data.table进阶
Posted 学而不思则罔,思而不学则殆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了data.table进阶相关的知识,希望对你有一定的参考价值。
上一篇讲述了data.table数据分析的一些基本方法,但是最近在用作数据分析时,发现在面对一些复杂场景时,这些基本的用法已经不能满足业务需求了,所以此篇就介绍data.table更进一步的用法。
先构建一个数据集,用于测试
name1 <- c("Bob","Mary","Jane","Kim")
weight <- c(60,65,45,55)
height <- c(170,165,140,135)
birth <- c("1990-1","1980-2","1995-5","1996-4")
accept <- c("no","ok","ok","no")
library(data.table)
ndt <- data.table(name1,weight,height,accept)
设置key还有另外一个函数setkeyv
先去掉现有key
haskey(ndt) key(ndt) setkey(ndt,NULL)

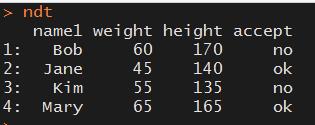
by=.EACHI参数
by=.EACHI允许按每一个已知i的子集分组,在使用by=.EACHI时需要设置键值 , 必须设置i
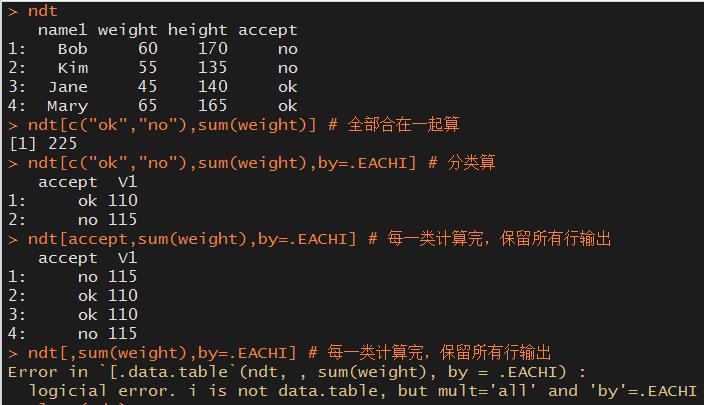
.SD参数
.SD是一个data.table,他包含了各个分组,除了by中的变量的所有元素。.SD只能在位置j中使用
SDcols
.SDcols常于.SD用在一起,他可以指定.SD中所包含的列,也就是对.SD取子集
1. 宽数据 -> 长数据 - melt() in reshape2包
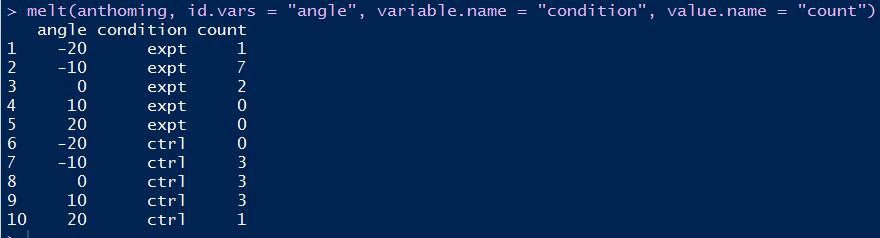
anthoming数据集如下所示:

其中expt和ctrl两列可以合并为一列。合并后的数据框相对合并前的叫长数据,而合并前的数据框相对合并后的数据叫宽数据,是不是很贴切呢?
如下R语言代码使用melt函数将上述数据集"拉长":
|
1
2
|
# melt函数:首参选定数据框,次参选定记录标识列,variable.name选定拉长后的属性名列,value.name选定拉长后的属性值列melt(anthoming, id.vars = "angle", variable.name = "condition", value.name = "count") |
拉长后的效果:
2. 长数据 -> 宽数据 - dcast() in reshape2包
plum数据集如下所示:

该数据框中length列和time列作为标识列, 如下R语言代码可将该数据框压扁:
|
1
2
|
# dcast函数:首参选定数据框,次参选定记录标识列和新的属性名列,value.var选定被拉长的属性值列dcast(plum, length + time ~ survival, value.var = "count") |
压扁后的效果:

下面介绍下data.table包的melt 和 dcast,和reshape2相比大部分参数都相同但是data.table不仅运行速度更快,而且增加了一些reshape2包没有的功能,melt和dcast函数都有改进。
# data.table包中的melt函数
melt(data, id.vars, measure.vars,
variable.name = "variable", value.name = "value",
..., na.rm = FALSE, variable.factor = TRUE,
value.factor = FALSE,
verbose = getOption("datatable.verbose"))
测试数据:

melt
同样使用了measure.vars参数来控制要被融合的列

注意到参数明明是id.vars, measure.vars,为什么我使用时就用了id和measure,这是参数的模糊匹配功能,只要提取前面的字符,不会发生歧义,就能代表这个参数,这里可以看到data.table的优势,可以模糊匹配,很方便。
如果用reshape2 包,那么只能

融合之后得到一列自动命名为variable和value,如果我想自己指定名字,就使用variable.name和value.name两个参数,在这个功能上,两个包没有区别。
cast
# data.table中的函数
dcast(data, formula, fun.aggregate = NULL, sep = "_",
..., margins = NULL, subset = NULL, fill = NULL,
drop = TRUE, value.var = guess(data),
verbose = getOption("datatable.verbose"))
两个包相同的参数margins/fill/drop/subset,相同的使用方法
- margins=T或者字符串向量,可以对得到的矩阵的每行每列在使用该函数计算
- fill当遇到缺失值时如何填充问题
- drop是否要去除掉不匹配的行,即全是NA的行
- subset提取结果的一部分进行展示
测试数据:
DT <- data.table(v1 = rep(1:2, each = 6),
v2 = rep(rep(1:3, 2), each = 2),
v3 = factor(rep(c(1,3),6),levels=1:3),
v4 = rnorm(6))
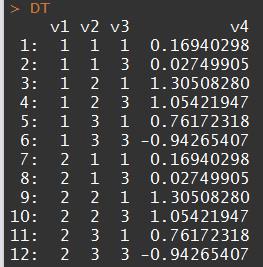



# drop 参数
# v3因子型,2没有出现过,在融合时还会与其他列进行匹配,就会出现一行全是NA的情况
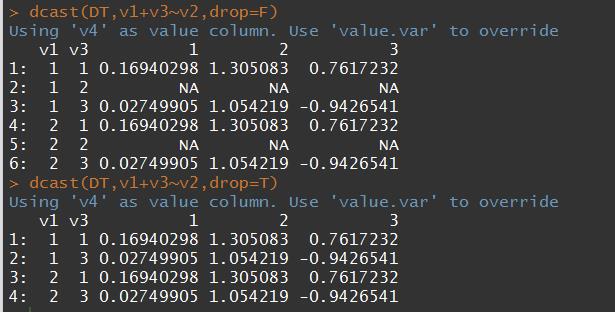
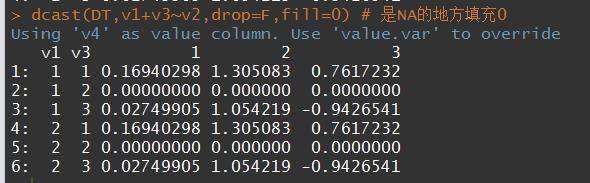

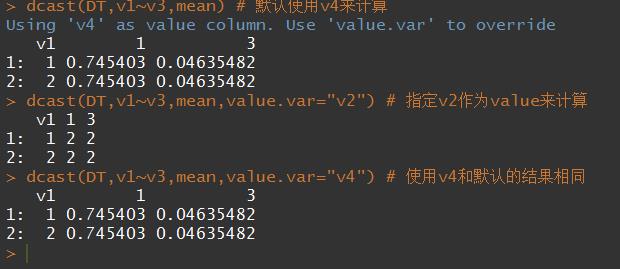
value.var参数
每次输出结果时都会打印出如今选用的作为value的列是什么,我们如果想要自己指定哪一列作为value,就要用value.var参数
data.table特有
dcast(DT,v1~v3,mean,value.var=c("v4","v2")) # v3中的元素分别和v2和v4组合,生成四列
dcast(DT,v1~v3,fun=list(sum, mean),value.var="v2") # 同时使用两种计算函数生成四列
dcast(DT,v1~v3,fun=list(sum, mean),value.var=c("v4","v2")) # 二者结合,生成8列
dcast(DT,v1~v3,fun=list(sum, mean),value.var=list("v4","v2")) # v4的使用sum,v2的使用mean,生成4列
本文部分借鉴加以实践~~~~~~~~~~~~
以上是关于data.table进阶的主要内容,如果未能解决你的问题,请参考以下文章