翻译 为什么我的数据库应用程序如此缓慢?
Posted 奔跑吧菜鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译 为什么我的数据库应用程序如此缓慢?相关的知识,希望对你有一定的参考价值。
为什么我的数据库应用程序如此缓慢?
当您的应用程序运行缓慢时,反射操作将会导致数据库查询。诚然,一些更为奢侈的延迟可以被公平地归咎于缺失的索引或不必要的锁定,但在这出戏中还有其他潜在的反派角色,包括网络和应用程序本身。丹·特纳(Dan Turner)指出,你可以在深入细节之前确定问题的所在,从而节省大量的时间和金钱。
缓慢的应用程序首先会影响最终用户,但是整个团队很快就会感受到影响,包括DBA、Dev团队、网络管理员和系统管理员。
有这么多人参与其中,每个人都有自己的观点,很难确定瓶颈到底在哪里。
一般来说,SQL Server应用程序的性能问题主要有两个原因:
网络问题——与“管道”连接您的SQL应用程序客户机到数据库的“管道”的速度和容量有关
缓慢的处理时间——与处理请求的速度和效率有关,在管道的一端。
在本文中,我们将详细介绍如何诊断这些问题,并了解性能问题的底层。
网络问题
网络性能问题广泛地分解成与网络(延迟)或网络容量(带宽)的响应速度相关的问题,即它可以在一个设置的时间内传输多少数据。
当然,两者是相互关联的。如果你的应用程序(或同一网络上的其他应用程序)产生的网络流量超过了可用的带宽,那么这将会增加延迟。
延迟
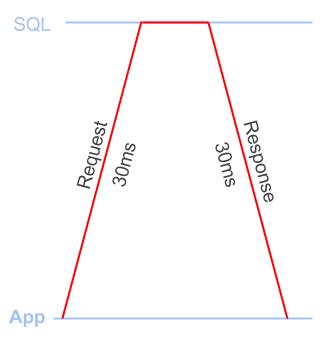
延迟是在应用程序和SQL服务器之间发送TCP包所需的时间。你在到达DB的路上会引起延迟,然后在下降的时候。人们通常在往返时间上谈论延迟时间:即到达那里和返回的时间
图1显示了一个60毫秒的往返行程。
带宽
可以在一段时间内发送或接收的数据量,通常以kb / s或Mb / s(兆比特每秒)来计算。
人们在讨论带宽时经常谈论“你的管道的大小”,这是一个很好的类比(加上它听起来很顽皮):你的管道越肥,你能同时通过它的数据越多。
如果你的应用程序需要接收10兆字节的响应(这是80兆位!),并且你有20 Mb/ s的连接,响应至少需要4秒才能收到。如果你有10Mb / s的连接,至少需要8秒的时间。如果你的网络上的其他人都在观看《权力的游戏》,那将会减少可用的带宽。
应用程序问题:缓慢的处理时间
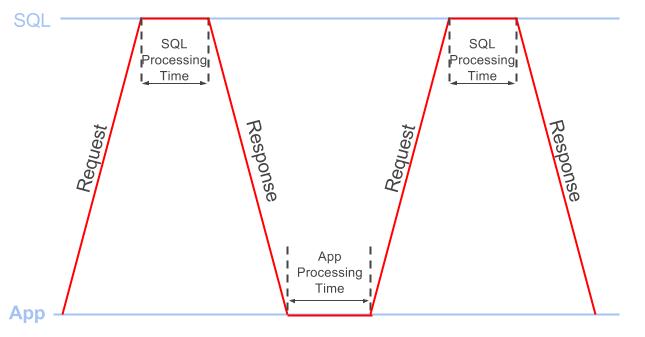
每当客户端向SQL Server发送请求时,要检索所需的数据集,完成请求所需的总处理时间包括:
应用程序处理时间:在发送下一个请求之前,应用程序需要多长时间来处理之前的响应的数据
SQL处理时间:SQL在发送响应之前花多长时间处理请求
图2提供了这个概念的简单说明。
时间花在哪里?
我们花了很多时间来研究客户机/服务器SQL应用程序的性能,并且有大量不同的工具、脚本和方法来帮助您解决各种不同类型的性能问题。
那么,当面对缓慢的应用程序响应时间时,我们如何快速确定问题的根本原因呢?图3中的流程图展示了一种处理问题的系统方法。
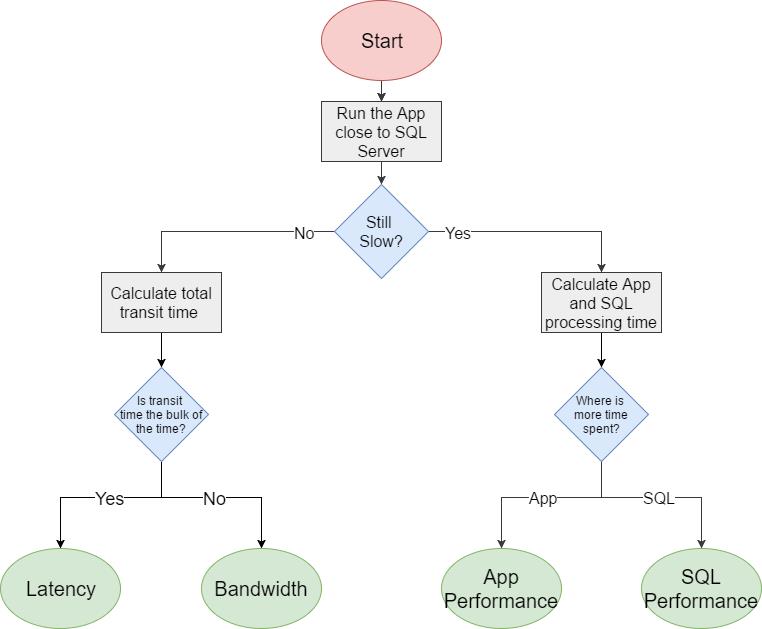
在调查性能问题时,您可能会遇到不止一个问题。看看应用程序的几个不同部分,这是一个普遍问题吗?或者有些部件比其他部件慢得多?
最好从小做起。如果你能专注于一个特别慢的应用程序的特定区域,它会让生活变得更简单,例如,当你点击发票页面上的“选择所有”按钮时,加载结果需要10秒。专注于一个可重复的小工作流可以让您隔离这个问题。
下一个要回答的问题是,为什么要花10秒钟?缩小问题的第一个也是最简单的方法是,在同一个机器上,或者在同一个局域网中,尽可能地将应用程序运行到SQL Server上。
如果有效地删除了任何网络延迟和带宽限制,它突然需要一秒或更少的时间来选择所有的发票,然后您需要调查什么网络问题可能会在其余的时间里消耗掉。
如果应用程序仍然花10秒来加载结果,那么恭喜你,你又一次删除了4个问题中的2个!现在,您需要查看正在使用的大部分处理时间。
让我们仔细看看如何计算出这段时间的大部分时间花在哪里。您将需要Wireshark或SQL Profiler(以您更舒适的方式)。
调查应用程序处理时间
您将在两个位置中的一个中看到时间:在向应用程序发送响应和获取下一个请求(应用程序处理时间)之间,或者在向SQL Server发出请求并得到响应(SQL处理时间)之间进行。
为了找出导致您的问题的原因,您可以使用Wireshark或SQL Profiler,因为两者都可以告诉我们大致的应用程序和SQL处理时间(尽管确切的数字可能略有不同)。
使用Wireshark
我们可以使用Wireshark在工作流执行时捕获网络流量。使用Wireshark允许我们过滤非应用程序的流量,并查看工作流中所有数据包之间的时间差异。
计算近似应用程序处理时间:
捕获工作流的包:启动Wireshark捕获并运行应用程序工作流,记住在工作流完成后停止捕获。记得选择相关的网络接口,并注意,你需要在不同的机器上运行这个应用程序,从数据库到Wireshark,以查看流量。确保您没有运行其他的本地SQL应用程序,而不是您试图捕获的其他SQL应用程序。
通过应用过滤器tds来摆脱非应用程序的流量,然后文件|导出指定的包,给出一个文件名并确保“显示”。在Wireshark中打开这个新文件。
显示当前和前一个包之间的时间差,只需添加time delta列,如下:
选择编辑|偏好|外观|列
点击+按钮,将类型下拉改为“Delta Time”,标题改为“Delta”。
过滤请求的流量:
(tds。类型= = 0x01 || tds。类型= = 0 x03 | | tds。type == 0x0E)& tds。packet_number = = 1
上面的过滤器将显示每个请求中的第一个TDS包,而Delta列现在将显示上一次请求的最后一个响应包和下一个请求之间的时间。确保包是按“No”排序的。这将确保包按照发送/接收的顺序进行。
导出为CSV,通过导航文件|导出包将|分解为CSV
在秒内计算应用程序的处理时间——在Excel中打开CSV,并在增量列中求和。
获取近似的SQL处理时间:
重新打开步骤2中创建的文件。在Wireshark的上面,过滤器的流量只是响应:
tds。type == 0x04 && tds。packet_number = = 1
上面的过滤器将显示每个响应中的第一个TDS包,而Delta列将显示上一次请求的最后一个请求包和从SQL服务器发回的第一个响应数据包之间的时间。再次,确保包是由“No”命令的。”专栏。
导出为CSV,通过导航文件|导出包将|分解为CSV
在秒内计算SQL处理时间——在Excel中打开CSV,并在增量列中求和。
使用SQL分析器
虽然使用SQL Profiler收集诊断数据会增加您的工作流程,但它仍然可以为您提供处理时间的总体图。您可以通过运行服务器端跟踪来最小化这个开销,然后按照下面的描述导出数据。或者,如果您对扩展事件和XQuery有信心,您应该能够通过该路径获得类似的数据。
首先通过捕获工作流的分析器跟踪,只使用“标准(默认)”跟踪模板。确保没有其他的东西同时在数据库中访问,所以你只是在捕捉你的流量。
如果应用程序在本地运行时是快速的,那么看起来您有网络问题。此时,您需要知道应用程序和SQL Server之间的延迟。你可以从ping中得到一个粗略的想法,它会告诉你在两者之间进行往返旅行所需的时间。当网络负荷较低时,试着测量网络负荷,增加ping时间。
如果您计算应用程序问题的查询数,您可以计算出延迟时间所花费的时间。
要获得Wireshark的查询数,可以应用以下过滤器,然后查看状态栏中的“显示”计数:
这应该告诉您延迟是您的问题。如果不是,那么就有带宽问题。
什么时刻。我们还没有明确地看到带宽问题,我们只是排除了其他问题。我们如何确认?好问题。恐怕这有点太费事了。
如果您有一个带有流量监视的网络级设备,以及与SQL server的专用连接,您可以查看并查看您的工作流是否饱和了可用的带宽。
或者,您需要查看应用程序使用了多少带宽,当您知道您没有带宽瓶颈时。为此,您需要再次运行应用程序接近数据库,捕获Wireshark中的包,并检查应用程序使用的带宽。同样,确保您没有运行任何其他的本地SQL应用程序,而不是您试图捕获的其他SQL应用程序。
一旦你完成了在Wireshark中的捕获:
使用过滤器:tds
点击统计|对话,勾选“限制显示过滤器”框。你应该在对话窗口中看到你的应用程序工作流对话。
使用的带宽被显示为“字节A -> B”和“字节B -> A”
在高延迟网络上运行应用程序时重复捕获,并再次查看所使用的带宽。如果两者之间存在较大的差异,那么您可能会受到带宽限制。
当然,为了进行准确的比较,您需要在两个测试中运行SQL Server和在类似硬件上的应用程序。例如,如果SQL Server在不那么强大的硬件上运行,那么在给定的时间内它将在网络上产生较少的流量。
根本原因分析
很有可能你有多重问题!但是,在完成上述步骤之后,您应该能够考虑到花费在处理工作流上的所有时间。如果10秒的处理时间包含6秒的SQL处理时间、3秒的传输时间和1秒的应用程序处理时间,那么您就知道如何优先考虑您的调查。
如果主要问题是缓慢的SQL处理时间,那么有很多关于调优和跟踪问题的信息。例如,由于我们已经捕获了一个Profiler跟踪,Gail Shaw的文章提供了一个关于如何在跟踪中发现过程和批量的很好的概述,这些过程是导致性能问题的主要原因。此外,Jonathan Kehayias的书对于更深入地研究SQL Server中的常见性能问题是非常有用的。
如果您正遭受网络带宽问题,那么您可能需要限制请求的数据的大小。例如,当您请求数据时,不要使用“SELECT *”。只返回必要的列,并使用WHERE或过滤器只返回必要的行。
在我们的经验中,性能问题的一个常见原因是在高延迟网络上运行“chatty”应用程序。一个喋喋不休的应用程序可以发送许多重复的和不必要的查询,使更多的网络往返旅行比必要的多。
通常,这些应用程序最初是开发的,并部署到高速LAN,因此“chattiness”从来没有真正造成问题。当数据移动到不同的位置,比如云时,会发生什么呢?或者是一个不同大陆的客户试图访问它?或者您需要构建地理上多样的灾难恢复环境?如果你考虑到1ms LAN上的每一个查询将会在60ms WAN上慢60x,你就会看到这是如何毁掉你的性能的。
简而言之,在编写客户机/服务器应用程序时,您需要避免频繁地执行相同的查询,以最小化收集所需数据所需的往返次数。最常见的两种方法是:
重写代码——例如,您可以在服务器上聚合和过滤多个数据集,以避免在每个数据集中生成查询,尽管并不总是更改应用程序
使用查询预取和缓存——有一些WAN优化工具可以做到这一点,但是它们有时很昂贵,而且很难配置来获得高性能,而不会在应用程序中引入bug
在开发我们的数据加速器工具时,我们已经对这些问题做了大量的研究,并采用了一种方法,使用机器学习来预测您的应用程序将要做什么,并预取所需的数据,以便在应用程序请求它时及时地准备好它。
总之
在你花费大量时间和金钱在一个可能的解决方案之前,确保你的问题已经解决了。我们已经看到公司花费大量的金钱和工时优化SQL查询,当他们最大的问题是应用程序性能问题。相反,我们看到公司将越来越多的RAM或cpu投入到SQL服务器中,这将永远无法弥补网络延迟所增加的额外时间。如果您能够确定工作流处理时间真正花费在哪里,那么您将以正确的方式指导您的时间和工作。
希望这给了你一些关于如何调查你自己的应用程序性能的想法,或者开始追踪你可能有的问题。
以上是关于翻译 为什么我的数据库应用程序如此缓慢?的主要内容,如果未能解决你的问题,请参考以下文章