正则表达式2
Posted tantao258
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式2相关的知识,希望对你有一定的参考价值。
参考:http://www.jb51.net/article/65286.htm
1、[^]代表除了内部包含的字符以外都能匹配
import re key = r"mat cat hat pat" p1 = r"[^p]at"#这代表除了p以外都匹配 pattern1 = re.compile(p1) print (pattern1.findall(key)) #[\'mat\', \'cat\', \'hat\']
2、为了方便我们写简洁的正则表达式,它本身还提供下面这样的写法
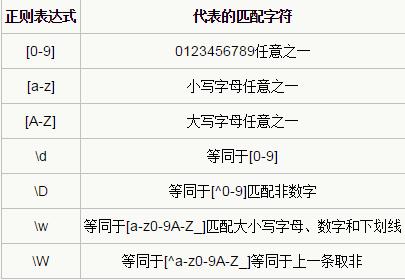
3、我们常常会在实战中遇到一些匹配的不准确的问题
import re key = r"chuxiuhong@hit.edu.cn" p1 = r"@.+\\."#我想匹配到@后面一直到“.”之间的,在这里是hit pattern1 = re.compile(p1) print (pattern1.findall(key)) #[\'@hit.edu.\']
你咋能多了呢?我理想的结果是@hit.,你咋还给我加量了呢?这是因为正则表达式默认是“贪婪”的,我们之前讲过,“+”代表是字符重复一次或多次。但是我们没有细说这个多次到底是多少次。所以它会尽可能“贪婪”地多给我们匹配字符,在这个例子里也就是匹配到最后一个“.”。
我们怎么解决这种问题呢?只要在“+”后面加一个“?”就好了。
import re key = r"chuxiuhong@hit.edu.cn" p1 = r"@.+?\\."#我想匹配到@后面一直到“.”之间的,在这里是hit pattern1 = re.compile(p1) print (pattern1.findall(key)) #[\'@hit.\']
加了一个“?”我们就将贪婪的“+”改成了懒惰的“+”。
个人建议:在你使用"+","*"的时候,一定先想好到底是用贪婪型还是懒惰型,尤其是当你用到范围较大的项目上时,因为很有可能它就多匹配字符回来给你
4、 为了能够准确的控制重复次数,正则表达式还提供
{a,b}(代表a<=匹配次数<=b)
如果你省略掉{1,2}中的2,那么就代表至少匹配一次
如果你省略掉{1,2}中的1,那么就代表至多匹配2次。
还是举个栗子,我们有sas,saas,saaas,我们想要sas和saas,我们怎么处理呢?
import re
key = r"saas and sas and saaas"
p1 = r"sa{1,2}s"
pattern1 = re.compile(p1)
print (pattern1.findall(key))
#[\'saas\', \'sas\']
5、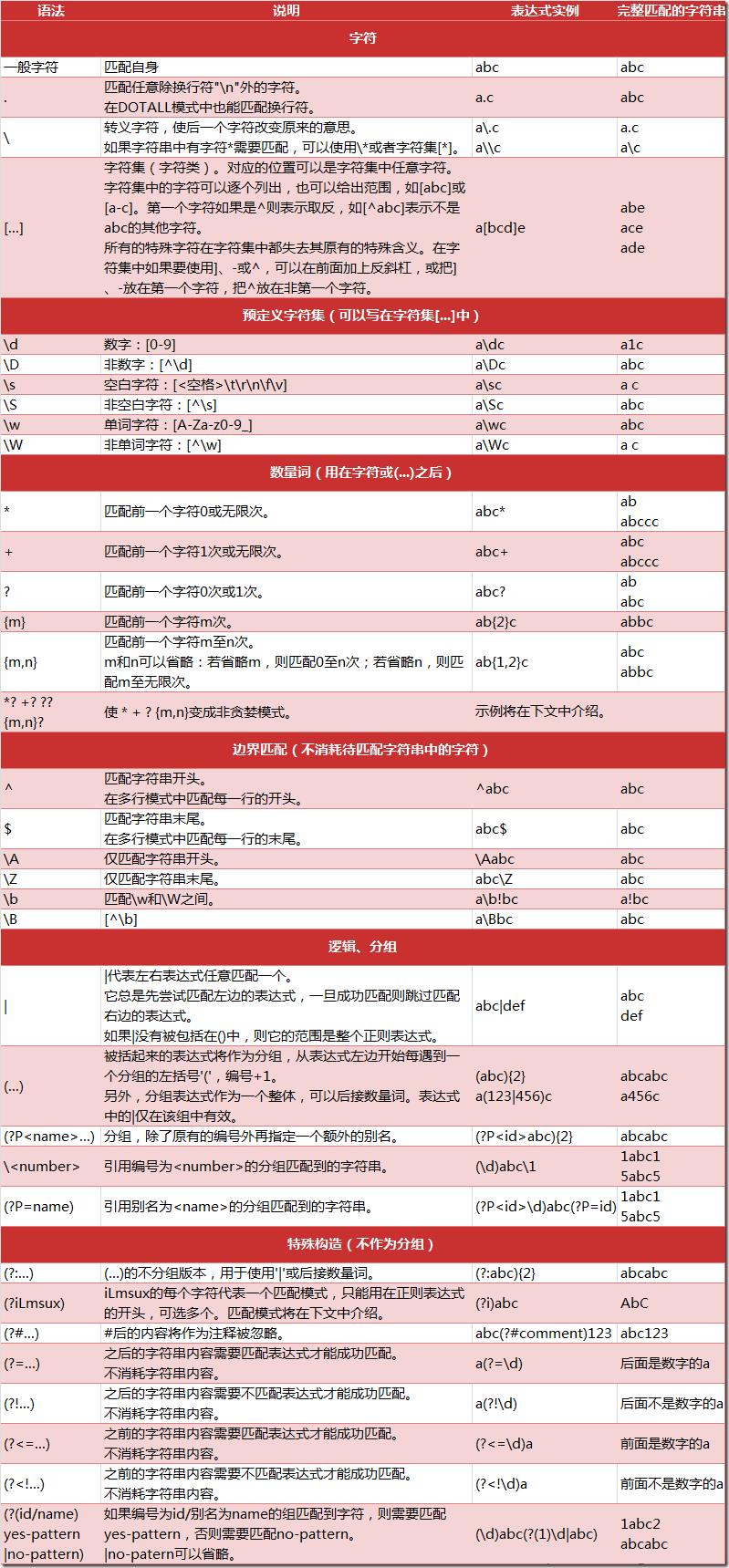
以上是关于正则表达式2的主要内容,如果未能解决你的问题,请参考以下文章