0_Simple__clock
Posted 爨爨爨好
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了0_Simple__clock相关的知识,希望对你有一定的参考价值。
▶ 使用 clock() 函数在CUDA核函数内部进行计时,将核函数封装为PTX并在另外的代码中读取和使用。
▶ 源代码:文件内建核函数计时
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <time.h> 4 #include <cuda.h> 5 #include <cuda_runtime.h> 6 #include "device_launch_parameters.h" 7 #include <helper_cuda.h> 8 #include <helper_string.h> 9 10 #define NUM_BLOCKS 1 11 #define NUM_THREADS 1024 12 13 __global__ static void timedReduction(const float *input, float *output, clock_t *timer) 14 { 15 extern __shared__ float shared[]; 16 const int tid = threadIdx.x, bid = blockIdx.x; 17 18 if (tid == 0) // 0 号线程记录开始时间,调用 time.h 的计时器,一个线程块有一个开始时间和一个结束时间 19 timer[bid] = clock(); 20 21 shared[tid] = input[tid]; 22 shared[tid + blockDim.x] = input[tid + blockDim.x]; 23 24 for (int d = blockDim.x; d > 0; d /= 2) // 二分规约求最小值,每次循环后较小值保存在前半段上 25 { 26 if (tid < d) 27 { 28 float f0 = shared[tid], f1 = shared[tid + d]; 29 if (f1 < f0) 30 shared[tid] = f1; 31 } 32 __syncthreads(); 33 } 34 35 if (tid == 0) // 0 号线程输出结果 36 output[bid] = shared[0]; 37 __syncthreads(); 38 39 if (tid == 0) // 0 号线程记录结束时间 40 timer[bid + gridDim.x] = clock(); 41 } 42 43 int main(int argc, char **argv) 44 { 45 int dev = findCudaDevice(argc, (const char **)argv); // helper_cuda.h 中设置设备的函数 46 47 clock_t timer[NUM_BLOCKS * 2]; 48 float input[NUM_THREADS * 2]; 49 for (int i = 0; i < NUM_THREADS * 2; i++) 50 input[i] = (float)i; 51 52 float *dinput = NULL, *doutput = NULL; 53 clock_t *dtimer = NULL; 54 cudaMalloc((void **)&dinput, sizeof(float) * NUM_THREADS * 2); 55 cudaMalloc((void **)&doutput, sizeof(float) * NUM_BLOCKS); 56 cudaMalloc((void **)&dtimer, sizeof(clock_t) * NUM_BLOCKS * 2); 57 58 cudaMemcpy(dinput, input, sizeof(float) * NUM_THREADS * 2, cudaMemcpyHostToDevice); 59 60 timedReduction << <NUM_BLOCKS, NUM_THREADS, sizeof(float) * 2 * NUM_THREADS >> >(dinput, doutput, dtimer); 61 62 cudaMemcpy(timer, dtimer, sizeof(clock_t) * NUM_BLOCKS * 2, cudaMemcpyDeviceToHost); 63 64 cudaFree(dinput); 65 cudaFree(doutput); 66 cudaFree(dtimer); 67 68 long double sumElapsedClocks = 0; // 计算平均耗时 69 for (int i = 0; i < NUM_BLOCKS; i++) 70 sumElapsedClocks += (long double)(timer[i + NUM_BLOCKS] - timer[i]); 71 printf("Average clocks/block = %f\\n", sumElapsedClocks / NUM_BLOCKS); 72 73 getchar(); 74 return EXIT_SUCCESS; 75 }
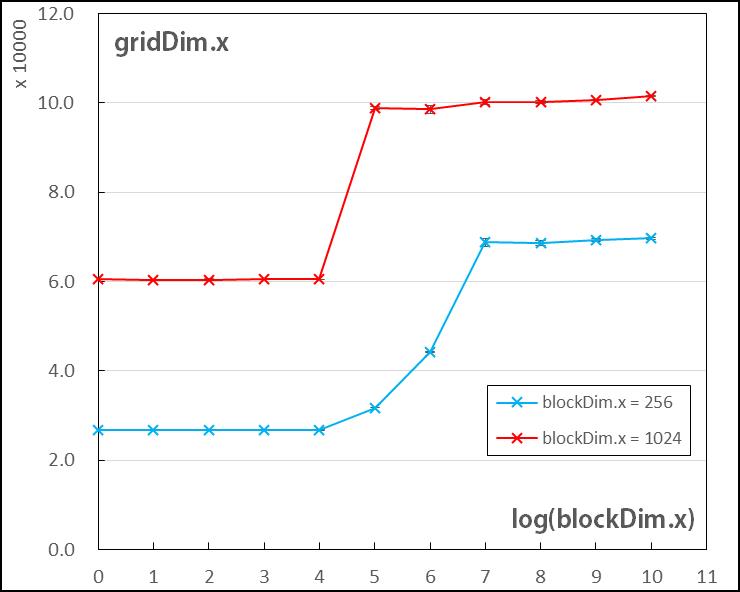
● 输出结果,比较不同的 blockDim.x 和 threadDim.x 情况结果如下图表所示。

▶ 涨姿势:
● 在核函数中也能使用 time.h 中的 clock_t 变量,并用clock() 函数计时。
▶ 源代码,封装核函数并在另外的代码中使用。分成核函数部分 clock_fernel.cu 和主函数部分 clock.cpp
1 // clock_kernel.cu 2 __global__ static void timedReduction(const float *input, float *output, clock_t *timer) 3 { 4 extern __shared__ float shared[]; 5 const int tid = threadIdx.x, bid = blockIdx.x; 6 7 if (tid == 0) 8 timer[bid] = clock(); 9 10 shared[tid] = input[tid]; 11 shared[tid + blockDim.x] = input[tid + blockDim.x]; 12 13 for (int d = blockDim.x; d > 0; d /= 2) 14 { 15 if (tid < d) 16 { 17 float f0 = shared[tid], f1 = shared[tid + d]; 18 if (f1 < f0) 19 shared[tid] = f1; 20 } 21 __syncthreads(); 22 } 23 24 if (tid == 0) 25 output[bid] = shared[0]; 26 __syncthreads(); 27 28 if (tid == 0) 29 timer[bid + gridDim.x] = clock(); 30 }
1 // main.c 2 #include <stdio.h> 3 #include <cuda.h> 4 #include <cuda_runtime.h> 5 #include <driver_functions.h> 6 #include <nvrtc_helper.h> 7 8 #define NUM_BLOCKS 64 9 #define NUM_THREADS 256 10 11 int main(int argc, char **argv) 12 { 13 typedef long clock_t; 14 clock_t timer[NUM_BLOCKS * 2]; 15 16 float input[NUM_THREADS * 2]; 17 for (int i = 0; i < NUM_THREADS * 2; i++) 18 input[i] = (float)i; 19 20 char *kernel_file = sdkFindFilePath("clock_kernel.cu", argv[0]); // 找到核函数代码文件 21 char *ptx; 22 size_t ptxSize; 23 compileFileToPTX(kernel_file, 0, NULL, &ptx, &ptxSize, 0); // 将指定核函数编译为 PTX,放在指针 ptx 指向的地址,大小为ptxSize 24 25 CUmodule module = loadPTX(ptx, argc, argv); // 读取编译好的 PTX 26 CUfunction kernel_name; 27 cuModuleGetFunction(&kernel_name, module, "timedReduction"); // 取出 PTX 中的函数 timeReducetion() 28 29 CUdeviceptr dinput, doutput, dtimer; // 内存申请和拷贝 30 cuMemAlloc(&dinput, sizeof(float) * NUM_THREADS * 2); 31 cuMemAlloc(&doutput, sizeof(float) * NUM_BLOCKS); 32 cuMemAlloc(&dtimer, sizeof(clock_t) * NUM_BLOCKS * 2); 33 cuMemcpyHtoD(dinput, input, sizeof(float) * NUM_THREADS * 2); 34 35 dim3 cudaGridSize(NUM_BLOCKS, 1, 1), cudaBlockSize(NUM_THREADS, 1, 1); 36 void *arr[] = { (void *)&dinput, (void *)&doutput, (void *)&dtimer }; // 封装核函数实参的指针 37 38 cuLaunchKernel(kernel_name, // 调用核函数,函数名 39 cudaGridSize.x, cudaGridSize.y, cudaGridSize.z, // gridDim 分量 40 cudaBlockSize.x, cudaBlockSize.y, cudaBlockSize.z, // blockDim 分量 41 sizeof(float) * 2 * NUM_THREADS, 0, // 共享内存和流号 42 &arr[0], 0); // 实参和其他参数 43 44 cuCtxSynchronize(); // 上下文同步,作用接近 cudaDeviceSynchronize() 45 cuMemcpyDtoH(timer, dtimer, sizeof(clock_t) * NUM_BLOCKS * 2); 46 cuMemFree(dinput); 47 cuMemFree(doutput); 48 cuMemFree(dtimer); 49 50 long double sumElapsedClocks = 0; // 计算耗时 51 for (int i = 0; i < NUM_BLOCKS; i++) 52 sumElapsedClocks += (long double)(timer[i + NUM_BLOCKS] - timer[i]); 53 printf("Average clocks/block = %Lf\\n", sumElapsedClocks / NUM_BLOCKS); 54 55 getchar(); 56 return EXIT_SUCCESS; 57 }
● 输出结果:
sdkFindFilePath <clock_kernel.cu> in ./ > Using CUDA Device [0]: GeForce GTX 1070 > GPU Device has SM 6.1 compute capability Average clocks/block = 3058.000000
▶ 涨姿势:
● 在外部核函数代码文件中采用 extern "C" __global__ void functionName() 来定义函数
● 使用 PTX 过程中涉及的函数
1 // 依文件名搜索其绝对路径,传入需要查找的目标文件名 filename 和可选的可执行文件目录 executable_path 2 inline char *sdkFindFilePath(const char *filename, const char *executable_path) 3 { 4 const char *searchPath[] = { "./" }; // 默认搜索路径只有当前目录,源代码中罗列了很多文件目录 5 std::string executable_name; 6 if (executable_path != 0) 7 { 8 executable_name = std::string(executable_path); 9 10 #if defined(WIN32) || defined(_WIN32) || defined(WIN64) || defined(_WIN64) // 注意 Windows 和 Linux 文件路径的分隔符不同 11 size_t delimiter_pos = executable_name.find_last_of(\'\\\\\'); 12 executable_name.erase(0, delimiter_pos + 1); 13 if (executable_name.rfind(".exe") != std::string::npos) 14 executable_name.resize(executable_name.size() - 4); 15 #else 16 size_t delimiter_pos = executable_name.find_last_of(\'/\'); 17 executable_name.erase(0, delimiter_pos + 1); 18 #endif 19 } 20 for (unsigned int i = 0; i < sizeof(searchPath) / sizeof(char *); ++i) // 遍历查找路径,找到第一个匹配的路径 21 { 22 std::string path(searchPath[i]); 23 size_t executable_name_pos = path.find("<executable_name>"); 24 if (executable_name_pos != std::string::npos) 25 { 26 if (executable_path != 0) // 额外路径非空,替换掉path中的值 27 path.replace(executable_name_pos, strlen("<executable_name>"), executable_name); 28 else // 额外路径为空,不做调整 29 continue; 30 } 31 32 #ifdef _DEBUG 33 printf("sdkFindFilePath <%s> in %s\\n", filename, path.c_str()); 34 #endif 35 36 path.append(filename); // 根据搜索的结果测试文件是否存在 37 FILE *fp; 38 FOPEN(fp, path.c_str(), "rb"); // 在 helper_strings.h 中 #define FOPEN(fHandle,filename,mode) fopen_s(&fHandle, filename, mode) 39 if (fp != NULL) 40 { 41 fclose(fp); 42 char *file_path = (char *)malloc(path.length() + 1); 43 STRCPY(file_path, path.length() + 1, path.c_str()); // #define STRCPY(sFilePath, nLength, sPath) strcpy_s(sFilePath, nLength, sPath) 44 return file_path; 45 } 46 if (fp) // ? 47 fclose(fp); 48 } 49 return 0; // 没有找到文件,返回 0 50 } 51 52 // 文本编译为PTX,输入文件名,编译参数,指向编译结果的指针,指向存放编译结果大小的指针 53 // 新版本中还多了一个参数 int requiresCGheaders,是否要用到 cooperative_groups.h,即向编译选项中添加 --include-path=cooperative_groups.h 54 void compileFileToPTX(char *filename, int argc, const char **argv, char **ptxResult, size_t *ptxResultSize) 55 { 56 std::ifstream inputFile(filename, std::ios::in | std::ios::binary | std::ios::ate); 57 if (!inputFile.is_open()) 58 { 59 std::cerr << "\\nerror: unable to open " << filename << " for reading!\\n"; 60 exit(1); 61 } 62 63 std::streampos pos = inputFile.tellg(); 64 size_t inputSize = (size_t)pos; 65 char * memBlock = new char[inputSize + 1]; 66 67 inputFile.seekg(0, std::ios::beg); 68 inputFile.read(memBlock, inputSize); 69 inputFile.close(); 70 memBlock[inputSize] = \'\\x0\'; 71 72 nvrtcProgram prog; // 编译 73 NVRTC_SAFE_CALL("nvrtcCreateProgram", nvrtcCreateProgram(&prog, memBlock, filename, 0, NULL, NULL)); 74 nvrtcResult res = nvrtcCompileProgram(prog, argc, argv); 75 76 size_t logSize; // 写日志 77 NVRTC_SAFE_CALL("nvrtcGetProgramLogSize", nvrtcGetProgramLogSize(prog, &logSize)); 78 char *log = (char *)malloc(sizeof(char) * logSize + 1); 79 NVRTC_SAFE_CALL("nvrtcGetProgramLog", nvrtcGetProgramLog(prog, log)); 80 log[logSize] = \'\\x0\'; 81 //std::cerr << "\\n compilation log ---\\n"; 82 //std::cerr << log; 83 //std::cerr << "\\n end log ---\\n"; 84 free(log); 85 86 NVRTC_SAFE_CALL("nvrtcCompileProgram", res); 87 // fetch PTX 88 size_t ptxSize; 89 NVRTC_SAFE_CALL("nvrtcGetPTXSize", nvrtcGetPTXSize(prog, &ptxSize)); 90 char *ptx = (char *)malloc(sizeof(char) * ptxSize); 91 NVRTC_SAFE_CALL("nvrtcGetPTX", nvrtcGetPTX(prog, ptx)); 92 NVRTC_SAFE_CALL("nvrtcDestroyProgram", nvrtcDestroyProgram(&prog)); 93 *ptxResult = ptx; 94 *ptxResultSize = ptxSize; 95 } 96 97 // 传入文件名和错误信息内容,向std_err中输出 98 #define NVRTC_SAFE_CALL(Name, x) \\ 99 do \\ 100 { \\ 101 nvrtcResult result = x; \\ 102 if (result != NVRTC_SUCCESS) \\ 103 { \\ 104 std::cerr << "\\nerror: " << Name << " failed with error " << nvrtcGetErrorString(result); \\ 105 exit(1); \\ 106 } \\ 107 } while(0) 108 109 // 读取编译好的PTX为模块,传入指向 ptx 代码的指针和额外参数 110 CUmodule loadPTX(char *ptx, int argc, char **argv) 111 { 112 CUdevice cuDevice = findCudaDeviceDRV(argc, (const char **)argv);// 查找设备,返回设备信息 113 114 int major = 0, minor = 0; 115 char deviceName[256]; 116 cuDeviceComputeCapability(&major, &minor, cuDevice); 117 cuDeviceGetName(deviceName, 256, cuDevice); 118 printf("> GPU Device has SM %d.%d compute capability\\n", major, minor); 119 120 cuInit(0); // cuda 设备初始化 CUresult CUDAAPI cuInit(unsigned int Flags); 121 cuDeviceGet(&cuDevice, 0); // 返回设备编号 CUresult CUDAAPI cuDeviceGet(CUdevice *device, int ordinal); 122 CUcontext context; 123 cuCtxCreate(&context, 0, cuDevice); // 创建上下文 CUresult CUDAAPI cuCtxCreate(CUcontext *pctx, unsigned int flags, CUdevice dev); 124 125 CUmodule module; 126 cuModuleLoadDataEx(&module, ptx, 0, 0, 0); // 读取模块信息 CUresult CUDAAPI cuModuleLoadDataEx(CUmodule *module, const void *image, unsigned int numOptions, CUjit_option *options, void **optionValues); 127 128 return module; 129 } 130 131 CUresult CUDAAPI cuModuleGetFunction(CUfunction *hfunc, CUmodule hmod, const char *name); // 从模块中取出指定的函数 132 133 CUresult CUDAAPI cuMemAlloc(CUdeviceptr *dptr, size_t bytesize); // 类似cudaMalloc 134 135 // 调用核函数的完整格式 136 CUresult CUDAAPI cuLaunchKernel(CUfunction f, 137 unsigned int gridDimX, unsigned int gridDimY, unsigned int gridDimZ, unsigned int blockDimX, unsigned int blockDimY, unsigned int blockDimZ, 138 unsigned int sharedMemBytes, CUstream hStream, void **kernelParams, void **extra); 139 140 CUresult CUDAAPI cuCtxSynchronize(void); // 上下文同步 141 142 CUresult CUDAAPI cuMemFree(CUdeviceptr dptr); // 类似 cudaFree
以上是关于0_Simple__clock的主要内容,如果未能解决你的问题,请参考以下文章