数据结构与算法(周鹏-未出版)-第六章 树-6.5 Huffman 树
Posted crazyYong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法(周鹏-未出版)-第六章 树-6.5 Huffman 树相关的知识,希望对你有一定的参考价值。
6.5 Huffman 树
Huffman 树又称最优树,可以用来构造最优编码,用于信息传输、数据压缩等方面,是一类有着广泛应用的二叉树。
6.5.1 二叉编码树
在计算机系统中,符号数据在处理之前首先需要对符号进行二进制编码。例如,在计算机中使用的英文字符的 ASCII 编码就是 8 位二进制编码,由于 ASCII 码使用固定长度的二进制位表示字符,因此 ASCII 码是一种定长编码。为了缩短数据编码长度,可以采用不定长编码。其基本思想是:给使用频度较高的字符编较短的编码,这是数据压缩技术的最基本思想。如何给数据中的字符编以不定长编码,而使数据编码的平均长度最短呢?
首先分析第一个问题:如何对字符集进行不定长编码。在一个编码系统中,任何一个编码都不是其他编码的前缀,则称该编码系统的编码是前缀码。例如: 01, 10, 110, 111, 101 就不是前缀编码,因为 10 是 101 的前缀,如果去掉 10 或101 就是前缀编码。当在一个编码系统中采用定长编码时,可以不需要分隔符;如果采用不是前缀编码,因为 10 是 101 的前缀,如果去掉 10 或101 就是前缀编码。当在一个编码系统中采用定长编码时,可以不需要分隔符;如果采用不定长编码时,必须使用前缀编码或分隔符,否则在解码时会产生歧义。所谓解码就是由二进制位串还原字符数据的过程。而使用分隔符会加大编码长度,因此一般采用前缀编码。例 6-1 说明了这个问题。
例 6-1 假设字符集为{A, B, C, D},原文为 ABACCDA。
一种等长编码方案为 A:00 B:01 C:10 D:11,此时编解码不会产生歧义,过程如下。
编码: ABACCDA → 00010010101100
解码: 00010010101100 → ABACCDA
一种不等长编码方案为: A:0 B:00 C:1 D:01,由于此编码不是前缀码,此时在编解码的过程中会产生歧义。对于同一编码可以有不同的解码,过程如下。
编码: ABACCDA → 000011010
解码: 000011010 → AAAACCDA
000011010 → BBCCDA 错误!出现歧义。
为产生没有歧义的前缀编码,可以使用二叉编码树来实现。使用二叉树对字符集中的字符进行编码的方法是,将字符集中的所有字符作为二叉树的叶子结点;在二叉树中,每一个“父亲—左孩子”关系对应一位二进制位 0,每一个“父亲—右孩子”关系对应一位二进制位 1 ;于是从根结点通往每个叶子结点的路径,就对应于相应字符的二进制编码。每个字符编码的长度 L 等于对应路径的长度,也等于该叶子结点的层次数。例如对于例 6-1 中的每个字符可以按照图 6-15 所示的二叉编码树
进行编码。按照图 6-15 中的二叉编码树对 A、 B、 C、 D 四个字符进行编码,则 A 的编码是 0, B 的编码是 100, C 的编码是 11 , D的编码是 101。这个编码显然是一个前缀编码。

由于在二叉树中任何一个叶子结点都不会出现在根到其他叶子结点的路径上,那么按照上述二叉编码树的编码方法,任何一个叶子结点表示的编码都不会是任何其他叶子表示编码的前缀,因此由二叉编码树得到的编码都是前缀码。反过来如果要进行解码,也可以由二叉编码树便捷的完成。解码的过程是从头开始扫描二进制编码位串,并从二叉编码树的根结点开始,根据比特位不断进入下一层结点,当碰到0 时向左深入,为 1 时向右深入;到达叶子结点后输出其对应的字符,然后重新回到根结点,并继续扫描二进制位串直到完毕。还是如图 6-15 所示,此时将 ABACCDA 进行编码得到: 0100011111010。解码过程是从左到右扫描二进制位串。在读出最前端的 0 后,相应的从根结点到达结点,于是输出 A,重新回到根结点;依次扫描后续二进制位 100,到达叶子结点 B,于是输出 B,重新回到根结点;读出下一个二进制位 0,输出 A;读出 11 ,输出 C;读出 11 ,输出 C;读出 101,输出 D;最后读出 0,输出 A;此时二进制位串扫描完毕,相应的解码工作也完成,最后得到字符数据 ABACCDA。
6.5.2 Huffman 树及 Huffman 编码
在上一小节中介绍了如何对字符集进行不定长编码的方法,但是同时我们看到对于同一个字符集进行编码的二叉编码树可以有很多,只要叶子结点个数与字符个数对应即可。例如
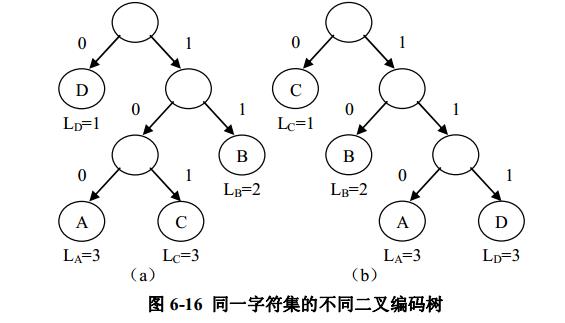
对例 6-1 中字符即进行编码的二叉树就可以有,但不限于图 6-16 所示的二叉树。在这些不同的编码中哪个才是使得编码长度最小的呢?例如在例 6-1 中,选择图 6-15 中的编码方案比选择图 6-16 中的两种编码方案好。由于
字符 A、 B、 C、 D 分别出现了 3 次、 1 次、2 次、 1 次。使用图 6-15 的编码方案,编码的长度为 3×1+1×3+2×2+1×3=13;使用图 6-16( a)的编码方案,编码的长度为 3×3+1×2+2×3+1×1
=18;使用图 6-16( b)的编码方案,编码的长度为 3×3+1×2+2×1+1×3=16。
字符集中各种字符出现的概率是不同的,字符的出现概率决定了编码方案的选择。

当引入以上概念以后,求最佳编码方案实际上就抽象为求在叶子结点个数与权确定时带权路径长度最小的二叉树。那么什么样的树带权路径长度最小呢?
对于给定n个权值w1, w2, … wn( n≥2),求一棵具有n个叶子结点的二叉树,使其带权路径长度∑ WiLi最小。由于Huffman给出了构造具有这种树的方法,因此这种树称为Huffman树。
Huffman 树: 它是由 n 个带权叶子结点构成的所有二叉树中带权路径长度最小的二叉树, Huffman 树又称最优二叉树。