Infobright 架构白皮书
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Infobright 架构白皮书相关的知识,希望对你有一定的参考价值。
1. 介绍
如今的商业智能BI领域已经不仅仅是财务分析和市场研究者的专属了,以前那些只要求定期性报告的行业和部门现在也要求对商业数据进行即时和定制化的访问。所以,今天的领袖企业在几乎每一个运营部门都在进行分析软件和流程的整合。这些企业还要求他们的vendor在提供的应用和业务里集成adhoc报告和分析的功能。
伴随着按需分析(on-demand analytics)的兴起,数据存储量也在快速增长。分析公司Aberdeen指出,现在对于BI数据的存储需求年增长率超过56%而且没有减缓的迹象。其中出现了一类商业价值高,增长速度快的数据类型:机器生成的数据。(以下简称机器数据)
2. 机器数据
与其他商业数据的类型不同,机器数据不再收到用户数量或者人类活动量等因素的限制,而是
- 由计算机,传感器和嵌入式设备所生成
- 一般是监控存下的记录
- 一旦存在数据库里便很少更改
- 由于监管的原因,保存时间久
能够生产机器数据的源包括Web的日志,计算机和网络事件,传感器和RFID设备,电信CDR和自动触发的财务交易。但是机器数据最大的特点还是量大,针对这一趋势,分析师Monash写道 “与人类生产的数据不同,机器数据的增长符合摩尔定律”
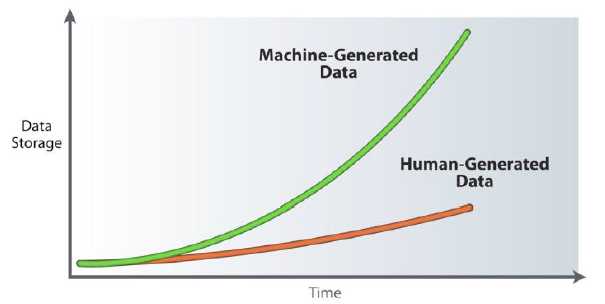
这种增长反映了我们日常生活方方面面都在数字化的结果。但是,它对企业和技术提供者提出的不仅是技术和商业上的挑战,还有前所未有的机遇。
随着商业数据(特别是机器数据)的日益增长和IoT应用的临近,领袖企业开始借此机会去提高决策的准确度和组织的敏捷度。这种需求催生了一种新的操作环境,特点是
- 不同的组织的用户以不同的方式访问同样的数据
- 采用动态和交互的方法进行数据挖掘,由此产生了复杂的adhoc查询
- 对新捕获的数据进行实时分析的需求
- 查询时间在秒或分钟级,而不是小时或天
虽然一些内部的应用开发者和BI软件的提供者已经开始具备自我服务(self-service)的能力,但是仍然有许多的IT公司因为底层数据管理系统不断增长的复杂性,成本和时间限制而倍感压力。
3. 行存储 vs 列存储
许多IT企业和技术方案的提供商都依赖于传统的关系型数据库作为他们的数据仓库,问题是关系型数据库是为了交易型应用而设计的,而不是针对大数据量的分析型应用。所以,许多公司发现,随着数据量的增长,那些系统无法满足用户的性能要求。除此之外,传统的数据库技术还要求大量的额外工作(比如说索引的创建和维护,Cube或是Projection或是分区数据的创建),购买和维护的成本都很高。
由于这些问题,近年来出现了许多新技术来解决各种不同的使用场景。
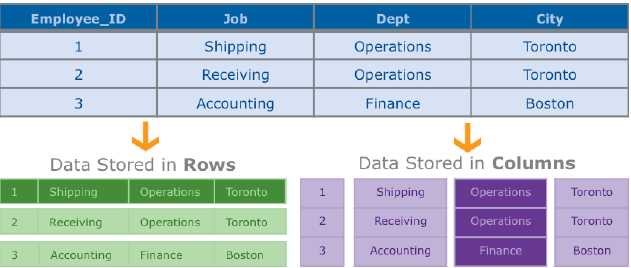
Infobright DB是一种高性能的按列存储的数据库。让我们看一下按列存储的数据库与按行存储的数据库(Oracle, SQL server, PostgreSQL, mysql)有什么不同。按行存储的数据库把一条记录(行)的所有值按一个整体来存储。而另一种方式呢,是把所有记录按列进行存储,如上图所示。
当数据按行进行存储时,一个应用为了读取某个字段,比如员工所在的部门,就需要读取整条记录。而如果按列存储呢,数据库则仅需要返回与部门属性相关的值即可。在分析型应用中,按列存储可以极大的减少I/O操作,降低查询时间,特别是在记录size很大或者用户在使用复杂的adhoc查询的时候尤其明显。
未完待续
以上是关于Infobright 架构白皮书的主要内容,如果未能解决你的问题,请参考以下文章