Selenium中如何使用xpath更快定位
Posted G2Bent
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium中如何使用xpath更快定位相关的知识,希望对你有一定的参考价值。
在学习Selenium路上,踩了也不少坑,这是我最近才发现的一个新写法,好吧,"才发现"又说明我做其他事了。对的,我现在还在加班!
开车~~~
例子:知乎网
标签:Python3.6,Selenium
1、通常我们使用xpath的时候,我们会通过Chrome或者Firefox中自带的定位提示,复制粘贴到我们的脚本中去。这是新手最喜欢做的事了。
现在我们要改变那种习惯,在一些没必要的时候,就不要复制粘贴了
我们尝试复制粘贴的xpath方式登录知乎:

我们看到,每一个xpath定位的元素都是很长很长,这样会给我们带来视觉的不舒服,而且这样可以看出,复制的xpath就是复制源码的路径,没有太多的技术性
2、现在我们根据xpath语法对定位元素进行修改:
我们先去看一下知乎登录网页的源码是怎样的吧
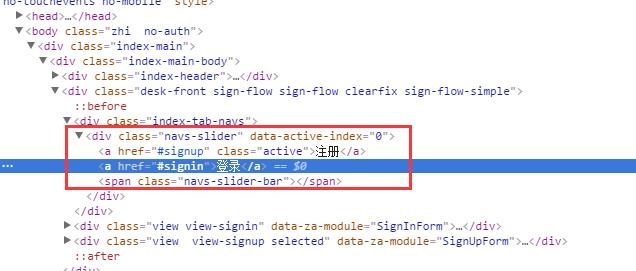
登录这个元素是在一个div(class="navs-slider")下的<a>标签下的,这样我们就可以直接通过class name找到“登录”元素了。
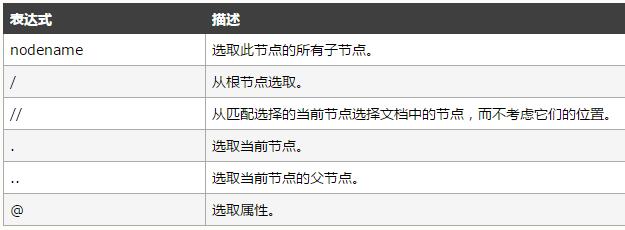
我们根据xpath的语法书写://*[@这里写class name]
想知道更多语法,可以去w3cshool了解 http://www.w3school.com.cn/xpath/xpath_syntax.asp
这样一写,我们就可以简化我们的例子了
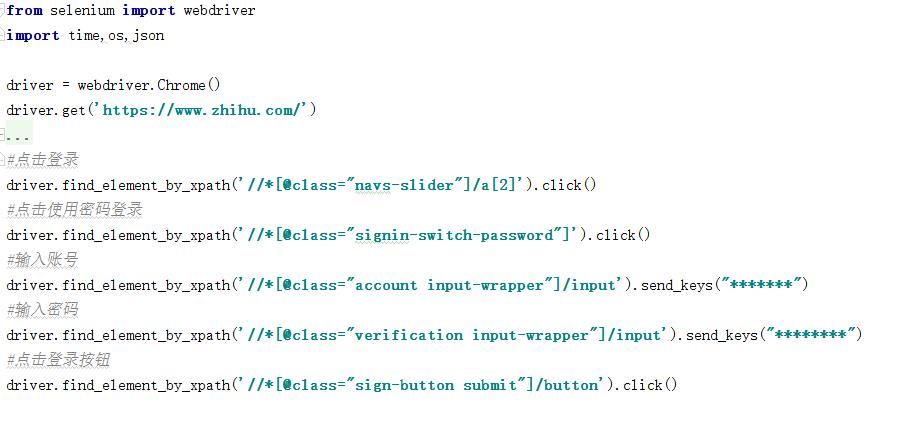
写出来就高大上好多了。
我们这样写,是找到元素的上一级的class name来定位我们需要的元素,这样就简化了很多代码,减少我们的代码量了,同时也不会看到每定位一个元素就要一大行代码了。
以上是关于Selenium中如何使用xpath更快定位的主要内容,如果未能解决你的问题,请参考以下文章
Selenium2+Python3.6实战:定位下拉菜单出错,如何解决?用select或xpath定位。
如何使用 Xpath、css 或 Selenium 中的任何其他定位器在 html 中的结束标记后查找带有“== $0”的元素