Hbase与传统关系型数据库对比
Posted 南湖公明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase与传统关系型数据库对比相关的知识,希望对你有一定的参考价值。
在说HBase之前,我想再唠叨几句。做互联网应用的哥们儿应该都清楚,互联网应用这东西,你没办法预测你的系统什么时候会被多少人访问,你面临的用户到底有多少,说不定今天你的用户还少,明天系统用户就变多了,结果您的系统应付不过来了了,不干了,这岂不是咱哥几个的悲哀,说时髦点就叫“杯具啊”。
其实说白了,这些就是事先没有认清楚互联网应用什么才是最重要的。从系统架构的角度来说,互联网应用更加看重系统性能以及伸缩性,而传统企业级应用都是比较看重数据完整性和数据安全性。那么我们就来说说互联网应用伸缩性这事儿.对于伸缩性这事儿,哥们儿我也写了几篇博文,想看的兄弟可以参考我以前的博文,对于web server,app server的伸缩性,我在这里先不说了,因为这部分的伸缩性相对来说比较容易一点,我主要来回顾一些一个慢慢变大的互联网应用如何应对数据库这一层的伸缩。
首先刚开始,人不多,压力也不大,搞一台数据库服务器就搞定了,此时所有的东东都塞进一个Server里,包括web server,app server,db server,但是随着人越来越多,系统压力越来越多,这个时候可能你把web server,app server和db server分离了,好歹这样可以应付一阵子,但是随着用户量的不断增加,你会发现,数据库这哥们不行了,速度老慢了,有时候还会宕掉,所以这个时候,你得给数据库这哥们找几个伴,这个时候Master-Salve就出现了,这个时候有一个Master Server专门负责接收写操作,另外的几个Salve Server专门进行读取,这样Master这哥们终于不抱怨了,总算读写分离了,压力总算轻点了,这个时候其实主要是对读取操作进行了水平扩张,通过增加多个Salve来克服查询时CPU瓶颈。一般这样下来,你的系统可以应付一定的压力,但是随着用户数量的增多,压力的不断增加,你会发现Master server这哥们的写压力还是变的太大,没办法,这个时候怎么办呢?你就得切分啊,俗话说“只有切分了,才会有伸缩性嘛”,所以啊,这个时候只能分库了,这也是我们常说的数据库“垂直切分”,比如将一些不关联的数据存放到不同的库中,分开部署,这样终于可以带走一部分的读取和写入压力了,Master又可以轻松一点了,但是随着数据的不断增多,你的数据库表中的数据又变的非常的大,这样查询效率非常低,这个时候就需要进行“水平分区”了,比如通过将User表中的数据按照10W来划分,这样每张表不会超过10W了。
综上所述,一般一个流行的web站点都会经历一个从单台DB,到主从复制,到垂直分区再到水平分区的痛苦的过程。其实数据库切分这事儿,看起来原理貌似很简单,如果真正做起来,我想凡是sharding过数据库的哥们儿都深受其苦啊。对于数据库伸缩的文章,哥们儿可以看看后面的参考资料介绍。
好了,从上面的那一堆废话中,我们也发现数据库存储水平扩张scale out是多么痛苦的一件事情,不过幸好技术在进步,业界的其它弟兄也在努力,09年这一年出现了非常多的NoSQL数据库,更准确的应该说是No relation数据库,这些数据库多数都会对非结构化的数据提供透明的水平扩张能力,大大减轻了哥们儿设计时候的压力。下面我就拿Hbase这分布式列存储系统来说说。
一 Hbase是个啥东东?
在说Hase是个啥家伙之前,首先我们来看看两个概念,面向行存储和面向列存储。面向行存储,我相信大伙儿应该都清楚,我们熟悉的RDBMS就是此种类型的,面向行存储的数据库主要适合于事务性要求严格场合,或者说面向行存储的存储系统适合OLTP,但是根据CAP理论,传统的RDBMS,为了实现强一致性,通过严格的ACID事务来进行同步,这就造成了系统的可用性和伸缩性方面大大折扣,而目前的很多NoSQL产品,包括Hbase,它们都是一种最终一致性的系统,它们为了高的可用性牺牲了一部分的一致性。好像,我上面说了面向列存储,那么到底什么是面向列存储呢?Hbase,Casandra,Bigtable都属于面向列存储的分布式存储系统。看到这里,如果您不明白Hbase是个啥东东,不要紧,我再总结一下下:
Hbase是一个面向列存储的分布式存储系统,它的优点在于可以实现高性能的并发读写操作,同时Hbase还会对数据进行透明的切分,这样就使得存储本身具有了水平伸缩性。
二 Hbase数据模型
HBase,Cassandra的数据模型非常类似,他们的思想都是来源于Google的Bigtable,因此这三者的数据模型非常类似,唯一不同的就是Cassandra具有Super cloumn family的概念,而Hbase目前我没发现。好了,废话少说,我们来看看Hbase的数据模型到底是个啥东东。
在Hbase里面有以下两个主要的概念,Row key,Column Family,我们首先来看看Column family,Column family中文又名“列族”,Column family是在系统启动之前预先定义好的,每一个Column Family都可以根据“限定符”有多个column.下面我们来举个例子就会非常的清晰了。
假如系统中有一个User表,如果按照传统的RDBMS的话,User表中的列是固定的,比如schema 定义了name,age,sex等属性,User的属性是不能动态增加的。但是如果采用列存储系统,比如Hbase,那么我们可以定义User表,然后定义info 列族,User的数据可以分为:info:name = zhangsan,info:age=30,info:sex=male等,如果后来你又想增加另外的属性,这样很方便只需要info:newProperty就可以了。
也许前面的这个例子还不够清晰,我们再举个例子来解释一下,熟悉SNS的朋友,应该都知道有好友Feed,一般设计Feed,我们都是按照“某人在某时做了标题为某某的事情”,但是同时一般我们也会预留一下关键字,比如有时候feed也许需要url,feed需要image属性等,这样来说,feed本身的属性是不确定的,因此如果采用传统的关系数据库将非常麻烦,况且关系数据库会造成一些为null的单元浪费,而列存储就不会出现这个问题,在Hbase里,如果每一个column 单元没有值,那么是占用空间的。下面我们通过两张图来形象的表示这种关系:![]()
上图是传统的RDBMS设计的Feed表,我们可以看出feed有多少列是固定的,不能增加,并且为null的列浪费了空间。但是我们再看看下图,下图为Hbase,Cassandra,Bigtable的数据模型图,从下图可以看出,Feed表的列可以动态的增加,并且为空的列是不存储的,这就大大节约了空间,关键是Feed这东西随着系统的运行,各种各样的Feed会出现,我们事先没办法预测有多少种Feed,那么我们也就没有办法确定Feed表有多少列,因此Hbase,Cassandra,Bigtable的基于列存储的数据模型就非常适合此场景。说到这里,采用Hbase的这种方式,还有一个非常重要的好处就是Feed会自动切分,当Feed表中的数据超过某一个阀值以后,Hbase会自动为我们切分数据,这样的话,查询就具有了伸缩性,而再加上Hbase的弱事务性的特性,对Hbase的写入操作也将变得非常快。
上面说了Column family,那么我之前说的Row key是啥东东,其实你可以理解row key为RDBMS中的某一个行的主键,但是因为Hbase不支持条件查询以及Order by等查询,因此Row key的设计就要根据你系统的查询需求来设计了额。我还拿刚才那个Feed的列子来说,我们一般是查询某个人最新的一些Feed,因此我们Feed的Row key可以有以下三个部分构成<userId><timestamp><feedId>,这样以来当我们要查询某个人的最进的Feed就可以指定Start Rowkey为<userId><0><0>,End Rowkey为<userId><Long.MAX_VALUE><Long.MAX_VALUE>来查询了,同时因为Hbase中的记录是按照rowkey来排序的,这样就使得查询变得非常快。
三 Hbase的优缺点
1 列的可以动态增加,并且列为空就不存储数据,节省存储空间.
2 Hbase自动切分数据,使得数据存储自动具有水平scalability.
3 Hbase可以提供高并发读写操作的支持
Hbase的缺点:
1 不能支持条件查询,只支持按照Row key来查询.
2 暂时不能支持Master server的故障切换,当Master宕机后,整个存储系统就会挂掉.
四.补充
1.数据类型,HBase只有简单的字符类型,所有的类型都是交由用户自己处理,它只保存字符串。而关系数据库有丰富的类型和存储方式。
2.数据操作:HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,而传统数据库通常有各式各样的函数和连接操作。
3.存储模式:HBase是基于列存储的,每个列族都由几个文件保存,不同的列族的文件时分离的。而传统的关系型数据库是基于表格结构和行模式保存的
4.数据维护,HBase的更新操作不应该叫更新,它实际上是插入了新的数据,而传统数据库是替换修改
5.可伸缩性,Hbase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松增加或减少硬件的数量,并且对错误的兼容性比较高。而传统数据库通常需要增加中间层才能实现类似的功能
下面是用详细实际操作截图比较区别
1.nosql数据库能否删除列 2.nosql数据库如何删除一条记录 3.nosql数据库列族和lieder区别是什么? 4.nosql操作与传统数据库的操作区别在什么地方? 对于大多数做技术的人员,都知道我们传统数据库是什么样子的,那么如下图所示,我们操作的对象是行。 也就是增删改查,都是以为对象。 1.传统数据库增加删除介绍  图1 图1下面我们以mysql为例: 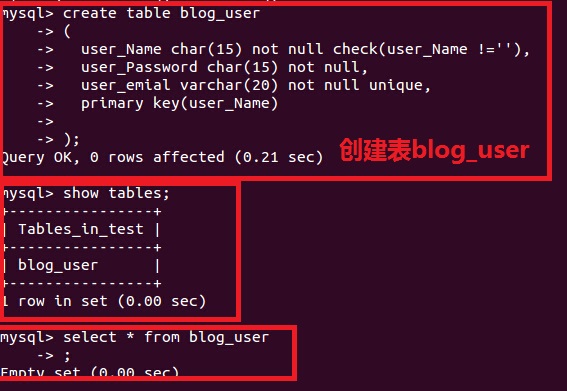 插入数据 mysql>INSERT INTO blog_user (`user_Name`,`user_Password`,`user_emial`)VALUES (‘aboutyun‘,‘aboutyun‘, ‘[email protected]‘);  删除数据:
 2.Nosql数据库增加删除介绍 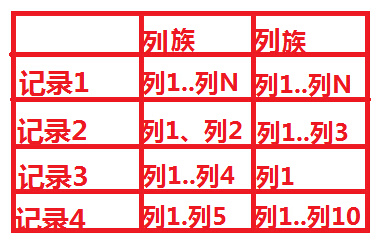 图2 以hbase为例: 创建表:
 插入数据 这里是关键点,也是很多人不容易理解的地方
 上面我们看到了 1所示是什么,我们在传统数据块里面根本没有,这是nosql所特有的,是一个rowkey,是系统自带的,也是nosql中一条记录的唯一标识。但是这个唯一标识,有跟我们的传统数据库是有所差别的。如图1所示,“记录1”便是rowkey. 2所示是我们插入的列user_Name,这也是最难以理解的地方,列竟然可以插入。并且其’value‘为3即‘aboutyun‘ 我们插入了列,下面我们来查看一下效果:  下面来解释一下上面的含义: 我们会看到 1为rowkey,插入数据’www.aboutyun.com‘, 2为列族下面列的名字user_Name 3我们并没有在设计的添加这个列族,所以这个是系统自带的,这个是记录的操作时间,以时间戳的形式放到hbase里面。 4是我们插入的user_Name的值 下面我们在插入password:
 再次查询结果:
 到这里,我们看到两行记录,传统数据块认为这是两行数据,对于nosql,这是一条记录。 删除列数据 删除数据分为删除列和删除记录 1.删除列 这里面的删除,没有删除 delete ‘blog_user‘,‘www.aboutyun.com‘,‘userInfo:user_Password‘  从上面我们看出列被删除了 2.删除记录:
这是删除之前显示结果,这里已经是  删除后结果 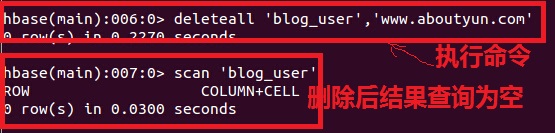 总结 对于传统数据库,增加列对于一个项目来讲,改变是非常大的。但是对于nosql,插入列和删除列,跟传统数据库里面的增加记录和删除记录类似 |
以上是关于Hbase与传统关系型数据库对比的主要内容,如果未能解决你的问题,请参考以下文章