字符编码的前世今生(Unicode,UTF, GB2312)
Posted Zhengs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符编码的前世今生(Unicode,UTF, GB2312)相关的知识,希望对你有一定的参考价值。
转自:http://tgideas.qq.com/webplat/info/news_version3/804/808/811/m579/201307/218730.shtml
参考:http://www.cnblogs.com/leesf456/p/5317574.html
参考:http://www.mamicode.com/info-detail-1943788.html
ASCII
8个晶体管的“通”或“断”即可以代表一个字节,刚开始,计算机只在美国使用,所有的信息在计算机最底层都是以二进制(“0”或“1”两种不同的状态)的方式存储,而8位的字节一共可以组合出256(2的8次方)种状态,即256个字符,这对于当时的美国已经是足够的了,他们尝试把一些终端的动作、字母、数字和符号用8位(bit)来组合:
-
- 0000 0000 ~ 0001 1111 共 33 种状态用来表示终端的特殊动作,如打印机中的响铃为 0000 0111 ,当打印机遇到 0000 0111 这样的字节传过来时,打印机就开始响铃;
- 0010 0000 ~ 0010 1111 、 0011 1010~0110 0000 和 0111 1101 ~ 0111 1110 共 33 种状态来表示英式标点符号,如 0011 1111 即代表英式问号“?”;
- 0011 0000 ~ 0011 1001 共 10 种状态来表示“0~9”10个阿拉伯数字;
- 0100 0001 ~ 0101 1010 和 0110 0001 ~ 0111 1010共 52种状态来表示大小写英文字母;
自此,一共只用到了128种状态,即128个字符,刚好占用了一个字节中的后7位,共包括33个控制字符和95个可显示字符,这一字符集被称为ASCII(American Standard Code for Information Interchange,美国信息交换标准代码),这一套字符集在1967年被正式公布。
EASCII
虽然刚开始计算机只在美国使用,128个字符的确是足够了,但随着科技惊人的发展,欧洲国家也开始使用上计算机了。不过128个字符明显不够呀,比如法语中,字母上方有注音符号,于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语的é的二进制流为1000 0010,这样一来,这些欧洲国家的编码体系,可以表示最多256个字符了。 但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,1000 0010在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (?),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。 EASCII(Extended ASCII,延伸美国标准信息交换码)由此应运而生,
EASCII码比ASCII码扩充出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号,如下:
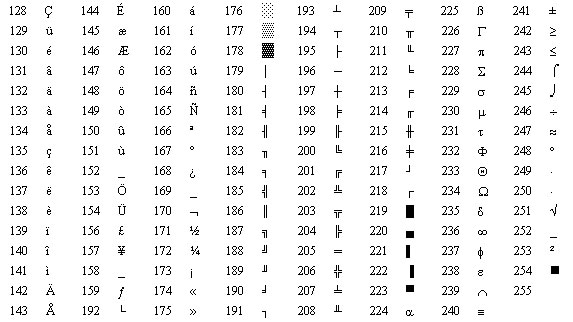
GB2312
EASCII码对于部分欧洲国家基本够用了,但过后的不久,计算机便来到了中国,要知道汉字是世界上包含符号最多并且也是最难学的文字。 据不完全统计,汉字共包含了古文、现代文字等近10万个文字,就是我们现在日常用的汉字也有几千个,那么对于只包含256个字符的EASCII码也难以满足需求了。 于是⌈中国国家标准总局⌋(现已更名为⌈国家标准化管理委员会⌋)在1981年,正式制订了中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,项目代号为GB 2312 或 GB 2312-80(GB为国标汉语拼音的首字母),此套字符集于当年的5月1日起正式实施。
包括字符:
共包含7445个字符,6763个汉字和682个其他字符(拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母)
存储方式:
基于EUC存储方式,每个汉字及符号以两个字节来表示,第一个字节为“高位字节”,第二个字节为“低位字节”
GBK
中国是一个十几亿人口的大国,微软意识到了中国是一个巨大的市场,当时的微软也将自己的操作系统市场布局进中国,进入中国随之而来要解决的就是系统的编码兼容问题。 之前的国家编码标准GB 2312,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB 2312不能处理,因此微软利用了GB2312中未使用的编码空间,收录了GB13000中的所有字符制定了汉字内码扩展规范GBK(K为汉语拼音 Kuo Zhan中“扩”字的首字母)。所以这一关系其实是大陆把Unicode1.1借鉴过来改名为了GB13000,而微软则利用GB2312中未使用的编码空间收录GB13000制定了GBK。所以GBK是向下完全兼容GB2312的。
BIG5
要知道港澳台同胞使用的是繁体字,而中国大陆制定的GB2312编码并不包含繁体字,于是信息工业策进会在1984年与台湾13家厂商签定“16位个人电脑套装软件合作开发(BIG-5)计划”,并开始编写并推出BIG5标准。 之后推出的倚天中文系统则基于BIG5码,并在台湾地区取得了巨大的成功。在BIG5诞生后,大部分的电脑软件都使用了Big5码,BIG5对于以台湾为核心的亚洲繁体汉字圈产生了久远的影响,以至于后来的window 繁体中文版系统在台湾地区也基于BIG5码进行开发。、
包括字符:
共收录13,060个汉字及441个符号
编码方式:
用两个字节来为每个字符编码,第一个字节称为“高位字节”,第二个字节称为“低位字节”
Unicode
在计算机进入中国大陆的相同时期,计算机也迅速发展进入了世界各个国家。 特别是对于亚洲国家而言,每个国家都有自己的文字,于是每个国家或地区都像中国大陆这样去制定了自己的编码标准,以便能在计算机上正确显示自己国家的符号。 但带来的结果就是国家之间谁也不懂别人的编码,谁也不支持别人的编码,连大陆和台湾这样只相隔了150海里,都使用了不同的编码体系。 于是,世界相关组织意识到了这个问题,并开始尝试制定统一的编码标准,以便能够收纳世界所有国家的文字符号。 在前期有两个尝试这一工作的组织:
国际标准化组织(ISO)
统一码联盟
简单理解:Unicode,是一张表,它为世界上所有文字字符都分配了一个唯一编号(也称为码点,如字符A,它的编号是:十进制数字 41)。而UTF-8,UTF-16呢,会以Unicode这个编号为基础,通过一个规定算法,计算出他们各自的编码值。
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。
具体信息平面如下(以下数字表示16进制数}:
第零平面:范围是0x00000 - 0x0FFF (或者 U+0000 - U+FFFF),又称BMP(英文为 Basic Multilingual Plane)
第一平面:范围是0x10000 - 0x1FFFF(或者 U+10000 - U+1FFFF)
第二平面:范围是0x20000 - 0x2FFFF(或者 U+20000 - U+2FFFF)
。
。
。
第16平面:范围是0x100000 - 0x10FFFF(或者 U+100000 - U+10FFFF)
目前的Unicode字符分为17个平面,,每个平面的范围从 0x0000 至 0xFFFF,而每平面拥有65536个码位,共1114112个。具体编码请查看:https://unicode-table.com/cn
UTF-8
变长的编码方案,使用1~4个字节为Unicode中的每个字符编码。
算法(由Unicode到UTF-8的转化):
|
Unicode编码(十六进制)
|
UTF-8 字节流(二进制)
|
|
000000-00007F
|
0xxxxxxx
|
|
000080-0007FF
|
110xxxxx 10xxxxxx
|
|
000800-00FFFF
|
1110xxxx 10xxxxxx 10xxxxxx
|
| 010000-1FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
说明:对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。
UTF-16
关于Unicode如何转化为UTf-16编码规则如下
① 若Unicode码点在第零平面(BPM)中,则使用2个字节进行编码。
② 若Unicode码点在其他平面(辅助平面),则使用4个字节进行编码。
关于辅助平面的码点编码更详细解析如下:
辅助平面码点被编码为一对16比特(四个字节)长的码元, 称之为代理对(surrogate pair),
第一部分称为高位代理(high surrogate)或前导代理(lead surrogates),码位范围为:D800-DBFF.
第二部分称为低位代理(low surrogate)或后尾代理(trail surrogates), 码位范围为:DC00-DFFF。
注意,高位代理的码位从D800到DBFF,而低位代理的码位从DC00到DFFF,总共恰好为D800-DFFF(这部分码点是Unicode保留的,不映射到任何字符),所以UTF-16编码巧妙的利用了这点来进行码点在辅助平面内的4字节编码。
例一:
字符\'A\'的Unicode码点为65(十进制),十六进制表示为41。根据规则,UTF-16采用2个字节进行编码。那么问题又来了,知道了采用两个字节编码,并且我们也知道计算机是以字节为单位进行存储,这两个字节应该表示为00 41(十六进制)?或者是41 00(十六进制)呢?这就引出了一个问题,需要用到之前提及的BOM机制来解决。
例二:
已经超出了第一平面(BMP)所能表示的范围。其在辅助平面内,根据规则,UTF-16采用4个字节进行编码。然而其编码不是简单扩展为4个字节(00 01 01 6E),而是采用如下规则进行计算。
① 使用Unicode码位减去100000(十六进制),得到的值扩展20位(因为Unicode最大为10 FF FF(十六进制),减去1 00 00(十六进制)后,得到的结果最大为0FFF FF(十六进制),即为20位,不足20位的,在高位加一个0,扩展至20位即可)。
② 将步骤一得到的20位,按照高十位和低十位进行分割。
③ 将步骤二的高十位扩展至2个字节,再加上D800(十六进制),得到高位代理或前导代理。取值范围是D800 - 0xDBFF。
④ 将步骤二的低十位扩展至2个字节,再加上DC00(十六进制),得到低位代理或后尾代理。取值范围是DC00 - 0xDFFF。
按照这个规则,我们计算字符![]() 的UTF-16编码,首先其Unicode码点为1016E,减去10000得到016E,扩展至0016E,进行分割,得到高十位为00 0000 0000,十六进制为0000,加上D800为D800;得到低十位为01 0110 1110,十六进制为016E,加上DC00为DD6E;综合得到D8 00 DD 6E。即UTF-16编码为D8 00 DD 6E(也可为D8 0 DD 6E)。
的UTF-16编码,首先其Unicode码点为1016E,减去10000得到016E,扩展至0016E,进行分割,得到高十位为00 0000 0000,十六进制为0000,加上D800为D800;得到低十位为01 0110 1110,十六进制为016E,加上DC00为DD6E;综合得到D8 00 DD 6E。即UTF-16编码为D8 00 DD 6E(也可为D8 0 DD 6E)。
BOM是个神马
BOM是byte-order mark的缩写,为Unicode标准为了用来区分一个文件是UTF-8还是UTF-16或UTF-32编码方式的记号,又称字节序。
UTF-8以单字节为编码单元,并没有字节序的问题,而UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?这是UTF-16文件开头的BOM就有作用了。
采用Unicode编码方式的文件如果开头出现了“FEFF”,“FEFF”在UCS中是不存在的字符,也叫做“ZERO WIDTH NO-BREAK SPACE”,那么就表明这个文件的字节流是Big-Endian(高字节在前)的;如果收到“FFFE”,就表明字节流是Little-Endian(低字节在前)。
在UTF-8文件中放置BOM主要是微软的习惯,BOM其实是为UTF-16和UTF-32准备的,微软在UTF-8使用BOM是因为这样可以把UTF-8和ASCII等编码明确区分开,但这样的文件在Window以外的其他操作系统里会带来问题。
我们以Window下的文本文件为例:

在保存时可以选择ANSI、Unicode、Unicode big endian和UTF-8四种编码方式。
-
- 其中ANSI是默认的编码方式,对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码);
- Unicode其实是UTF-16 endian big编码方式,这个把带有BOM的小端序UTF-16称作Unicode而又不详细说明,也是微软的习惯;
- 而Unicode big endian则是带有BOM的大端序编码方式
目前UTF-16通常用于系统文件的编码,而UTF-32由于对每个字符都采用四个字节编码,所以现在互联网中大部分都采用UTF-8来进行编码传输。
以上是关于字符编码的前世今生(Unicode,UTF, GB2312)的主要内容,如果未能解决你的问题,请参考以下文章