pandas stack和unstack函数
Posted Alice_鹿_Bambi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas stack和unstack函数相关的知识,希望对你有一定的参考价值。
在用pandas进行数据重排时,经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即“不要堆叠”,我对两个函数是这样理解和区分的。
常见的数据的层次化结构有两种,一种是表格,一种是“花括号”,即下面这样的l两种形式:
|
|
store1 |
store2 |
store3 |
|
street1 |
1 |
2 |
3 |
|
street2 |
4 |
5 |
6 |
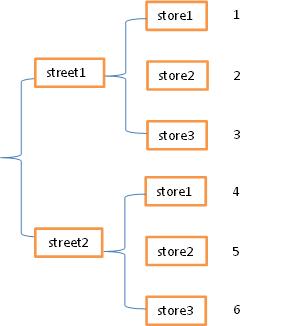
表格在行列方向上均有索引(类似于DataFrame),花括号结构只有“列方向”上的索引(类似于层次化的Series),结构更加偏向于堆叠(Series-stack,方便记忆)。stack函数会将数据从”表格结构“变成”花括号结构“,即将其行索引变成列索引,反之,unstack函数将数据从”花括号结构“变成”表格结构“,即要将其中一层的列索引变成行索引。例:
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
data=DataFrame(np.arange(6).reshape((2,3)),index=pd.Index([\'street1\',\'street2\']),columns=pd.Index([\'one\',\'two\',\'three\']))
print(data)
print(\'-----------------------------------------\\n\')
data2=data.stack()
data3=data2.unstack()
print(data2)
print(\'-----------------------------------------\\n\')
print(data3)
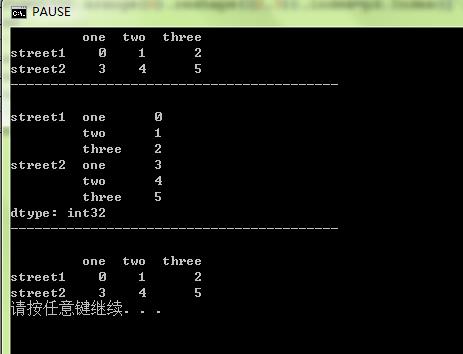
·打印结果如下:使用stack函数,将data的行索引[\'one\',\'two\',\'three’]转变成列索引(第二层),便得到了一个层次化的Series(data2),使用unstack函数,将data2的第二层列索引转变成行索引(默认的,可以改变),便又得到了DataFrame(data3)。
以上是关于pandas stack和unstack函数的主要内容,如果未能解决你的问题,请参考以下文章