Linux内核分析——第六周学习笔记20135308
Posted 一勺水也做了海
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux内核分析——第六周学习笔记20135308相关的知识,希望对你有一定的参考价值。
第五周 进程的描述和进程的创建
一、进程描述符task_struct数据结构
1.操作系统三大功能
- 进程管理
- 内存管理
- 文件系统
2.进程控制块PCB——task_struct
也叫进程描述符,为了管理进程,内核需要对每个进程进行描述,它就提供了内核所需了解的进程信息。
struct task_struct数据结构很庞大,1235行~1644行
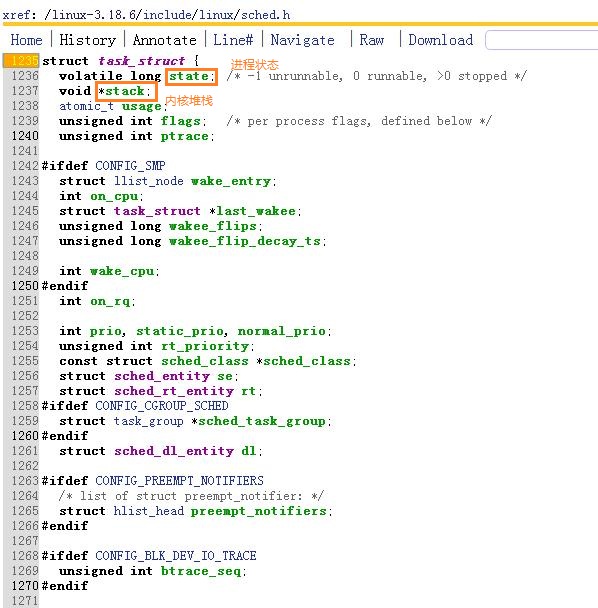
3.Linux进程状态
Linux进程的状态与操作系统原理中的描述的进程状态有所不同
操作系统状态:
- 就绪态
- 运行态
- 阻塞态
linux进程状态:
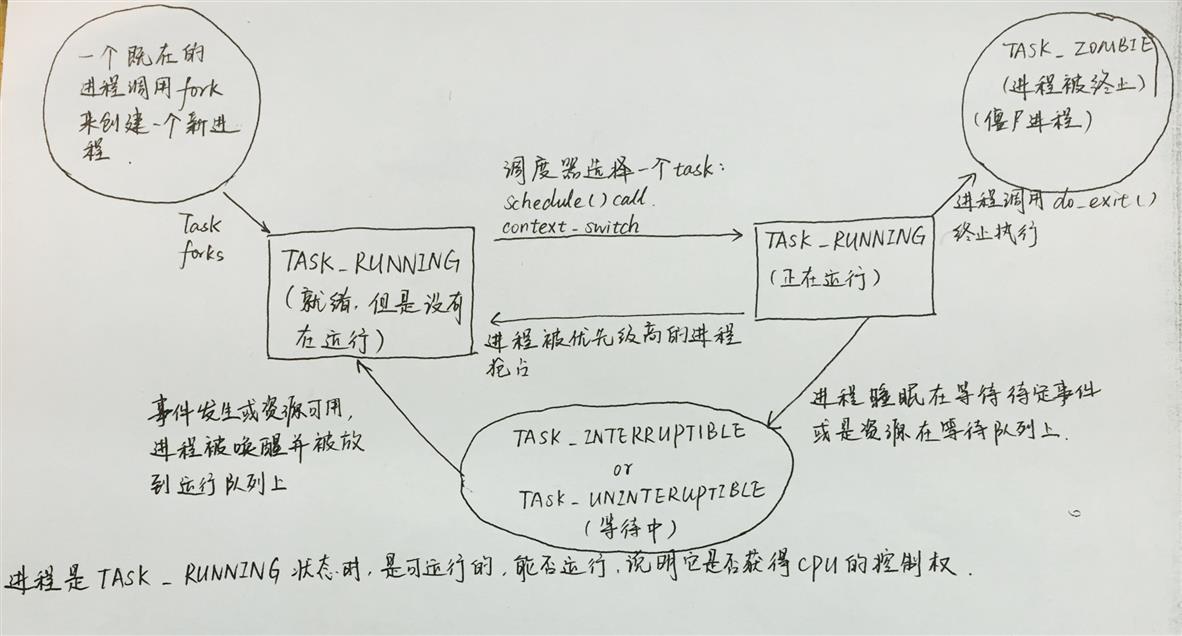
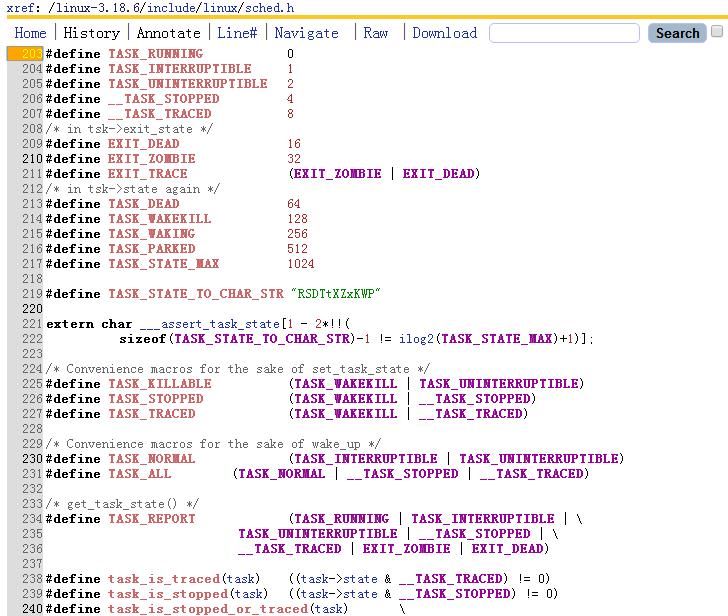
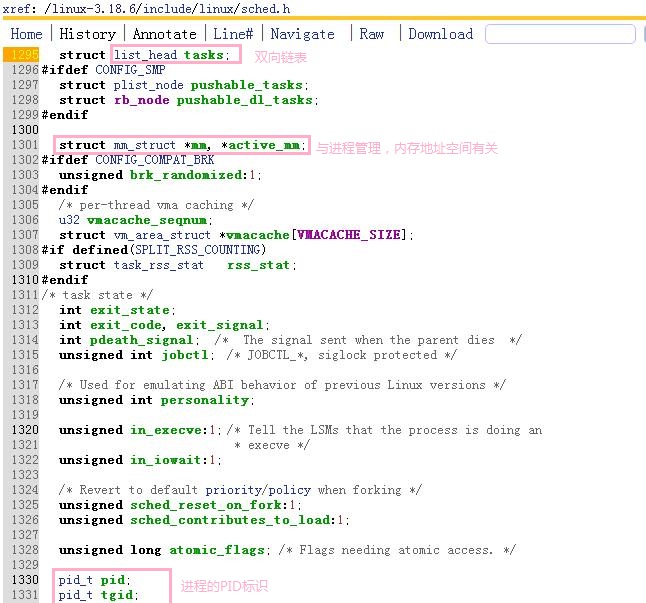
4.理解task_struct数据结构



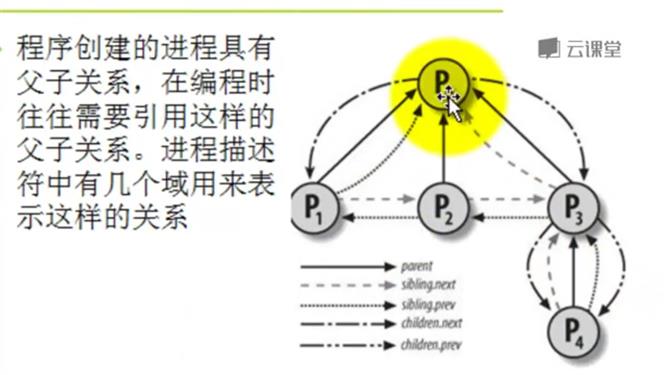
二、进程的创建
1.进程的创建概览及fork一个进程的用户态代码
(1)进程起源再回顾
start_kernel的最后rest_init里面创建了两个kernel_thread(内核线程)
- kernel_init用户态进程
- kthreadd所有内核线程的祖先

以上创建过程与我们在shell命令行下启动一个进程,创建过程本质上是一样的。
(2)复制一份进程描述符
其实0号进程是手工写入它的进程描述符数据,1号进程的创建是复制了0号进程的PCB,根据1号进程的需要,修改PID,加载一个init可执行程序。
进程是怎么创建起来的?
fork一个子进程的代码
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc, char * argv[]) { int pid; /* fork another process */ pid = fork(); //用于在用户态创建一个子进程的系统调用 if (pid < 0) //出错处理,之后两个都不会执行 { /* error occurred */ fprintf(stderr,"Fork Failed!"); exit(-1); } else if (pid == 0) //这里pid=0,下面两个都会执行。因为fork系统调用在父进程和子进程各返回一次 { /* child process */ printf("This is Child Process!\n"); } else { /* parent process */ printf("This is Parent Process!\n"); /* parent will wait for the child to complete*/ wait(NULL); printf("Child Complete!\n"); } }
2.理解进程创建过程复杂代码的方法
(1)系统调用再回顾
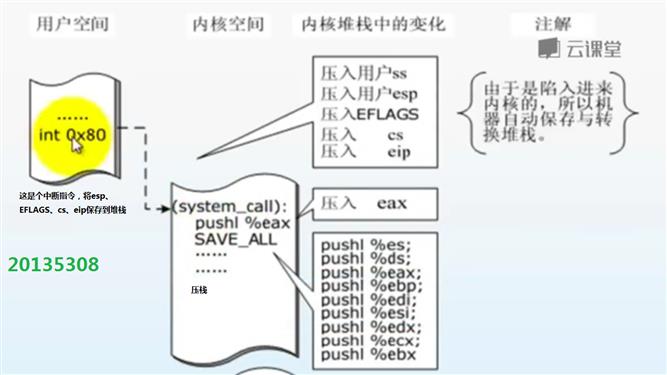
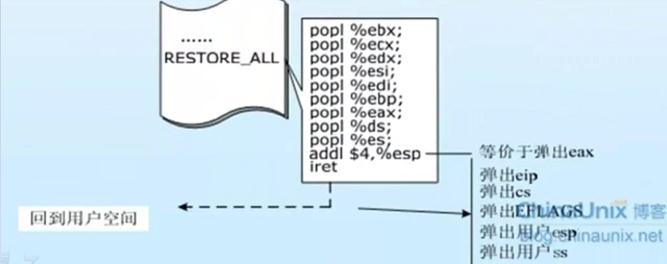
(2)创建一个新进程在内核中的执行过程
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建。
Linux通过复制父进程来创建一个新进程,那么这就给我们理解这一个过程提供一个想象的框架:
- 复制一个PCB——task_struct
$ err = arch_dup_task_struct(tsk, orig); //在这个函数复制父进程的数据结构
- 要给新进程分配一个新的内核堆栈
$ ti = alloc_thread_info_node(tsk, node); $ tsk->stack = ti; //复制内核堆栈 $ setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
- 要修改复制过来的进程数据,比如pid、进程链表等等都要改改,见copy_process内部。
- 从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回。那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
$ *childregs = *current_pt_regs(); //复制内核堆栈 $ childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因 $ p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶 $ p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
三、实验
1.删除menu,clone一份新的menu,把test_fork.c和test.c覆盖掉,重新执行make rootfs
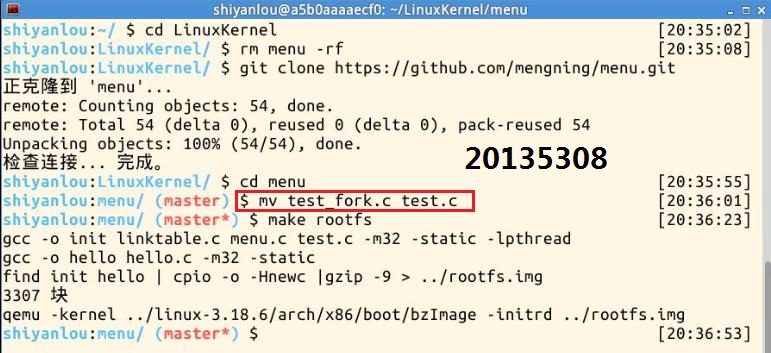
我们发现多了fork功能
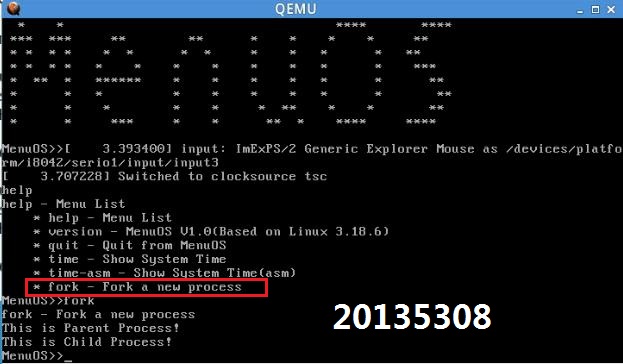
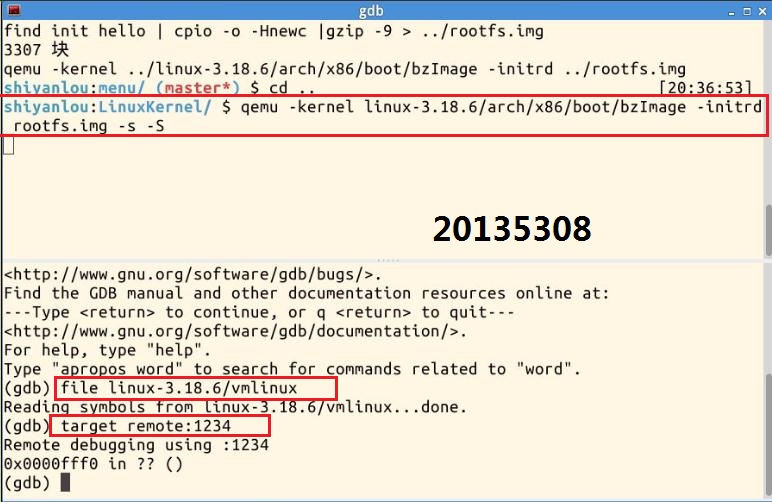
2.与之前相同,启动gdb
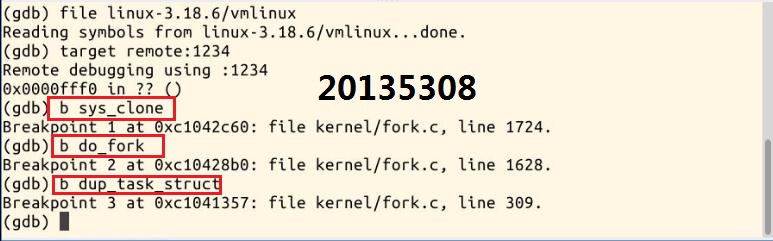
3.因为fork实际执行的是clone,所以在sys_clone这里设置断点,以及其他关键地方
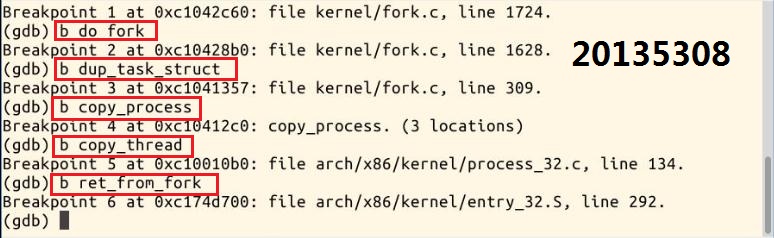
4.继续执行,停在了do_fork的位置
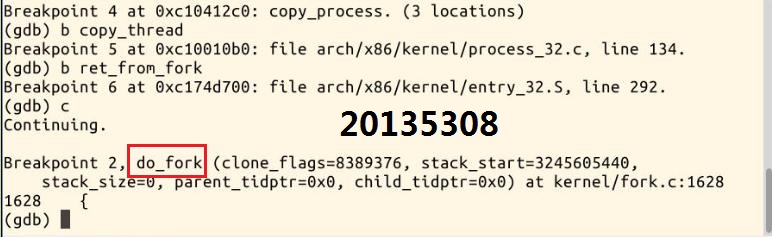
5.next……接下来是一些出错处理,直到copy_process
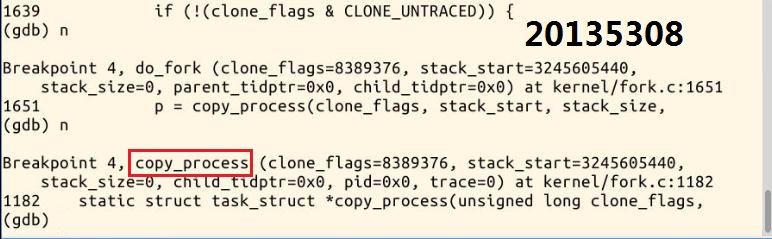
6.继续单步执行,程序停在了dup_task_struct函数处,现在已经把父进程的PCB,也就是task_struct数据结构复制过来了,也就是由p所指向的子进程的PCB
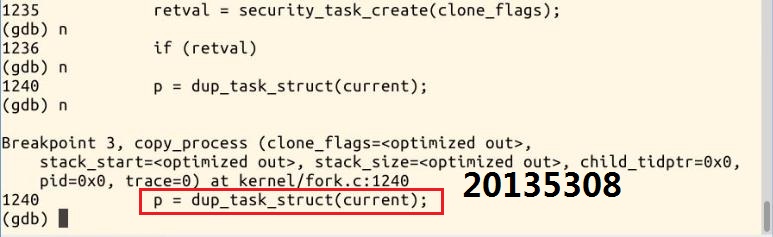
进去,发现
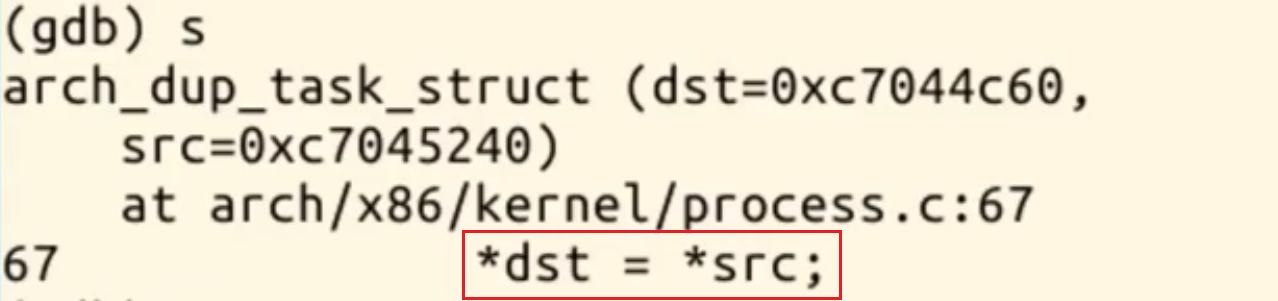
7.在copy_thread函数,next,从这里可以看到,从子进程的pid,也就是内核堆栈的位置,找到了栈空间,SAVE_ALL的一些内容,SAVE_ALL的地址
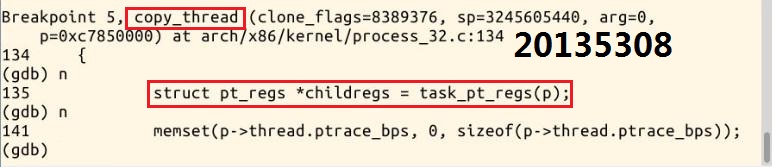
找到其压栈地址
8.当前进程的内核堆栈寄存器中的值复制到子进程中

9.设置子进程被调度的起点

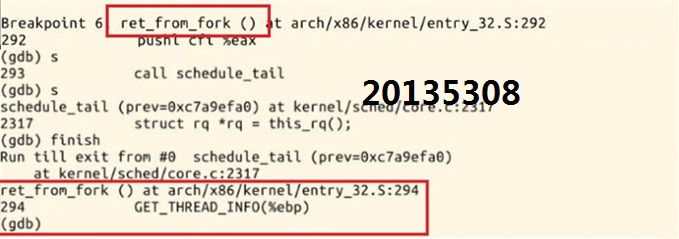
10.对ret_from_fork继续执行单步调试,当前系统执行的是汇编代码。
.
11.当程序跳转到syscall_exit处后,就不能再继续gdb跟踪调试了
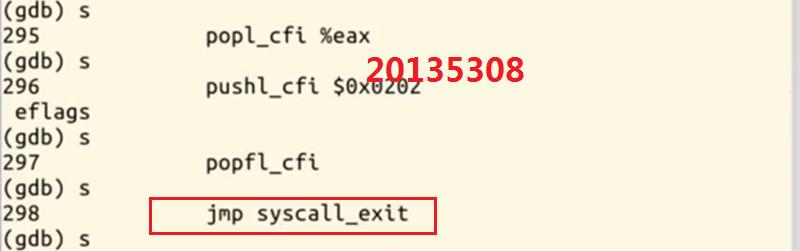
四、总结
1.Linux通过复制父进程来创建一个新进程,通过调用do_fork来实现
2.Linux为每个新创建的进程动态地分配一个task_struct结构.
3.为了把内核中的所有进程组织起来,Linux提供了几种组织方式,其中哈希表和双向循环链表方式是针对系统中的所有进程(包括内核线程),而运行队列和等待队列是把处于同一状态的进程组织起来
4.fork()函数被调用一次,但返回两次
创建一个新进程在内核中的执行过程
- 不论是使用 fork 还是 vfork 来创建进程,最终都是通过 do_fork() 方法来实现的
- 调用copy_process,复制一个PCB——task_struct,给新进程分配一个新的内核堆栈
- 修改复制过来的进程数据,比如pid、进程链表等等都要改改
- fork()函数在父子进程中各返回一次,
以上是关于Linux内核分析——第六周学习笔记20135308的主要内容,如果未能解决你的问题,请参考以下文章