依赖倒置原则(Dependency Inversion Principle)
Posted 云水
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了依赖倒置原则(Dependency Inversion Principle)相关的知识,希望对你有一定的参考价值。
依赖倒置原则(Dependency Inversion Principle)
很多软件工程师都多少在处理 "Bad Design" 时有一些痛苦的经历。如果发现这些 "Bad Design" 的始作俑者就是我们自己时,那感觉就更糟糕了。那么,到底是什么让我做出一个能称为 "Bad Design" 的设计呢?
绝大多数软件工程师不会在设计之初就打算设计一个 "Bad Design"。许多软件也在不断地演化中逐渐地降级到了一个点,而从这个点开始,有人开始说这个设计已经腐烂到一定程度了。为什么会发生这些事情呢?是因为最初设计的匮乏吗,还是设计逐步降级到像块腐烂的肉一样?实际上,寻找这些答案得先从确定 "Bad Design" 的准确定义开始。
"Bad Design" 的定义
你可能曾经提出过一个让你倍感自豪的软件设计,然后让你的一个同事来做 Design Review?你能感觉到你同事脸上隐含的抱怨与嘲弄,他会冷笑的问道:"为什么你要这么设计?" 反正这事儿在我身上肯定是发生过,并且我也看到在我身边的很多工程师身上也发生过。确切的说,那些持不同想法的同事是没有采用与你相同的评判标准来断定 "Bad Design"。我见过最常使用的标准是 "TNNTWI-WHDI" ,也就是 "That\'s not the way I would have done it(要是我就不会这么干)" 标准。
但有一些标准是所有工程师都会赞同的。如果软件在满足客户需求的情况下,其呈现出了下述中的一个或多个特点,则就可称其为 "Bad Design":
- 难以修改,因为每次修改都影响系统中的多个部分。(僵化性Rigidity)
- 当修改时,难以预期系统中哪些地方会被影响。(脆弱性Fragility)
- 难以在其他应用中重用,因为它不能从当前系统中解耦。(复用性差Immobility)
此外,还有一些较难断定的 "Bad Design",比如:灵活性(Flexible)、鲁棒性(Robust)、可重用性(Reusable)等方面。我们可以仅使用上面明确的三点作为判定一个设计的好与坏的标准。
"Bad Design" 的根源
那到底是什么让设计变得僵化、脆弱和难以复用呢?答案是模块间的相互依赖。
如果一个设计不能很容易被修改,则设计就是僵化的。这种僵化性体现在,如果对相互依赖严重的软件做一处改动,将会导致所有依赖的模块发生级联式的修改。当设计师或代码维护者无法预期这种级联式的修改所产生的影响时,那么这种蔓延的结果也就无法估计了。这导致软件变更的代价无法被准确的预测。而管理人员在面对这种无法预测的情况时,通常是不会对变更进行授权,然后僵化的设计也就得到了官方的保护。
脆弱性是指一处变更将破坏程序中多个位置的功能。而通常新产生的问题所涉及的模块与该变更所涉及的模块在概念上并没有直接的关联关系。这种脆弱性极大地削弱了设计与维护团队对软件的信任度。同时软件使用者和管理人员都不能预测产品的质量,因为对应用程序某一部分简单的修改导致了其他多个位置的错误,而且看起来还是完全无关的位置。而解决这些问题将可能导致更多的问题,使得维护过程陷进了 "狗咬尾巴" 的怪圈。
如果设计中实现需求的部分对一些与该需求无关的部分产生了很强的依赖,则该设计陷入了死板区域。设计师可能会被要求去调查是否能够将该设计应用到不同的应用程序,要能够预知该设计在新的应用中是否可以完好的工作。然而,如果设计的模块间是高度依赖的,而从一个功能模块中隔离另一个功能模块的工作量足以吓到设计师时,设计师就会放弃这种重用,因为隔离重用的代价已经高于重新设计的代价。
示例:一个拷贝程序(Copy)
通过一个简单的例子来描述这些问题可能会对我们有所帮助。设想有一个简单的 "Copy" 程序,它负责将键盘上输入的字符拷贝到一个打印机上。假设设备独立而且是与平台无关的。我们可以构思这个程序的结构,类似于图 1 中的描述:
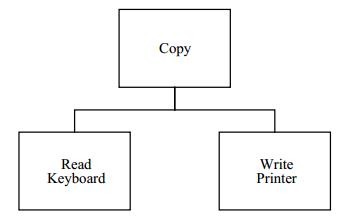
图 1 拷贝程序
图 1 是一个结构图。它显示在应用程序中一共有三个模块,或者叫子程序。"Copy" 模块负责调用其他两个模块。可以简单的想象成在 "Copy" 中有一个 while 循环,在循环体内调用 "Read Keyboard" 模块来尝试从键盘读取一个字符,然后将字符发送到 "Write Printer" 模块来打印字符。
1 void Copy()
2 {
3 int c;
4 while ((c = ReadKeyboard()) != EOF)
5 WritePrinter(c);
6 }
这个两层的模块设计是可以很好地被重用的,它们可以被使用到许多不同的应用程序中来控制对键盘和打印机的访问。
然而,"Copy" 模块在那些不使用键盘和打印机的条件下是无法被重用的。这太可惜了,因为系统所呈现的智能化就是体现在了这个模块里。"Copy" 模块封装了我们所感兴趣并且希望重用的部分。
例如,假设我们有一个新的程序,它需要将键盘字符拷贝到磁盘文件。我们显然希望复用 "Copy" 模块,因为它所做的高层封装正是我们需要的。而这个封装所做的就是描述将字符从源拷贝到目的地的过程。但很不幸,由于 "Copy" 模块直接依赖了 "Write Printer" 模块,所以这种新的需求情况下无法被重用。
当然,我们可以直接修改 "Copy" 模块来增加新的功能。通过增加 "if" 语句来检查一个标志位,判断到底是写到打印机还是写到磁盘,这样就可以分别使用 "Write Printer" 模块或 "Write Disk" 模块。然后,这样做之后我们就又在系统中增加了一个依赖模块。
1 enum OutputDevice {printer, disk};
2 void Copy(outputDevice dev)
3 {
4 int c;
5 while ((c = ReadKeyboard()) != EOF)
6 if (dev == printer)
7 WritePrinter(c);
8 else
9 WriteDisk(c);
10 }
随时时间的推移,越来越多的设备可以支持 "Copy" 功能,"Copy" 模块也将陷入凌乱的 "if/else" 判断中。这显然使应用变得僵化和脆弱。
依赖倒置(Dependency Inversion)
上述问题的主要特征是包含高层逻辑的模块依赖于低层模块的细节,例如 "Copy" 模块依赖于 "Read Keyboard" 模块和 "Write Printer" 模块。如果我们想办法使 "Copy" 模块不依赖于这些细节,则就会很容易地被复用。可以将其用于任何其他负责从输入设备将字符拷贝到输出设备的应用程序。OOD 为我们提供了一种机制,叫做依赖倒置(Dependency Inversion)。
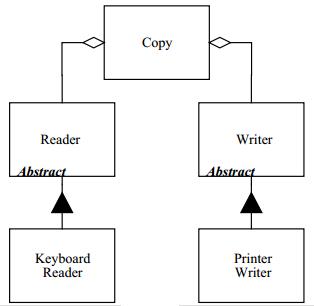
图 2
设想如图 2 中的类图结构。类 "Copy" 包含了一个抽象类 "Reader" 和另一个抽象类 "Writer"。可以想象在 "Copy" 中的循环结构不断的从 "Reader" 读取字符,然后将字符发送至 "Writer"。
1 class Reader
2 {
3 public:
4 virtual int Read() = 0;
5 };
6 class Writer
7 {
8 public:
9 virtual void Write(char) = 0;
10 };
11 void Copy(Reader& r, Writer& w)
12 {
13 int c;
14 while((c=r.Read()) != EOF)
15 w.Write(c);
16 }
此时类 "Copy" 既没有依赖 "Keyboard Reader" 也没有依赖 "Printer Writer"。因此,这些依赖已经被反转了(Inverted)。"Copy" 类依赖于抽象,而真正的 "Reader" 和 "Writer" 的具体实现也依赖于抽象。
此时,我们就可以重用 "Copy" 类,而不需要具体的 "Keyboard Reader" 和 "Printer Writer"。我们可以通过创造新的 "Reader" 和 "Writer" 衍生类然后替换到 "Copy" 中。而且,无论有多少种 "Reader" 和 "Writer" 被创建,"Copy" 都不会依赖于它们。因为没有这些模块间的相互依赖,也使得程序不会变的僵化和脆弱。并且 "Copy" 类也可以被复用到多种不同的情况中。它不再是固定的。
依赖倒置原则(The Dependency Inversion Principle)
A. High level modules should not depend upon low level modules. Both should depend upon abstractions.
B. Abstractions should not depend upon details. Details should depend upon abstraction.
A. 高层模块不应该依赖于低层模块,二者都应该依赖于抽象。
B. 抽象不应该依赖于具体实现细节,而具体实现细节应该依赖于抽象。

有人可能会问,为什么我要使用 "Inversion" 这个词儿。坦白的说,是因为,对于更加传统的软件开发方法,例如结构化的分析与设计(Structured Analysis and Design),更趋向于创建高层模块依赖于低层模块的软件结构,进而使得抽象依赖了具体实现细节。而且实际上这些方法最主要的目标就是通过定义子程序的层级关系来描述高层模块式如何调用低层模块的。图 1 中的示例正好描述了这样的一个层级结构。因此,一个设计良好的面向对象程序的依赖结构是 “inverted” 倒置了相对于传统过程化方法的依赖结构。
考虑下高层模块依赖于低层模块所带来的连带影响。高层模块包含着应用程序中重要的业务决策信息,是这些业务模型包含了应用程序的功能特征。当这些模块依赖于低层模块时,对低层模块的修改将直接影响高层模块,也就是强制修改了它们。
这种情形是违反常理的!应该是高层模块强制要求修改低层模块才对。高层模块的权重应该优先于低层模块。高层模块是无论如何都不应当依赖于低层模块。
更进一步说,我们其实想重用的是高层模块。我们已经通过子程序库等方式很好地重用了低层模块了。如果高层模块依赖于低层模块,将导致高层模块在不同的环境中变得极难被复用。而如果高层模块完全独立于与低层模块,高层模块就可以很容易地被复用。这就是这个原则的核心所在。
分层(Layering)
依据 Grady Booch 的定义:
All well-structured object-oriented architectures have clearly-defined layers, with each layer providing some coherent set of services though a well-defined and controlled interface.
所有结构良好的面向对象架构都有着清晰明确的层级定义,每一层都通过一个定义良好和可控的接口来提供一组内聚的服务集合。
如果不加思索的来解释这段话,可能会让设计师创建出类似于图3中的结构。
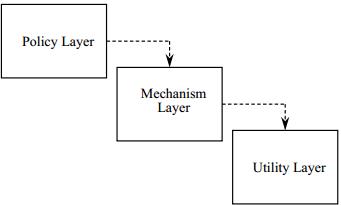
图 3
在图中高层类 "Policy" 使用了低层类 "Mechanism","Mechanism" 使用了更细粒度的 "Utility" 类。这看起来像是很合适,但其实隐藏了一个问题,就是对于 Policy Layer 的更改将对一路下降至 Utility Layer。这称为依赖是传递的(Dependency is transitive)。Policy Layer 依赖一些依赖于 Utility Layer 的模块,然后 Policy Layer 传递性的依赖了 Utility Layer。这显示是非常不幸的。
图 4 给出了一个更合适的模型。
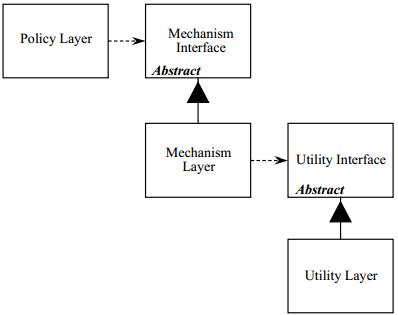
图 4
每一个低层都被一个抽象类所表述,而实际的层级则由这些抽象类所派生。每一个高层类通过抽象接口来使用低层类。因此,层级之间不会依赖其他的层。取而代之的是,层依赖了抽象类。这不仅打破了 Policy Layer 到 Utility Layer 的传递性依赖,同时也将 Policy Layer 到 Mechanism Layer 的依赖打破。
使用这个模型后,Policy Layer 不会被任何 Mechanism Layer 或 Utility Layer 的更改所影响。同时,Policy Layer 也能够在任何情形下进行重用,只要是低层模块符合 Mechanism Layer Interface 定义即可。因此,通过反转依赖关系,沃恩稿件了一个更灵活、更持久的设计结构。
总结
依赖倒置原则(Dependency Inversion Principle)是很多面向对象技术的根基。它特别适合应用于构建可复用的软件框架,其对于构建弹性地易于变化的代码也特别重要。并且,因为抽象和细节已经彼此隔离,代码也变得更易维护。
面向对象设计的原则
参考资料
- SRP:The Single Responsibility Principle by Robert C. Martin “Uncle Bob”
- The SOLID Principles, Explained with Motivational Posters
- Dangers of Violating SOLID Principles in C#
- An introduction to the SOLID principles of OO design
本文《依赖倒置原则(Dependency Inversion Principle)》由 Dennis Gao 翻译改编自 Robert Martin 的文章《DIP: The Dependency Inversion Principle》,未经作者本人同意禁止任何形式的转载,任何自动或人为的爬虫行为均为耍流氓。
以上是关于依赖倒置原则(Dependency Inversion Principle)的主要内容,如果未能解决你的问题,请参考以下文章