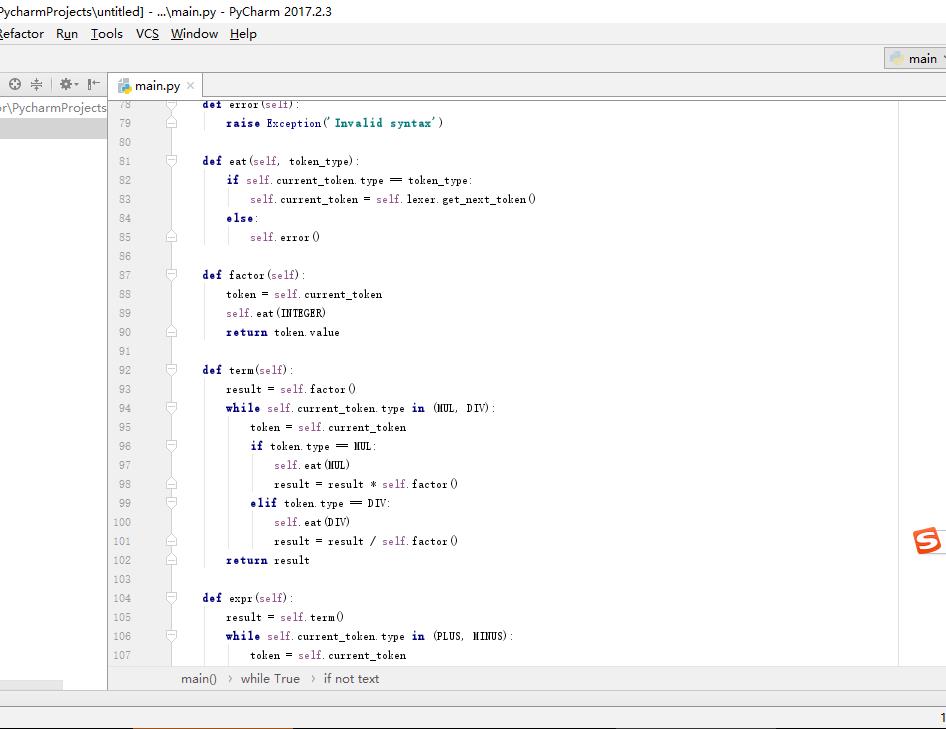
对应结构图:
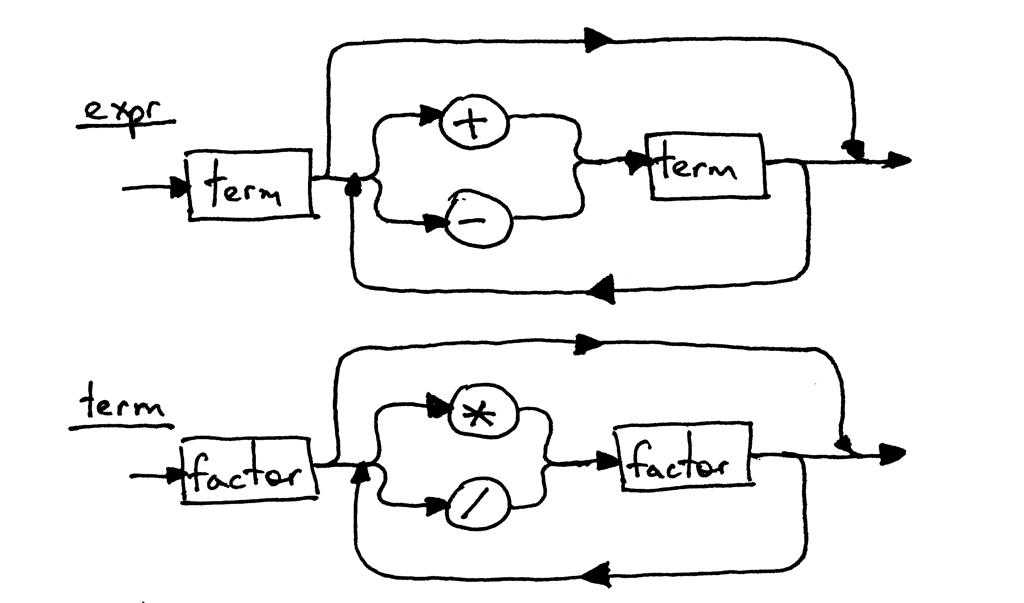
五、实验总结
对于体系结构应用的理解等。
以上是关于130242014066+王伟华+第2次实验的主要内容,如果未能解决你的问题,请参考以下文章