一脸懵逼学习Hive的使用以及常用语法
Posted --->别先生<---
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一脸懵逼学习Hive的使用以及常用语法相关的知识,希望对你有一定的参考价值。
Hive官网(HQL)语法手册(英文版):https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Hive的数据存储
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
(1):db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
(2):table:在hdfs中表现所属db目录下一个文件夹
(3):external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
(4): partition:在hdfs中表现为table目录下的子目录
(5):bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
hive创建数据库操作:
hive提供database的定义,database的主要作用是提供数据分割的作用,方便数据关闭,命令如下所示: #创建: create (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES] (property_name=value,name=value...) #显示描述信息: describe DATABASE|SCHEMA [extended] database_name。 #删除: DROP DATABASE|SHCEMA [IF EXISTS] database_Name [RESTRICT|CASCADE] #使用: user database_name;
1:Hive创建数据表:
(1)创建表(DDL操作)
建表语法如下所示:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)] ----指定表的名称和表的具体列信息。
[COMMENT table_comment] ---表的描述信息。
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] ---表的分区信息。
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] ---表的桶信息。
[ROW FORMAT row_format] ---表的数据分割信息,格式化信息。
[STORED AS file_format] ---表数据的存储序列化信息。
[LOCATION hdfs_path] ---数据存储的文件夹地址信息。
创建数据表解释说明:
1、 CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。hive中的表可以分为内部表(托管表)和外部表,区别在于,外部表的数据不是有hive进行管理的,也就是说当删除外部表的时候,外部表的数据不会从hdfs中删除。而内部表是由hive进行管理的,在删除表的时候,数据也会删除。一般情况下,我们在创建外部表的时候会将表数据的存储路径定义在hive的数据仓库路径之外。hive创建表主要有三种方式,第一种直接使用create table命令,第二种使用create table ... as select...(会产生数据)。第三种使用create table tablename like exist_tablename命令。
2、 EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
3、 LIKE 允许用户复制现有的表结构,但是不复制数据。
4、 ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive通过 SerDe 确定表的具体的列的数据。
5、 STORED AS
SEQUENCEFILE | TEXTFILE | RCFILE
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
6、CLUSTERED BY
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
7、create table命令介绍2
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name] table_name LIKE existing_table_orview_name ---指定要创建的表和已经存在的表或者视图的名称。
[LOCATION hdfs_path] ---数据文件存储的hdfs文件地址信息。
8、CREATE [EXTERNAL] TABLE [IF NOT EXISTS]
[db_Name] table_name ---指定要创建的表名称
...指定partition&bucket等信息,指定数据分割符号。
[AS select_statement] ---导入的数据
CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT \'IP Address of the User\') COMMENT \'This is the page view table\' PARTITIONED BY(dt STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY \'\\t\' STORED AS SEQUENCEFILE;
创建数据表解释如下所示:
# page_view是数据表的名称,注意hive的数据类型和java的数据类型类似,和mysql和oracle等数据库的字段类型不一致。 CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT \'IP Address of the User\') #COMMENT描述,可有可无的。 COMMENT \'This is the page view table\' # PARTITIONED BY指定表的分区,可以先不管。 PARTITIONED BY(dt STRING, country STRING) # ROW FORMAT DELIMITED代表一行是一条记录,是自己创建的全部字段和文件的字段对应,一行对应一条记录。 ROW FORMAT DELIMITED #FIELDS TERMINATED BY \'\\001\'代表一行记录中的各个字段以什么隔开,方便创建的数据字段对应文件的一条记录的字段。 FIELDS TERMINATED BY \'\\001\' # STORED AS SEQUENCEFILE;代表对应的文件类型。最常见的是SEQUENCEFILE(以键值对类型格式存储的)类型。TEXTFILE类型。 STORED AS SEQUENCEFILE;
创建如下所示,之前创建的不符合规范,删除了,然后创建一个标准的,查看一下,最后一个指定类型的,可以不指定,默认就是普通的文本类型的:

Hive将创建的数据类型写到元数据库,可以使用本地Navicat连接虚拟机的mysql查看数据;可是呢,出现下面的情况,百度呗,解决方法一大推,我贴一下子的解决方法:
错误(贴出来,方便被搜索到,哈哈哈哈。):1130 -Host \'192.168.3.132\' is not allowed to connect to this MySQL server
百度方法很多,但是不是每一个都适合你,我就百度了很多没解决我的问题,所以我还是贴一下我的解决方法:
如何开启MySQL的远程帐号(Navicat远程连接自己的mysql数据库):
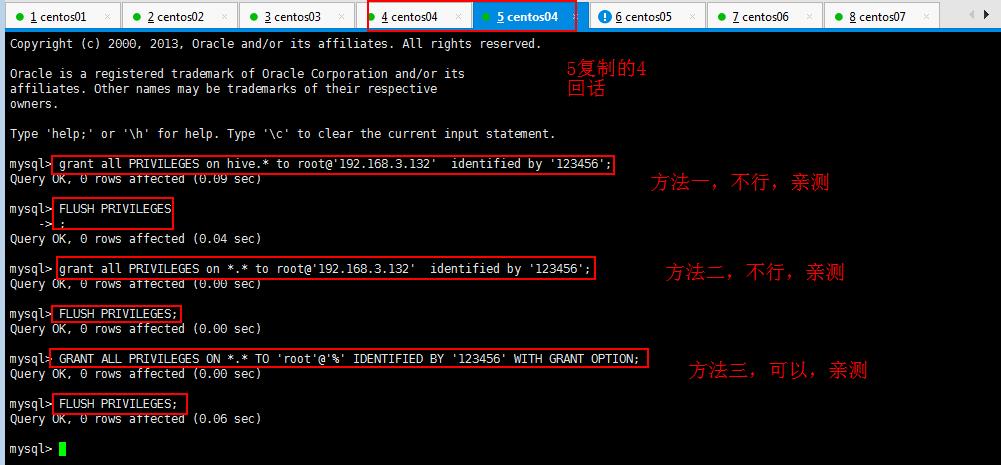
mysql> GRANT ALL PRIVILEGES ON *.* TO \'root\'@\'%\' IDENTIFIED BY \'123456\' WITH GRANT OPTION;
再执行下面的语句,方可立即生效(修改的权限即时生效)。
mysql> FLUSH PRIVILEGES;
上面的语句表示将 所有的 数据库的所有权限授权给 root 这个用户,允许 root 用户在 192.168.3.132 这个 IP 进行远程登陆,并设置 root 用户的密码为 123456 。
下面逐一分析所有的参数:
(1)all PRIVILEGES 表示赋予所有的权限给指定用户,这里也可以替换为赋予某一具体的权限,例如select,insert,update,delete,create,drop 等,具体权限间用“,”半角逗号分隔。
(2)*.* 表示上面的权限是针对于哪个表的,*指的是所有数据库,后面的 * 表示对于所有的表,由此可以推理出:对于全部数据库的全部表授权为“*.*”,对于某一数据库的全部表授权为“数据库名.*”,对于某一数据库的某一表授权为“数据库名.表名”。
(3)root 表示你要给哪个用户授权,这个用户可以是存在的用户,也可以是不存在的用户。
(4)192.168.3.132 表示允许远程连接的 IP 地址,如果想不限制链接的 IP 则设置为“%”即可。
(5)123456 为用户的密码。
可以使用Navicat工具查看一下自己的创建的数据表(tabs是保存了创建了那些表名):

可以看看自己创建了那些列(在COLUMNS_V2数据表里面):

可以看到有DBS里面保存了哪些数据库:

DBS数据表的DB_LOCATION_URI字段保存了路径:hdfs://ns1/user/hive/warehouse
可以去hdfs里看一眼,里面确实保存着数据库(突然发现有点意思了,只可意会,言传不了了,哈哈哈哈~~~~):
2:创建好数据表,了解了一些基本知识以后,开始插入数据,了解更多的知识:
//create & load(创建好数据表以后导入数据的操作如):
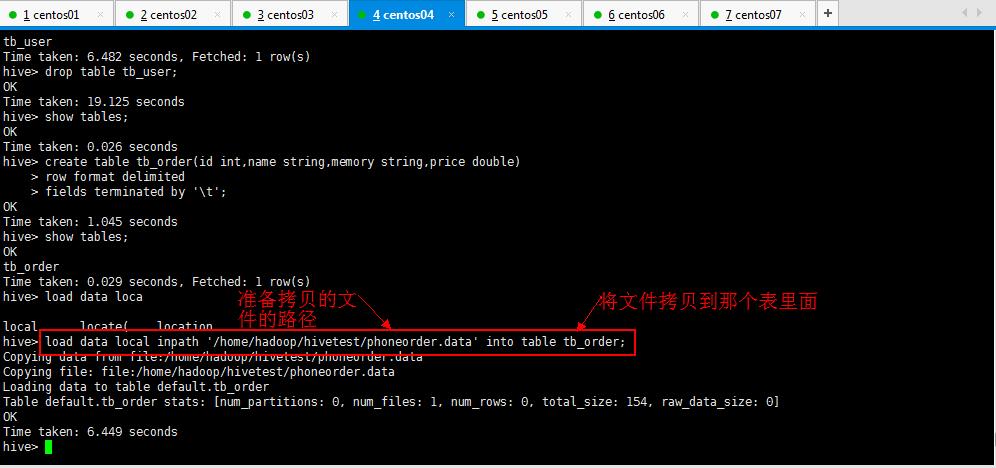
hive> create table tb_order(id int,name string,memory string,price double)
> row format delimited
> fields terminated by \'\\t\';
//从本地导入数据到hive的表中(实质就是将文件上传到hdfs中hive管理目录下)
load data local inpath \'/home/hadoop/ip.txt\' into table 要导入的表名称;
//从hdfs上导入数据到hive表中(实质就是将文件从原始目录移动到hive管理的目录下)
load data inpath \'hdfs://ns1/aa/bb/data.log\' into table 要导入的表名称;
//使用select语句来批量插入数据
insert overwrite table tab_ip_seq select * from 要导入的表名称;
自己造一组数据,保存一下,如我的,在/home/hadoop/目录下面phoneorder.data,内容如下所示:
[root@slaver3 hadoop]# vim phoneorder.data
想了一下,由于学习hive,会有很多测试数据,自己创建一个hivetest目录,专一用于存放hive测试数据,如下所示:

10010 小米1 2G 1999 10011 小米2 4G 1999 10012 小米3 4G 1999 10013 小米4 6G 2999 10014 小米5 6G 2999 10015 小米6 8G 2999 10016 小米7 8G 3999
然后开始导入数据(或者使用hadoop的命令将正确格式数据上传到对应的目录),如下所示:
hive> load data local inpath \'/home/hadoop/hivetest/phoneorder.data\' into table tb_order;
或者[root@slaver3 hivetest]# hadoop fs -put phoneorder2.data /user/hive/warehouse/tb_order
可以去hdfs看到数据已经上传成功了,如下所示,可以看到一些简单信息:

下面可以使用hive的查询语句进行查询操作;
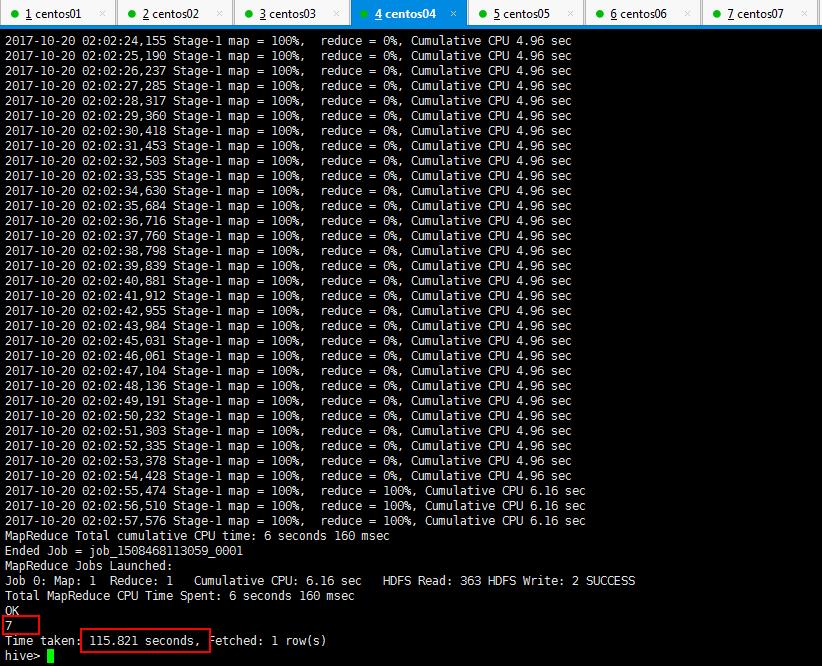
3:Hive的查询语句进行查询操作,统计多少条记录的时候发现很慢很慢,那是启动集群的时候就很慢,最后可以看到一共7条记录,用了一百多秒:

4:external外部表,优点,做数据分析的时候,有的数据是业务系统产生的,或者读或者写这个文件,如果的默认的路径,即在配置文件里面写好了,如果做分析的时候数据表导数据,如果将数据表移动了,,业务系统再读这个文件就不存在了,这个时候使用外部表,外部表不要求数据非到默认的路径下面去,数据可以摆放到任意的hdfs路径下面;
创建外部表的语法:
//external外部表 CREATE EXTERNAL TABLE tab_ip_ext(id int, name string, ip STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY \',\' STORED AS TEXTFILE LOCATION \'/external/user\';
//external外部表 //使用关键字EXTERNAL CREATE EXTERNAL TABLE 数据表名称(id int, name string, ip STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY \'\\t\' STORED AS TEXTFILE #location指定所在的位置:切记,重点。 LOCATION \'/external/user\';
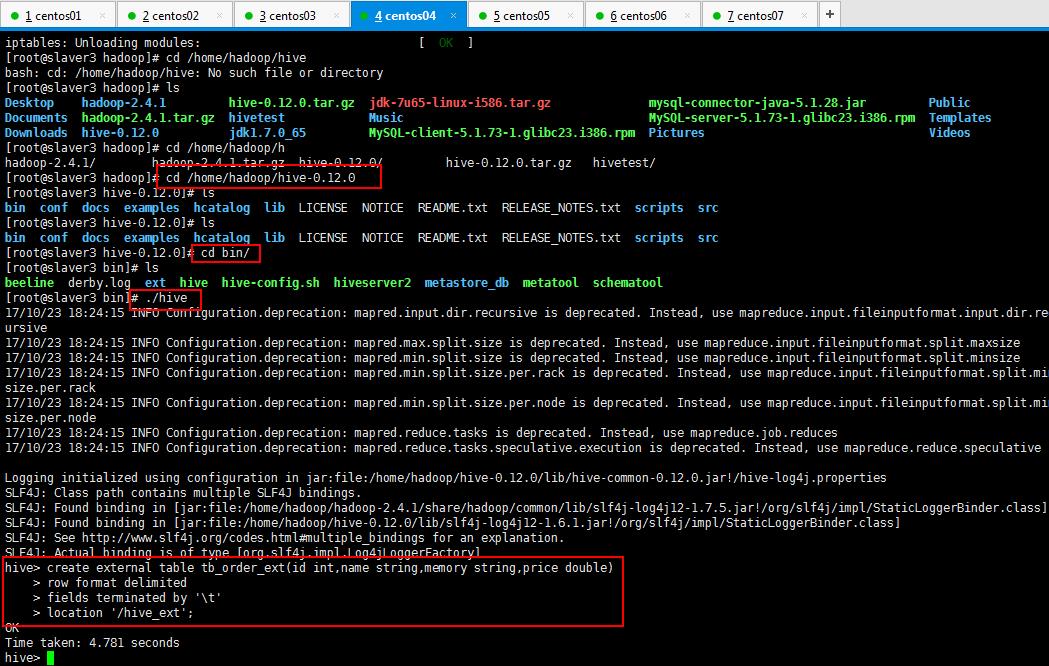
然后自己创建一个文件在hdfs,上传一个文件,然后创建一个扩展表和这个hdfs的文件关联起来:
[root@slaver3 hadoop]# cd /home/hadoop/hivetest/
[root@slaver3 hivetest]# cp phoneorder.data phoneorder4.data
[root@slaver3 hivetest]# hadoop fs -mkdir /hive_ext
[root@slaver3 hivetest]# hadoop fs -put phoneorder4.data /hive_ext
然后创建一个扩展表和这个hdfs的文件关联起来:
hive> create external table tb_order_ext(id int,name string,memory string,price double) > row format delimited > fields terminated by \'\\t\' > location \'/hive_ext\';
具体操作如下所示:
查看一下是否存在数据:

可以查看扩展数据表的数据表结构,如下所示:
1 hive> desc extended tb_log; 2 OK 3 logid int 4 logname string 5 6 Detailed Table Information Table(tableName:tb_log, dbName:test, owner:root, createTime:1512892171, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:logid, type:int, comment:null), FieldSchema(name:logname, type:string, comment:null)], location:hdfs://master:9000/tb_log_file, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format=,, field.delim=,}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{EXTERNAL=TRUE, transient_lastDdlTime=1512892171}, viewOriginalText:null, viewExpandedText:null, tableType:EXTERNAL_TABLE) 7 Time taken: 0.121 seconds, Fetched: 4 row(s) 8 hive>
格式化查看扩展表的数据表结构:
1 hive> desc formatted tb_log; 2 OK 3 # col_name data_type comment 4 5 logid int 6 logname string 7 8 # Detailed Table Information 9 Database: test 10 Owner: root 11 CreateTime: Sat Dec 09 23:49:31 PST 2017 12 LastAccessTime: UNKNOWN 13 Protect Mode: None 14 Retention: 0 15 Location: hdfs://master:9000/tb_log_file 16 Table Type: EXTERNAL_TABLE 17 Table Parameters: 18 EXTERNAL TRUE 19 transient_lastDdlTime 1512892171 20 21 # Storage Information 22 SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe 23 InputFormat: org.apache.hadoop.mapred.TextInputFormat 24 OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat 25 Compressed: No 26 Num Buckets: -1 27 Bucket Columns: [] 28 Sort Columns: [] 29 Storage Desc Params: 30 field.delim , 31 serialization.format , 32 Time taken: 0.577 seconds, Fetched: 29 row(s) 33 hive>
5:创建分区表(分区的好处是可以帮助你统计的时候少统计一些数据,加速数据统计):
hive> create table tb_part(sNo int,sName string,sAge int,sDept string) > partition //拿不准的单词,可以tab一下进行提示,并不会影响你创建表;谢谢 partition partitioned partitions > partitioned by (part string) > row format delimited > fields terminated by \',\' > stored as textfile; OK Time taken: 0.351 seconds
并且将本地的数据上传到hive上面:
1 hive> load data local inpath \'/home/hadoop/data_hadoop/tb_part\' overwrite into table tb_part partition (part=\'20171210\'); 2 Loading data to table test.tb_part partition (part=20171210) 3 Partition test.tb_part{part=20171210} stats: [numFiles=1, numRows=0, totalSize=43, rawDataSize=0] 4 OK 5 Time taken: 2.984 seconds 6 hive> load data local inpath \'/home/hadoop/data_hadoop/tb_part\' overwrite into table tb_part partition (part=\'20171211\'); 7 Loading data to table test.tb_part partition (part=20171211) 8 Partition test.tb_part{part=20171211} stats: [numFiles=1, numRows=0, totalSize=43, rawDataSize=0] 9 OK 10 Time taken: 0.566 seconds 11 hive> show par 12 parse_url( parse_url_tuple( partition partitioned partitions 13 hive> show partition 14 partition partitioned partitions 15 hive> show partitions tb_part; 16 OK 17 part=20171210 18 part=20171211 19 Time taken: 0.119 seconds, Fetched: 2 row(s) 20 hive>
6:创建带桶的数据表,然后将本地创建好测试数据上传到hive上面:
#设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
1 hive> create table if not exists tb_stud(id int,name string,age int) 2 > partitioned by(clus string) 3 > clustered by(id) sorted by(age) into 2 buckets #分桶,根据id进行分桶,分成2个桶。 4 > row format delimited 5 > fields terminated by \',\'; 6 OK 7 Time taken: 0.194 seconds 8 hive> load data local inpath \'/home/hadoop/data_hadoop/tb_clustered\' overwrite into table tb_stud partition (clus=\'20171211\'); 9 Loading data to table test.tb_stud partition (clus=20171211) 10 Partition test.tb_stud{clus=20171211} stats: [numFiles=1, numRows=0, totalSize=38, rawDataSize=0] 11 OK 12 Time taken: 0.594 seconds 13 hive>
7:修改表,增加/删除分区
语法结构
ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION \'location1\' ] partition_spec [ LOCATION \'location2\' ] ...
partition_spec:
: PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
ALTER TABLE table_name DROP partition_spec, partition_spec,...
具体实例如下所示:
alter table student_p add partition(part=\'a\') partition(part=\'b\');
修改分区和删除分区的操作:
hive> alter table tb_stud add partition(clus=\'20171215\') location \'/user/hive/warehouse/test.db\' partition(clus=\'20171216\'); OK Time taken: 1.289 seconds hive> alter table tb_stud add partition partition partitioned partitions hive> alter table tb_stud add partition(clus=\'20171217\'); OK Time taken: 0.097 seconds hive> dfs -ls /user/hive/warehouse/test.db > ; Found 4 items drwxr-xr-x - root supergroup 0 2017-12-09 23:32 /user/hive/warehouse/test.db/tb_log drwxr-xr-x - root supergroup 0 2017-12-10 00:14 /user/hive/warehouse/test.db/tb_part drwxr-xr-x - root supergroup 0 2017-12-10 00:43 /user/hive/warehouse/test.db/tb_stud drwxr-xr-x - root supergroup 0 2017-12-09 21:28 /user/hive/warehouse/test.db/tb_user hive> show partitions tb_stud; OK clus=20171211 clus=20171215 clus=20171216 clus=20171217 Time taken: 0.119 seconds, Fetched: 4 row(s) hive> alter table tb_stud drop partition partition partitioned partitions hive> alter table tb_stud drop partition(clus=\'20171217\'); Dropped the partition clus=20171217 OK Time taken: 1.433 seconds hive> show partitions tb_stud; OK clus=20171211 clus=20171215 clus=20171216 Time taken: 0.092 seconds, Fetched: 3 row(s) hive> alter table tb_stud drop partition(clus=\'20171215\'),partition(clus=\'20171216\'); Dropped the partition clus=20171215 Dropped the partition clus=20171216 OK Time taken: 0.271 seconds hive> show partitions tb_stud; OK clus=20171211 Time taken: 0.094 seconds, Fetched: 1 row(s) hive>
8:重命名表:
语法结构
ALTER TABLE table_name RENAME TO new_table_name
具体实例 ,如下所示:
1 hive> show tables; 2 OK 3 tb_log 4 tb_part 5 tb_stud 6 tb_user 7 Time taken: 0.026 seconds, Fetched: 4 row(s) 8 hive> alter table tb_user rename to tb_user_copy; 9 OK 10 Time taken: 0.19 seconds 11 hive> show tables; 12 OK 13 tb_log 14 tb_part 15 tb_stud 16 tb_user_copy 17 Time taken: 0.05 seconds, Fetched: 4 row(s) 18 hive>
9:增加/更新列
语法结构
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
具体实例如下所示:
1 hive> desc tb_user; 2 OK 3 id int 4 name string 5 Time taken: 0.148 seconds, Fetched: 2 row(s) 6 hive> alter table tb_user add columns(age int); 7 OK 8 Time taken: 0.238 seconds 9 hive> desc tb_user; 10 OK 11 id int 12 name string 13 age int 14 Time taken: 0.088 seconds, Fetched: 3 row(s) 15 hive> alter table tb_user replace columns(id int,name string,birthday string); 16 OK 17 Time taken: 0.132 seconds 18 hive> desc tb_user; 19 OK 20 id int 21 name string 22 birthday string 23 Time taken: 0.083 seconds, Fetched: 3 row(s) 24 hive>
10:Load,操作只是单纯的复制/移动操作,DML操作
语法结构
LOAD DATA [LOCAL] INPATH \'filepath\' [OVERWRITE] INTO
TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
说明:
1、Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。
2、filepath:
相对路径,例如:project/data1
绝对路径,例如:/user/hive/project/data1
包含模式的完整 URI,列如:
hdfs://namenode:9000/user/hive/project/data1
3、LOCAL关键字
如果指定了 LOCAL, load 命令会去查找本地文件系统中的 filepath。
如果没有指定 LOCAL 关键字,则根据inpath中的uri[如果指定了 LOCAL,那么:
load 命令会去查找本地文件系统中的 filepath。如果发现是相对路径,则路径会被解释为相对于当前用户的当前路径。
load 命令会将 filepath中的文件复制到目标文件系统中。目标文件系统由表的位置属性决定。被复制的数据文件移动到表的数据对应的位置。
如果没有指定 LOCAL 关键字,如果 filepath 指向的是一个完整的 URI,hive 会直接使用这个 URI。 否则:如果没有指定 schema 或者 authority,Hive 会使用在 hadoop 配置文件中定义的 schema 和 authority,fs.default.name 指定了 Namenode 的 URI。
如果路径不是绝对的,Hive 相对于/user/进行解释。
Hive 会将 filepath 中指定的文件内容移动到 table (或者 partition)所指定的路径中。]查找文件
4、OVERWRITE 关键字
如果使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。
11:Hive的insert操作:
Insert
将查询结果插入Hive表
语法结构
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement
Multiple inserts:
FROM from_statement
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1
[INSERT OVERWRITE TABLE tablename2 [PARTITION ...] select_statement2] ...
Dynamic partition inserts:
INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement
1 <!--基本模式插入。--> 2 hive> load data local inpath \'/home/hadoop/data_hadoop/tb_stud\' overwrite into table tb_stud partition (clus=\'20171211\'); 3 Loading data to table test.tb_stud partition (clus=20171211) 4 Partition test.tb_stud{clus=20171211} stats: [numFiles=1, numRows=0, totalSize=43, rawDataSize=0] 5 OK 6 Time taken: 4.336 seconds 7 hive> select * from tb_stud where clus=\'20171211\'; 8 OK 9 1 张三 NULL 20171211 10 2 lisi NULL 20171211 11 3 wangwu NULL 20171211 12 4 zhaoliu NULL 20171211 13 5 libai NULL 20171211 14 Time taken: 0.258 seconds, Fetched: 5 row(s) 15 hive> insert overwrite table tb_stud partition(clus=\'20171218\') 16 > select id,name,age from tb_stud where clus=\'20171211\'; 17 Query ID = root_20171210012734_721f76d9-f670-42ad-bf68-bfb94baf5cda 18 Total jobs = 3 19 Launching Job 1 out of 3 20 Number of reduce tasks is set to 0 since there\'s no reduce operator 21 Starting Job = job_1512874725514_0005, Tracking URL = http://master:8088/proxy/application_1512874725514_0005/ 22 Kill Command = /home/hadoop/soft/hadoop-2.6.4/bin/hadoop job -kill job_1512874725514_0005 23 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 24 2017-12-10 01:28:00,125 Stage-1 map = 0%, reduce = 0% 一脸懵逼学习Hive的安装