将一个基于磁盘的表迁移到SQL Server中的一个内存优化的表
Posted 秋天的林子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了将一个基于磁盘的表迁移到SQL Server中的一个内存优化的表相关的知识,希望对你有一定的参考价值。
本文是微软的译文,对应的原文是:https://www.red-gate.com/simple-talk/sql/database-administration/migrating-disk-based-table-memory-optimized-table-sql-server/
以前称为Hekaton的特性,现在是内存中的OLTP,可以提供非常有用的性能提升,您可以仔细地选择表来进行内存优化。如何将现有表转换为内存优化的表呢?这个过程不是很简单,但是内存中的OLTP表所带来的好处是值得您付出努力的。Alex Grinberg带着你的基本知识。
内存中的OLTP,也称为Hekaton,可以显著提高OLTP(联机事务处理)数据库应用程序的性能。它提高了吞吐量,减少了事务处理的延迟,并且可以帮助改善数据暂态的性能,比如临时表和ETL期间(提取转移和加载)。内存中的OLTP是一种内存优化的数据库引擎,它集成到SQL Server引擎中,并针对事务处理进行了优化。
为了使用内存中的OLTP,您将一个重访问的表定义为内存优化。内存优化的表是完全事务性的、持久的,并且可以使用与基于磁盘的表相同的方式访问。一个查询可以同时引用Hekaton内存优化表和基于磁盘的表。事务可以在Hekaton表和基于磁盘的表中更新数据。只引用内存优化表的存储过程可以被本机编译为机器代码,以便进行进一步的性能改进。内存中的OLTP引擎是为一个非常高的会话而设计的
注意:在SQL Server 2014中引入了内存优化的OLTP表。不幸的是,它有许多限制,因此使用起来很不实际。在SQL Server 2016中,内存优化的表得到了极大的改进,并且大大减少了约束。在SQL Server 2016版本中,只有几个限制仍然存在。本节提供的所有示例和技术只适用于SQL Server 2016版本。
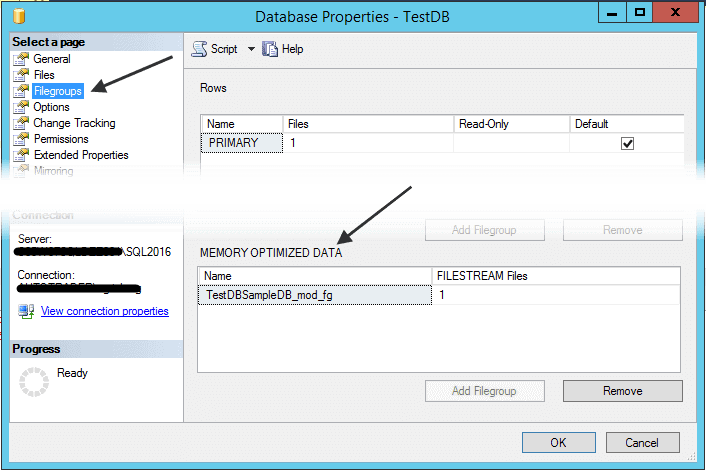
在开始使用内存优化的表之前,必须使用一个memory最优化数据filegroup来创建一个数据库。这个filegroup用于存储SQL Server需要的数据和delta文件对来恢复内存优化的表。尽管创建它们的语法与创建常规filestream filegroup的语法几乎相同,但它也必须指定包含memory优化数据选项。
创建
CREATE DATABASE [TestDB]
ON PRIMARY
( NAME = N‘TestDB_data‘, FILENAME = N‘C:\SQL2016\TestDB_data.mdf‘),
FILEGROUP [TestDBSampleDB_mod_fg] CONTAINS MEMORY_OPTIMIZED_DATA DEFAULT
( NAME = N‘TestDB_mod_dir‘, FILENAME = N‘C:\SQL2016\TestDB_mod_dir‘ , MAXSIZE = UNLIMITED)
LOG ON
( NAME = N‘TestDBSampleDB_log‘, FILENAME = N‘C:\SQL2016\TestDB_log.ldf‘ )
如果希望为现有数据库启用memory最优化数据选项,则需要使用memory优化数据选项创建一个filegroup,然后将文件添加到filegoup中。
MEMORY_OPTIMIZED property –当访问内存优化的表时,不需要从磁盘读取这些页面。所有的数据都存储在内存中。DURABILITY property –内存优化的表可以是持久的(schemaanddata),也可以是非持久的(模式)。默认情况下,这些表是持久的(schemaanddata),这些持久表也满足了所有其他事务需求;它们是原子的、孤立的、一致的。一组检查点文件(数据和delta文件对),这些文件只用于恢复目的,是使用驻留在内存优化的文件组中的操作系统文件创建的,这些文件组跟踪对持久表中的数据的更改。这些检查点文件只是应用程序。非持久的,没有记录的,只使用一个选项模式。正如该选项所指出的,表模式将是持久的,即使数据不是。在事务处理过程中,这些表不需要任何IO操作,也不需要对这些表的检查点文件进行任何操作。只有在SQL Server运行时,数据才可以在内存中使用。
Indexes –没有在内存优化的表上实现集群索引。索引不是作为传统的b树存储的。内存优化的表支持散列索引,存储为哈希表,其中有链表,将散列的所有行连接到相同的值和“范围”索引,这些索引是使用特殊的bw树存储的。使用bw-tree的范围索引可以用来快速查找范围谓词中的符合条件的行,就像传统的b-树一样,但是它是用乐观的并发控制设计的,没有锁定或锁定。datetimeoffset, geography, geometry, hierarchyid, rowversion, xml, sql_variant, all User-Defined Types and all legacy LOB data types (including text, ntext, and image)bit, tinyint, smallint, int, bigint. Numeric and decimalmoneyandsmallmoneyfloatandreal- date/time types:
datetime,smalldatetime,datetime2,dateandtime char(n),varchar(n),nchar(n),nvarchar(n),sysname,varchar(MAX) andnvarchar(MAX)binary(n),varbinary(n) andvarbinary(MAX)- Uniqueidentifier
创建内存优化的表的语法与创建基于磁盘的表的语法几乎完全相同,有一些限制,以及一些必要的扩展。其中的一些区别是:
要设置 MEMORY_OPTIMIZED = ON
The DURABILITY property is set to SCHEMA_AND_DATA or SCHEMA_ONLY (SCHEMA_AND_DATA is default)
The memory-optimized table must have a PRIMARY KEY index. If HASH index is selected for the primary key, then BUCKET_COUNT must be specified.
在内存优化表中只允许包括主键在内的8个索引
IDENTITY properties have to be set as seed = 1 and increment = 1 only.
在内存优化的表中不允许计算列(Computed Columns)
不加选择地创建内存优化的表是一个坏主意。同时,对于OS和其他SQL服务器进程也需要内存,将尽可能多的表迁移到内存优化的表中并不是一个好主意。因为内存优化的表是用开放式并发控制设计的,没有锁定或被锁,选择转换的最佳表应该是具有“锁定和锁定配置文件”(被检测为会话“拦截器”的表)的表,其中包括最可写的表(插入、更新和删除)和最可读的表,然而,这个列表对于迁移来说还不是很完整。但是,不应该迁移的表是静态元数据表;违反了内存优化表的限制的表;表的行数更少。
在SQL Server 2016中,可以使用SQL Server
PowerShell生成一个迁移清单。在对象资源管理器中,右键单击一个数据库,然后单击Start PowerShell;验证以下提示出现,执行以下代码:PS SQLSERVER:\SQL\{Instance Name}\DEFAULT\Databases\{DB Name}>
输入以下命令(用您的目标文件夹路径替换C:Temp。如果您喜欢使用更通用的方法$Env:Temp或$Env:报告输出的路径,然后验证这些命令的PowerShell路径。只需运行$Env:Temp或$Env:PowerShell命令窗口中的路径,您的本地路径将被返回)。清单PowerShell命令示例:
Save-SqlMigrationReport –FolderPath “C:\Temp”
注意:如果您需要在单个表上运行迁移报告,那么就展开数据库节点,展开表节点,右键单击表,然后从弹出菜单中选择Start PowerShell。
文件夹路径将被创建,以防它不存在。迁移检查表报告将为数据库中的所有表和存储过程生成,并且报告将出现在FolderPath指定的位置。因此,报告的文件夹路径将被指定为PowerShell脚本中的FolderPath,以及检查清单执行的数据库名称。在这个例子中,它是C:\Temp\Northwind.
检查表报告可以指出,已经超过了内存优化表的一个或多个数据类型限制。但是,这并不意味着不能将表迁移到内存优化的表中。报告指出每一列是否满足了成功的标准,如果没有,则提示如果表对迁移很重要,那么如何纠正问题。例如,一个数据库有一个表testdisk。为了演示的目的,我们将在稍后的报告中看到这个表,其中包含了大量的迁移违规行为。
- XMLData column have XML data type
- SumOrder is Computed Column
- Description column is SPARSE
- ID have IDENTITY seed value 10000
根据这份报告,所有的违规行为都必须得到纠正,或者不能迁移表格。让我们修正所有这些违规行为:
XMLData列将被转换为nv(MAX)数据类型;这就是XML的本质。但是,当应用程序或数据库没有实现UNICODE时,可以考虑VARCHAR(MAX)数据类型。
SumOrder是计算的列,其中的值通过公式ProductID列进行计算,并使用OrderQty列(公式ProductID+OrderQty仅为演示目的而创建)。ProductID和OrderQty列都有int数据类型。因此,SumOrder列从ProductID和OrderQty列中继承了int数据类型(如何纠正计算的列问题,将在“修复计算列问题”小节中解释)。
Description列,为了纠正这个问题,只需删除稀疏选项
ID column IDENTITY:将对应的seed value设置成1
在实现了所有的更正之后,testmemory内存优化表的DDL脚本将会是:
GB的内存;核聚变(固态)驱动器。但是,内存优化的表执行的速度是磁盘表的两倍多。
以上是关于将一个基于磁盘的表迁移到SQL Server中的一个内存优化的表的主要内容,如果未能解决你的问题,请参考以下文章
如何使用 SSMA(用于访问 SQL Server)将具有不同列的表迁移到现有表中?
sql语句将Excel中的一列批量更新到sql server中的一列中?
sql server 临时库文件太大 迁移tempdb数据库