solr6.6初探之主从同步
Posted 专注Java后端技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了solr6.6初探之主从同步相关的知识,希望对你有一定的参考价值。
1.关于solr索引数据同步
通常情况下,单节点部署的solr应用很难在并发量很大的情况下"久存",那么多节点部署提高Solr应用的负载量和响应时间势在必行。
solr索引同步有以下特点:
·影响复制的配置由单个文件solrconfig.xml控制
·支持配置文件和索引文件的复制
·跨平台工作,配置相同
·与Solr紧密结合;管理页面提供了对复制各个方面更细粒度控制
·基于java的复制特性作为请求处理程序实现。因此,配置复制类似于任何正常的请求处理程序。
 当主节点索引更新时,所变更的数据会拷贝到所有子节点上
当主节点索引更新时,所变更的数据会拷贝到所有子节点上
2.配置ReplicationHandler
在运行主从复制之前,应该设置处理程序初始化的参数:
·replicateAfter :SOLR会自行在以下操作行为发生后执行复制,有效的值为commit, optimize, startup
·backAfter:solr在以下操作后会发生备份,有效的值为commit, optimize, startup
·maxnumberofbackup:一个整数值,决定了该节点在接收备份命令时将保留的最大备份数量。
·maxNumberOfBackups :指定要保留多少备份。这可以用来删除除最近的N个备份。
·commitReserveDuration:如果提交非常频繁并且您的网络速度很慢,可以调整这个参数来保留增量索引的周期时间,默认是10秒
在${core.home}/conf/solrConfig.xml中进行主节点配置实例:
<requestHandler name="/replication" class="solr.ReplicationHandler"> <lst name="master"> <str name="replicateAfter">commit</str> <str name="backupAfter">optimize</str> <str name="confFiles">schema.xml,stopwords.txt,elevate.xml</str> <str name="commitReserveDuration">00:00:10</str> </lst> <int name="maxNumberOfBackups">2</int> <lst name="invariants"> <str name="maxWriteMBPerSec">16</str> </lst> </requestHandler>
从节点配置:
·masterUrl:主节点的地址,从节点通过replication参数来发送同步指令
·pollInterval:设置抓取间隔时间,用HH:mm:ss的格式设置
·compression 可选值:external,internal(局域网推荐使用此值)
<requestHandler name="/replication" class="solr.ReplicationHandler"> <lst name="slave"> <!-- fully qualified url for the replication handler of master. It is possible to pass on this as a request param for the fetchindex command --> <str name="masterUrl">http://remote_host:port/solr/core_name/replication</str> <!-- Interval in which the slave should poll master. Format is HH:mm:ss . If this is absent slave does not poll automatically. But a fetchindex can be triggered from the admin or the http API --> <str name="pollInterval">00:00:20</str> <!-- THE FOLLOWING PARAMETERS ARE USUALLY NOT REQUIRED--> <!-- To use compression while transferring the index files. The possible values are internal|external. If the value is \'external\' make sure that your master Solr has the settings to honor the accept-encoding header. See here for details: http://wiki.apache.org/solr/SolrHttpCompression If it is \'internal\' everything will be taken care of automatically. USE THIS ONLY IF YOUR BANDWIDTH IS LOW. THIS CAN ACTUALLY SLOWDOWN REPLICATION IN A LAN --> <str name="compression">internal</str> <!-- The following values are used when the slave connects to the master to download the index files. Default values implicitly set as 5000ms and 10000ms respectively. The user DOES NOT need to specify these unless the bandwidth is extremely low or if there is an extremely high latency --> <str name="httpConnTimeout">5000</str> <str name="httpReadTimeout">10000</str> <!-- If HTTP Basic authentication is enabled on the master, then the slave can be configured with the following --> <str name="httpBasicAuthUser">username</str> <str name="httpBasicAuthPassword">password</str> </lst> </requestHandler>
注意:从节点masterUrl属性应当配置为主节点的地址
3.关于solr主从复制之repeater模式
在上述配置中有一个弊端:
·一主多从模式,主节点存在宕机的风险,那么从节点会群龙无首(solr暂时未提供主节点选举策略)
·从节点很多的情况下,会严重拉低主节点的性能(占有主节点服务器网络资源,占有磁盘I/O,提升CPU占有率等)
solr这里提供了一套机制,就是repeater(中转器模式),简单来说将一定量的solr服务器配置成即是主节点又是从节点的模式:
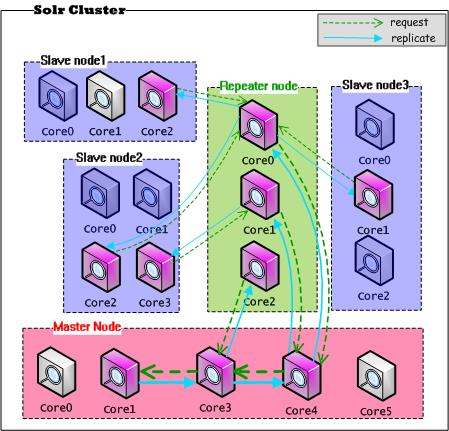
由图我们看到 从节点访问repeater(中转器)即可,因此从而减轻了主节点的压力,也一定程度上了解决单点故障。
配置实例如下:
<requestHandler name="/replication" class="solr.ReplicationHandler"> <lst name="master"> <str name="replicateAfter">commit</str> <str name="confFiles">schema.xml,stopwords.txt,synonyms.txt</str> </lst> <lst name="slave"> <str name="masterUrl">http://master.solr.company.com:8983/solr/core_name/replication</str> <str name="pollInterval">00:00:60</str> </lst> </requestHandler>
从节点的masterUrl属性改成reapter的地址,另外replicateAfter必须设置为commit
以上是关于solr6.6初探之主从同步的主要内容,如果未能解决你的问题,请参考以下文章
NoSQL初探之人人都爱Redis:Redis主从复制架构初步探索