整数快速乘法/快速幂+矩阵快速幂+Strassen算法 (转)
Posted mhp的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了整数快速乘法/快速幂+矩阵快速幂+Strassen算法 (转)相关的知识,希望对你有一定的参考价值。
快速幂算法可以说是ACM一类竞赛中必不可少,并且也是非常基础的一类算法,鉴于我一直学的比较零散,所以今天用这个帖子总结一下
快速乘法通常有两类应用:一、整数的运算,计算(a*b) mod c 二、矩阵快速乘法
一、整数运算:(快速乘法、快速幂)
先说明一下基本的数学常识:
(a*b) mod c == ( (a mod c) * (b mod c) ) mod c //这最后一个mod c 是为了保证结果不超过c
对于2进制,2n可用1后接n个0来表示、对于8进制,可用公式 i+3*j == n (其中 0<= i <=2 ),对于16进制,可用 i+4*j==n(0 <= i <=3)来推算,表达形式为2i 后接 j 个0。
接下来让我们尽可能简单的描述快速乘法的思想:
a*b
快速乘法的基本思想 ,是二进制和乘法分配律的结合,(不由得想起浮点数不满足结合律,严重吐槽!!!╮(╯-╰)╭),比如说,13 ==(1101)2 ,4*13等于4*(1101)2 ,用分配律展开得到4*13 == 4*(1000+100+1)2,我们不难观察出,快速乘法可以通过判断当前的位(bit)是1还是0,推断出是否需要做求和操作,每次移动到下一位(bit)时,就对ans进行*2操作,等待是否求和。由于除以2和位移操作是等效的,因此这也可以看作是二分思想的应用,这种算法将b进行二分从而减少了不必要的运算,时间复杂度是log(n)。
a^b
快速幂其实可以看作是快速乘法的特例,在快速幂中,我们不再对ans进行*2操作,因为在a^b中b的意义已经从乘数变成了指数,但是我们可以仍然把b写成二进制,举例说明:此时,我们将4*13改为4^13,13=(1101)2 ,二进制13写开我们得到(1000+100+1),注意,这里的所有二进制是指数,指数的相加意味着底数相乘,因此有4^13 == 48 * 44 * 41。再注意到指数之间的2倍关系,我们就可以用很少的几个变量,完成这一算法。这样,我们就将原本用循环需要O(n)的算法,改进为O(logN)的算法。
按照惯例,给出尽可能简洁高效的代码实现 (以下所有int都可用long long 代替)
首先,给出快速乘法的实现:
1 //快速乘法
2 int qmul(int a,int b){// 根据数据范围可选择long long
3 int ans=0;
4 while(b){
5 if( b&1)ans+=a;//按位与完成位数为1的判断
6 b>>=1;a<<=1;//位运算代替/2和*2
7 }
8 return ans;
9 }
如果涉及到快速乘法取模,则需要进行一些微小改动
改动所基于的数学原理,请参考红色字体标出的数学常识
1 //快速乘法取模
2 int qmul_mod(int a,int b,int mod){
3 int ans=0;
4 while(b){
5 if((b%=mod)&1)ans+=a%=mod;//这里需要b%=mod 以及a%=mod
6 b>>=1;a<<=1;
7 }
8 return ans%mod; //ans也需要对mod取模
9 }
接下来是快速幂的实现:
1 //快速幂 a^b
2 int qpow(int a,int b){
3 if(a==0)return 0;//这是个坑,校赛被坑过,很多网上的实现都没写这一点
4 int ans=1;
5 while(b){
6 if(b&1)ans*=a;//和快速乘法的区别
7 b>>=1;a*=a;//区别,同上
8 }
9 return ans;
10 }
以及含有取模的快速幂:
int qpow_mod(int a,int b,int mod){
if(a==0)return 0;
int ans=1;
while(b){
if(b&1)ans=(ans%mod)*(a%mod);//如果确定数据不会爆的话,可写成 ans*=a%=mod;
b>>=1;a*=a%=mod;//等价于a=(a%mod)*(a%mod),且将一个模运算通过赋值代替,提高了效率
}
return ans%mod;//数据不会爆的话,这里的%运算会等价于第5中不断重复的 ans%mod
}
如果我们对于性能还有更进一步的要求,那么也就是减少取模运算了,那么我们需要确定数据范围不会爆掉
在这样的前提下,我们可以只用原先1/4的取模运算量完成快速幂
int qpow_mod(int a,int b,int mod){
if(!a)return 0;
int ans=1;
while(b){
if(b&1)ans*=a%=mod;//这里的模运算只有一个
b>>=1;a*=a;//这里的模运算没有了
}
return ans%mod;
}
这些天找了好久,终于找到了纯粹的整数快速幂题目,按照惯例,给一波传送门:
poj1995:http://poj.org/problem?id=1995
这个题。。。没什么好说的,但是需要注意,用1/4模运算量的那种写法,数据会爆,所以必须写成完全取模的运算,这样程序会慢一点。。。呜呜呜,63ms水过,这是目前我做的最慢的了,如果大神知道如何在16ms及以下A掉它,欢迎联系我谢谢~o(* ̄▽ ̄*)ブ

实现的代码如下:


1 #include<cstdio>
2 int z,a,b,m,h,sum;
3 int qpow_mod(int a,int b,int mod){
4 if(!a)return 0;
5 int ans=1;
6 while(b){
7 if(b&1)ans=ans%mod*(a%=mod);
8 b>>=1;a=a%mod*(a%mod);
9 }
10 return ans%mod;
11 }
12 int main(){
13 scanf("%d",&z);
14 while(z--){
15 scanf("%d%d",&m,&h);sum=0;
16 while(h--){
17 scanf("%d%d",&a,&b);
18 sum+=qpow_mod(a,b,m);
19 sum%=m;
20 }
21 printf("%d\\n",sum);
22 }
23 }
先更新到这,有时间再更新矩阵的Strassen算法以及矩阵快速幂,,大家稍后见(●\'◡\'●)
2016-06-13 16:47:56
大家好,我又回来啦
二、矩阵运算:(快速幂)(Strassen算法有空再说)
矩阵的快速幂运算,其实思路和上面的整数快速幂是一样的,对指数进行二分,不过我们对于快速幂本身,可能既可以写成函数,也可以写成运算符重载,所以这里我写的是运算符的重载,毕竟重载练得少,得多练一练
首先我们可以定义一个矩阵数据结构,也可以直接用二维数组
1 #define N 100
2 struct matrix{
3 int m[N][N];
4 };
然后我们重载^运算符,完成矩阵m的b次幂的快速幂运算
这里为了我自己代码习惯,我重载了*和*=两种运算符,当然,在写的时候跪在了忘了写函数声明上,毕竟C++不是java,对于函数声明的顺序有依赖,so~大家记得写函数声明呦
代码如下
1 //矩阵的数据结构
2 struct matrix{
3 int m[N][N];
4 };
5 matrix operator * (matrix ,matrix);//重载声明
6 matrix operator *= (matrix,matrix);
7 matrix operator ^ (matrix a,int b){
8 matrix ans;
9 for(int i=0;i<N;i++)
10 for(int j=0;j<N;j++)ans.m[i][j]=(i==j);//初始化为单位矩阵,矩阵A*A的单位矩阵=A
11 if(b&1)ans*=a;
12 b>>=1;a*=a;
13 return ans;
14 }
15 matrix operator * (const matrix a,const matrix b){//朴素矩阵乘法
16 matrix ans;
17 for(int i=0;i<N;i++)
18 for(int j=0;j<N;j++)
19 for(int k=0;k<N;k++)
20 ans.m[i][j]=a.m[i][k]+b.m[k][j];
21 return ans;
22 }
23 matrix operator *= (matrix a,const matrix b){
24 return a=b*b;//此处应为a=a*b;
25 }
当然,有必要的时候,我会再更新一波Strassen算法,考虑到在很多情况下,Strassen算法反而会降低矩阵运算的速度,所以我们就先到这里~拜拜(●ˇ∀ˇ●)
应用篇
主要通过把数放到矩阵的不同位置,然后把普通递推式变成"矩阵的等比数列",最后快速幂求解递推式:
线性递推方程即形如fn=a1fn-1+a2fn-2+……+aifn-i的方程
先通过入门的题目来讲应用矩阵快速幂的套路(会这题的也可以看一下套路):
例一:http://poj.org/problem?id=3070
题目:斐波那契数列f(n),给一个n,求f(n)%10000,n<=1e9;
(这题是可以用fibo的循环节去做的,不过这里不讲,反正是水题)
矩阵快速幂是用来求解递推式的,所以第一步先要列出递推式:
f(n)=f(n-1)+f(n-2)
第二步是建立矩阵递推式,找到转移矩阵:
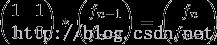 ,简写成T * A(n-1)=A(n),T矩阵就是那个2*2的常数矩阵,而
,简写成T * A(n-1)=A(n),T矩阵就是那个2*2的常数矩阵,而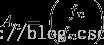
这里就是个矩阵乘法等式左边:1*f(n-1)+1*f(n-2)=f(n);1*f(n-1)+0*f(n-2)=f(n-1);
这里还是说一下构建矩阵递推的大致套路,一般An与A(n-1)都是按照原始递推式来构建的,当然可以先猜一个An,主要是利用矩阵乘法凑出矩阵T,第一行一般就是递推式,后面的行就是不需要的项就让与其的相乘系数为0。矩阵T就叫做转移矩阵(一定要是常数矩阵),它能把A(n-1)转移到A(n);然后这就是个等比数列,直接写出通项: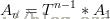 此处A1叫初始矩阵。所以用一下矩阵快速幂然后乘上初始矩阵就能得到An,这里An就两个元素(两个位置),根据自己设置的A(n)对应位置就是对应的值,按照上面矩阵快速幂写法,res[1][1]=f(n)就是我们要求的。
此处A1叫初始矩阵。所以用一下矩阵快速幂然后乘上初始矩阵就能得到An,这里An就两个元素(两个位置),根据自己设置的A(n)对应位置就是对应的值,按照上面矩阵快速幂写法,res[1][1]=f(n)就是我们要求的。
另种解释:在斐波那契数列之中
f[i] = 1*f[i-1]+1*f[i-2] f[i-1] = 1*f[i-1] + 0*f[i-2];
即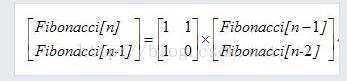
所以
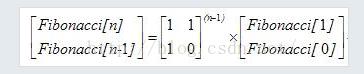
就这两幅图完美诠释了斐波那契数列如何用矩阵来实现。
给一些简单的递推式
1.f(n)=a*f(n-1)+b*f(n-2)+c;(a,b,c是常数)
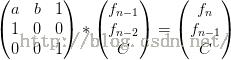
2.f(n)=c^n-f(n-1) ;(c是常数)
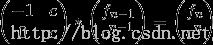
继续例题二:poj3233
Description
Given a n × n matrix A and a positive integer k, find the sum S = A + A2 + A3 + … + Ak.
Input
The input contains exactly one test case. The first line of input contains three positive integers n (n ≤ 30), k (k ≤ 109) and m (m < 104). Then follow n lines each containing n nonnegative integers below 32,768, giving A’s elements in row-major order.
Output
Output the elements of S modulo m in the same way as A is given
这题就是求一个矩阵的和式:S(k),直接对和式建立递推:
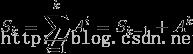
建立矩阵,注意此处S和A都是2*2的矩阵,E表示单位矩阵,O表示零矩阵(全是0,与其他矩阵相乘都为0),显然E,O都是2*2的
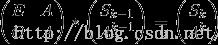 这里转移矩阵是4*4.OVER
这里转移矩阵是4*4.OVER
一般这种题目都是要找递推式,这是难点.
例三:HDU2276
题意就是说n个灯排成环i号灯的左边是i-1号,1的左边是n号,给定初始灯的开闭状态(用1,0表示),然后每一秒都操作都是对于每个灯i,如果它左边的灯是开的就把i状态反转(0变1,1变0),问m秒都最终状态是什么,m<=1e8,n<=100;
这题的递推式没有明说,但是每一秒操作一次其实就是一次递推,那么关键就是要找转移矩阵,而且比较是常数矩阵,这个才能用等比的性质
我们把n个灯的状态看出一个F(n),其实就是一个n*1的01矩阵,然后考虑从上一秒的状态F(n-1)如何转移到F(n)。既然每个状态都要转移,总共n个状态,可以看出转移矩阵就是一个n*n的矩阵(每一个灯的状态都用一个1*n的矩阵来转移)
先考虑第一个灯:影响它新状态的只有它左右的灯和它自己的状态,仔细想一下,1*n的转移中只有这两位置有用,那么其他都是0,就这样
 这里state2到staten-1都被0干掉了,只有第一个和1号左边的灯有效
这里state2到staten-1都被0干掉了,只有第一个和1号左边的灯有效
(这里不具体讲了,只有0,1的状态,自己枚举一下state1和state2,矩阵相乘后都是能正确转移的)
其他灯的考虑都是一样的,最终:
 OVER
OVER
例四:HDU 5015
题意就是一个矩阵a,第一行依次是0,233,2333,23333......,给出矩阵的递推式:a[i][j]=a[i-1][j]+a[i][j-1],输入的是第零列,求a[n][m],n ≤ 10,m ≤ 109
解:n很小,m很大,m大概就是作为幂次,以每一列为一个矩阵A(n-1)并且向下一列A(n)转移,那么关键就是找转移矩阵了:
先看第一行的数233后面每次都添一个3,显然递推关系就是A(n-1)*10+3=A(n),这里多一个3,必须把列数新增一个元素3,也就是一个(n+1)*1的矩阵A(n).
然后其他的元素转移会出现一个问题,a[i][j]=a[i-1][j]+a[i][j-1];这里a[i-1][j]依旧是新一列的元素,这是不能矩阵转移的,因为矩阵转移必须从旧的矩阵状态A(n-1)变到新状态A(n)。
那么这里a[i-1][j]就用递归思想,沿用上一行的转移矩阵(上一行能转移出a[i-1][j]),再加上新增的转移:
 OVER
OVER
当然矩阵还有很多奇葩的递推,比如这矩阵优化的dp题。HDU5318
推荐一些题目:
简单的:
http://acm.hdu.edu.cn/showproblem.php?pid=1757
http://acm.hdu.edu.cn/showproblem.php?pid=1575
不简单的:
http://acm.hdu.edu.cn/showproblem.php?pid=3483
http://acm.hdu.edu.cn/showproblem.php?pid=2855
http://acm.hdu.edu.cn/showproblem.php?pid=3658
http://acm.hdu.edu.cn/showproblem.php?pid=4565
另一篇矩阵二分快速幂入门与进阶
矩阵快速幂——入门
题目链接POJ307
题意:求第n位斐波那契数mod 10000的大小。其中n的大小高达1000000000
由于我对矩阵快速幂也不是很了解,所以只能浅谈,不敢深谈,希望对新手有点帮助。
先聊聊快速幂
首先,如果要你自己写一个pow()函数,需要求220,怎么求
#include <iostream>
using namespace std;
int quickPow(int a,int b){ //快速幂
int ans = 1;
while(b){
if(b&1) ans*=a;
a *= a;
b /= 2;
}
return ans;
}
int pow(int a,int b){ //普通乘
int ans = 1;
for(int i=1; i<=b; i++)
ans *= a;
return ans;
}
int main(int argc, const char * argv[]) {
cout<<quickPow(2, 20)<<endl; //第一种方式
cout<<pow(2,20)<<endl; //第二种方式
return 0;
}上面的两种方式,一种复杂度是O(logn),一种复杂度是O(n)。当你数量级很大的时候,比如10000000000时,这个复杂度的时间差别就很大了
怎么得到这个快速幂的代码的呢?我们假设需要求274
74转化为二进制为1001010,根据二进制对应位的1,可以把74拆分为64+8+2 ,所以
74 = 26 + 23 + 21
274 = 226 + 223 + 221
while(b){ //快速幂核心代码
if(b&1) ans*=a;
a *= a;
b /= 2;
}下面看一下上面这段快速幂程序中的ans和a的用法 (74二进制1001010为从右到左下面表格从1-7)
| 初始值 | 0 | 1(ans变了) | 0 | 1(ans变了) | 0 | 0 | 1(ans变了) | |
|---|---|---|---|---|---|---|---|---|
| a = 2n | 21 | 22 | 24 | 28 | 216 | 232 | 264 | 2128 |
| ans | 20 | 20 | 20×22 | 20×22 | 20×22×28 | 20×22×28 | 20×22×28 | 20×22×28×264 |
这里有两个变量,第一个变量a默认用来存2n,,变量ans存储的是最后的结果,当遇到第k位的二进制位是1的时候,则ans ×= 2k
举个例子,74的二进制表示是1001010,因为是除2运算,所以从右往左遍历,到右边第二个时,ans ×= 22,到右边第四个时,ans ×= 28,到右边第7个时,ans ×= 264,最后ans = 274,至于ans乘的过程中的那些22、28、264怎么来?a变量不是一直在不断增加吗,ans乘的就是a变量对应位的值,对应上面的表格可能看的更清楚一点
不知道,你看懂没……如果还是没懂,就给个面子装懂好嘛……
矩阵?怎么过渡到斐波那契
- 宏观上看矩阵

上图中,乘号右边是一系列的矩阵。我们称为B1、B2、B3、B4 …… Bn
该序列中的同行为一个斐波那契数列。乘号左边是一个转移矩阵A,Bn = A×Bn-1
- 微观上看矩阵


原始的序列是 [A,B],需要得到的序列是[A+B,A],根据矩阵相乘定律,可以得到转移矩阵A
- 总结一波
现在需要求的是Bn%10000,Bn = B1 × An,B1是[1,1],所以 An就是需要的答案。那把求Bn改成了求An有什么好处呢?见下文
矩阵快速幂的实际运用
上述矩阵代替斐波那契数列的方式。已经把斐波那契数列从原先的递加变成了现在的递乘。那变成递乘有什么用?
如果斐波那契第一项是A,第二项是A2,第三项是A3,第4项是A4 ……
那第8项的值是,A8 = A4×A4
换句话说,第4项的值 × 第4项的值 = 第8项的值
求第16项的值
原来的方式是:1->2->3->4……->15->16需要经过15次运算
现在的方式是:1->2->4->8->16只需要经过4次运算
为什么只需要经过4次?从A->A2得到第2项,我要求第4项不需要经过第3项,直接A2 × A2 -> A4就可以得到第4项。这又回到了刚开始的快速幂
具体怎么得到,下面请看代码解析
代码拆分
代码不长,先看下面这个函数。这里使用了引用传递,即a数组发生变化后,传入的实参也会改变。例如传入数组a和数组b,得到的数组a = 数组a × 数组b。即Matrix(cot,temp)执行的结果是cot *= temp,且cot和temp都表示的是矩阵数组
void Matrix(int (&a)[2][2],int b[2][2]){ //矩阵乘法
int tmp[2][2] = {0};
for(int i = 0; i < 2; ++i)
for(int j = 0; j < 2; ++j)
for(int k = 0; k < 2; ++k)
tmp[i][j] = (tmp[i][j] + a[i][k] * b[k][j]) % N; //矩阵相乘,注意mod
for(int i = 0; i < 2; ++i)
for(int j = 0; j < 2; ++j)
a[i][j] = tmp[i][j]; //赋值返回数据
}A1,也就是转移矩阵,题中已经给出了,用数组表示是[1,1,1,0]。这里还需要一个A0,A0其实就是单位矩阵E(E × 任意矩阵A = A)。单位矩阵用数组表示就是[1,0,0,1](对角线都是1的矩阵)
while(n){
if(n & 1) Matrix(cot,temp); //如果是奇数
Matrix(temp,temp);
n /= 2; //不断除2
}上述5行代码是矩阵快速幂关键(至于怎么得到这5行代码的,在上述快速幂的解释中应该已经可以得到了)。cot数组一开始是A0,temp数组一开始是A1。我们来模拟下求第13项的斐波那契值是怎么求的。
第一步:n = 13,执行Matrix(cot,temp)和Matrix(temp,temp),得到cot数组为A1,t数组为A2,n = 6
第二步:n = 6,执行Matrix(temp,temp),得到cot数组为A1,t数组为A4,n = 3
第三步:n = 3,执行Matrix(cot,temp)和Matrix(temp,temp),得到cot数组为A5,t数组为A8,n = 1
第四步:n = 1,执行Matrix(cot,temp)和Matrix(temp,temp),得到cot数组为A13,t数组为A16,n = 0
退出while循环并输出cot数组对应的值。一共进行了4步。
完整代码
#include <iostream>
using namespace std;
int N = 10000,n;
void Matrix(int (&a)[2][2],int b[2][2]){
int tmp[2][2] = {0};
for(int i = 0; i < 2; ++i)
for(int j = 0; j < 2; ++j)
for(int k = 0; k < 2; ++k)
tmp[i][j] = (tmp[i][j] + a[i][k] * b[k][j]) % N;
for(int i = 0; i < 2; ++i)
for(int j = 0; j < 2; ++j)
a[i][j] = tmp[i][j];
}
int main(){
while(cin>>n && n!=-1){
int temp[2][2] = {1, 1, 1, 0},cot[2][2] = {1, 0, 0, 1};
while(n){
if(n & 1) Matrix(cot,temp);
Matrix(temp,temp);
n /= 2;
}
cout<<cot[0][1]<<endl;
}
return 0;
}这篇文章主要利用斐波那契数列来浅谈矩阵快速幂的用法,矩阵快速幂还有更大的使用空间,后续有空会补上矩阵快速幂的其他用法,另外送上一篇文章 十个利用矩阵乘法解决的经典题目
矩阵快速幂——进阶
上一篇文章讲解了下基于斐波那契数列的矩阵快速幂,即F(n) = F(n-1) + F(n-2),转移矩阵比较简单。这里介绍一个比较复杂的,递推公式为非线性的例子,着重讲一下求解转移矩阵和应用转移矩阵的过程
准备问题
讲算法肯定要有相应的OJ,这里附上一道题,HDU5950
简单讲解下题意。F(n) = F(n-1) + 2F(n-2) + n4,且F(1) = a , F(2) = b,求F(n)%2147493647,其中a、b、n是待输入的参数
我们把解决这类题目的过程分解为如下步骤:
1. 把非线性递推式转化为线性递推式(线性递推式可忽略第一步)
2. 根据线性递推式得到F(n)和F(n+1)的矩阵序列
3. 根据F(n)和F(n+1)的矩阵序列得到中间的转移矩阵
4. 根据转移矩阵编写代码分步拆解问题
首先把非线性递推式转换为线性递推式
∵ (n+1)4 = n4 + 4n3 + 6n2 + 4n + n0
∵ F(n+1) = F(n) + 2F(n-1) + (n+1)4
∴ F(n+1) = F(n) + 2F(n-1) + n4 + 4n3 + 6n2 + 4n + n0
然后我们看下下面的状态转移矩阵

图(1)左边的矩阵表示F(n)项的矩阵,右边的矩阵表示F(n+1)项的矩阵。而中间的A矩阵就是需要求的转移矩阵。图(1)左边的矩阵怎么得到?我们看刚才得到的递归式
F(n+1) = F(n) + 2F(n-1) + n4 + 4n3 + 6n2 + 4n + n0
我们把F(n)放在矩阵顶部,表示第n项的值,然后剩下的元素F(n-1)、 n4、n3、n2、n、 n0 ,去掉系数后与F(n)一起构成一个矩阵。同理,F(n+1)的矩阵也是F(n+1)在顶部,表示第n+1项的值,然后剩下的元素F(n)、 (n+1)4、(n+1)3、(n+1)2、(n+1)、 (n+1)0 去掉系数后与F(n+1)构成一个矩阵。
好,我们现在得到了F(n)和F(n+1)的矩阵,那怎么求转移过去的矩阵A呢?首先,A是一个7×7的矩阵,且根据矩阵相乘规则,可以得到矩阵A,如下图(如果对矩阵相乘不熟悉的可以先看一下矩阵相乘哈)

好了,到现在为止,得到了图(2)的转移矩阵后,我们解决了前三步,还剩最后一步。怎么把这个转移矩阵应用到代码里面呢?
题中给出了F(1) = a,F(2) = b
所以F(3) = 2a + b + 34 = 2a + b + 24 + 4×23 + 6×22 + 4×21 + 20

为了表述方便。图(3)乘号左边的我们称为转移矩阵A,乘号右边的四个矩阵分别为B2、B3、B4、B5……
且我们可以得到的信息有
B2 × A = B3、B3 × A = B4、B4 × A = B5 ……
B2 × A2 = B4、B2 × A3 = B5、B2 × A4 = B6 ……
然后我们惊奇的发现:B2 × An-2 = Bn(fn)
B2的数据都是已知的,所以现在我们需要得到的只是An-2的数据,在 上一篇文章中,我们需要得到的是An的矩阵,代码问题就解决了吧。
再炒一下上一篇文章的冷饭,本来是根据B2->B3->B4->B5->……->Bn逐步递推得到Bn。现在我们转化为矩阵后,需要求的是A^(n-2)的数据,比如要求A^16,那我就可以直接通过快速幂A^1->A^2->A^4->A^8->A^16来得到了,复杂度由O(n)转化成了O(logn)
完整代码
#include <iostream>
using namespace std;
const long long int N = 2147493647; //注意要用 long long int
void Matrix(long long int (&a)[7][7],long long int b[7][7]){ //还是一样的函数
long long int tmp[7][7] = {0};
for(int i = 0; i < 7; ++i)
for(int j = 0; j < 7; ++j)
for(int k = 0; k < 7; ++k)
tmp[i][j] = (tmp[i][j] + a[i][k] * b[k][j]) % N;
for(int i = 0; i < 7; ++i)
for(int j = 0; j < 7; ++j)
a[i][j] = tmp[i][j];
}
int main(int argc, const char * argv[]) {
long long int sum,T,a,b,n;
cin>>T;
while(T--){
cin>>n>>a>>b;
if(n==1){
cout<<a<<endl;
continue;
}
//为了方便读者理解,直接这么定义矩阵了
long long int temp[7][7] = {1, 2, 1, 4, 6, 4, 1,
1, 0, 0, 0, 0, 0, 0,
0, 0, 1, 4, 6, 4, 1,
0, 0, 0, 1, 3, 3, 1,
0, 0, 0, 0, 1, 2, 1,
0, 0, 0, 0, 0, 1, 1,
0, 0, 0, 0, 0, 0, 1};
//temp表示的是A^n,cot表示的是最后的结果
long long int cot[7][7] = {1, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 1, 0,
0, 0, 0, 0, 0, 0, 1};
n -= 2;
while(n){ //还是这5行核心代码
if(n & 1) Matrix(cot,temp);
Matrix(temp,temp);
n /= 2;
}
sum = 0; //在得到A^(n-2)之后,还需要将B2*A^(n-2)得到Bn,而sum表示的是Bn的最顶部的元素值
sum = (sum + b*cot[0][0])%N;
sum = (sum + a*cot[0][1])%N;
sum = (sum + 16*cot[0][2])%N;
sum = (sum + 8*cot[0][3])%N;
sum = (sum + 4*cot[0][4])%N;
sum = (sum + 2*cot[0][5])%N;
sum = (sum + cot[0][6])%N;
cout<<sum<<endl;
}
return 0;
}较上篇文章,代码部分并没有多少变化,这篇文章着重讲了怎么根据递推公式求得转移方程并应用的过程。接下来可能会扩展一些矩阵快速幂的用法,比如不同的路径数量,行动方案等
以上是关于整数快速乘法/快速幂+矩阵快速幂+Strassen算法 (转)的主要内容,如果未能解决你的问题,请参考以下文章