并行计算cuda笔记
Posted 夕颜缪缪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并行计算cuda笔记相关的知识,希望对你有一定的参考价值。
声明:此处为转载,仅为方便自己学习,转载地址在文中有标注。感谢原创博主。
一、Block与thread数量的选取:
一个gpu有1个grid,1个grid有多个block,这些block以一维或二维或三维数组的形式排列,blockIdx.x就是每个block在x方向上的索引值(就是序号),而每一个block又可以分为多个thread,thread按照一维或二维的方式排列。
调用kernel函数:fun<<<N,M,S>>>,N代表N个一维block,M代表每个block里面包含M个thread,S表示共享内存。
它的完整形式是Kernel<<<Dg, Db, Ns, S>>>(param list);<<<>>>运算符内是核函数的执行参数,告诉编译器运行时如何启动核函数,用于说明内核函数中的线程数量,以及线程是如何组织的。
参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1。整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
参数Db用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。一个block中共有Db.x*Db.y*Db.z个thread。计算能力为1.0、1.1的硬件该乘积的最大值为768,计算能力为1.2、1.3的硬件支持的最大值为1024。
每个线程的ID号可以通过一维0~1024索引,也可以通过二维dx*dy=1024索引,或者通过三维dx*dy*dz=1024。这个就像图像opencv访问某个像素点一样,可以通过一维访问、或者二维访问:i+width*j。
每个块里各自有一个共享数据存储的区域,只有块内的线程可以访问;在一个块内,共享变量的修改,可能需要用到等待所有的线程处理完毕,然后再修改共享变量,可以采用syncthreads()函数用于等待。
参数Ns是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。不需要动态分配时该值为0或省略不写。
参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
在第一个CUDA程序中使用了1个线程块,每个线程块包含size个并行线程,每个线程的索引是threadIdx.x。也可以选择创建size个线程块,每个线程块包含1个线程。(哪种方式更优化?)
计算两个任意长的向量的加法,可能会比比65535长,超过了block数的最大范围,甚至于比65535×512(thread上限)还长,应该怎么办呢?下面就用
<<<128,128>>>的计算网络来搞定。
核函数改为:
__global__ void add( int *a, int *b, int *c )
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N)
{
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}
}
这段代码的精髓就在于它是一个循环,当编号为tid = threadIdx.x + blockIdx.x * blockDim.x的线程进行加法运算之后,tid += blockDim.x * gridDim.x;如果tid<N,则这个线程再做一次加法,依次循环下去。因为计算网络只有blockDim.x * gridDim.x这么大(此例为128×128),那么那些大于blockDim.x * gridDim.x并且小于N的数组分量的相加任务就需要继续分配给各个线程,如上就是用循环来分配的。
总结:我们通常选取一定数量的线程来解决问题,通常都选2的倍数。是由grid,block,thread,这种三级结构实现的。一般的程序的计算量都会超过线程数量,因此要合理的把计算量尽量平均分配给各个线程来计算。感觉上来说,编写核函数的精髓就是如何利用线程的序号(索引值)来分配计算任务。
http://www.cnblogs.com/dama116/p/6909629.html
二、共享内存和同步:
为什么要使用共享内存呢,因为共享内存的访问速度快。这是首先要明确的,下面详细研究。
cuda程序中的内存使用分为主机内存(host memory) 和 设备内存(device memory),我们在这里关注的是设备内存。设备内存都位于gpu之上,前面我们看到在计算开始之前,每次我们都要在device上申请内存空间,然后把host上的数据传入device内存。cudaMalloc()申请的内存,还有在核函数中用正常方法申请的变量的内存。这些内存叫做全局内存,那么还有没有别的内存种类呢?常用的还有共享内存,常量内存,纹理内存,他们都用一些不正常的方法申请。
它们的申请方法如下:
共享内存:__shared__ 变量类型 变量名;
常量内存:__constant__ 变量类型 变量名;
纹理内存:texture<变量类型> 变量名;
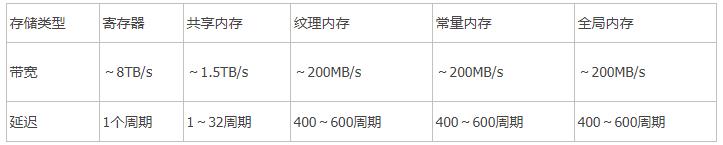
它们在不同的情况下有各自的作用,他们最大的区别就是带宽不同,通俗说就是访问速度不同。后面三个看起来没什么不同,但是他们在物理结构方面有差别,适用于不同的情况。
共享内存实际上是可受用户控制的一级缓存。申请共享内存后,其内容在每一个用到的block被复制一遍,使得在每个block内,每一个thread都可以访问和操作这块内存,而无法访问其他block内的共享内存。这种机制就使得一个block之内的所有线程可以互相交流和合作。
总结:在能用共享内存的时候尽量用,进而提高block内的执行效率,但是在同步问题上一定要慎重。
CUDA并行编程的基本思路是把一个很大的任务划分成N个简单重复的操作,创建N个线程分别执行,每个网格(Grid)可以最多创建65535个线程块,每个线程块(Block)一般最多可以创建512个并行线程,即创建512个thread。
cuda在定义函数、变量的时候,前面会有个限定词:host、device、global,三者分别表示定义的函数:在cpu调用执行、在gpu调用执行、cpu调用gpu执行。
以上是关于并行计算cuda笔记的主要内容,如果未能解决你的问题,请参考以下文章