pandas数据处理
Posted 你好,小帝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas数据处理相关的知识,希望对你有一定的参考价值。
1、删除重复元素
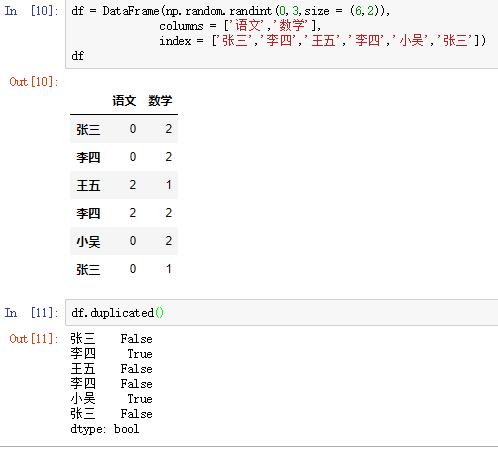
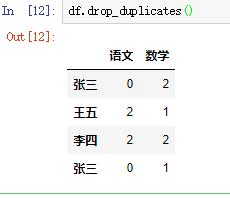
使用drop_duplicates()函数删除重复的行
如果使用pd.concat([df1,df2],axis = 1)生成新的DataFrame,新的df中columns相同,使用duplicate()和drop_duplicates()都会出问题
2. 映射
映射的含义:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定
需要使用字典:
map = { \'label1\':\'value1\', \'label2\':\'value2\', ... }
包含三种操作:
- replace()函数:替换元素
- 最重要:map()函数:新建一列
- rename()函数:替换索引
1) replace()函数:替换元素
使用replace()函数,对values进行替换操
首先定义一个字典
调用.replace()
replace还经常用来替换NaN元素
2) map()函数:新建一列
使用map()函数,由已有的列生成一个新列
适合处理某一单独的列。
仍然是新建一个字典
map()函数中可以使用lambda函数
transform()和map()类似
3) rename()函数:替换索引
仍然是新建一个字典
使用rename()函数替换行索引
使用rename()函数替换行索引
3. 异常值检测和过滤
使用describe()函数查看每一列的描述性统计量
使用std()函数可以求得DataFrame对象每一列的标准差
根据每一列的标准差,对DataFrame元素进行过滤。
借助any()函数, 测试是否有True,有一个或以上返回True,反之返回False
对每一列应用筛选条件,去除标准差太大的数据
删除特定索引df.drop(labels,inplace = True)
4. 排序
使用.take()函数排序
可以借助np.random.permutation()函数随机排序
随机抽样
当DataFrame规模足够大时,直接使用np.random.randint()函数,就配合take()函数实现随机抽样
5. 数据聚合【重点】
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心: groupby()函数
如果想使用color列索引,计算price1的均值,可以先获取到price1列,然后再调用groupby函数,用参数指定color这一列
使用.groups属性查看各行的分组情况:
6.0 高级数据聚合
可以使用pd.merge()函数将聚合操作的计算结果添加到df的每一行
使用groupby分组后调用加和等函数进行运算,让后最后可以调用add_prefix(),来修改列名
可以使用transform和apply实现相同功能
在transform或者apply中传入函数即可
transform()与apply()函数还能传入一个函数或者lambda
df = DataFrame({\'color\':[\'white\',\'black\',\'white\',\'white\',\'black\',\'black\'], \'status\':[\'up\',\'up\',\'down\',\'down\',\'down\',\'up\'], \'value1\':[12.33,14.55,22.34,27.84,23.40,18.33], \'value2\':[11.23,31.80,29.99,31.18,18.25,22.44]})
apply的操作对象,也就是传给lambda的参数是整列的数组
以上是关于pandas数据处理的主要内容,如果未能解决你的问题,请参考以下文章