Hive中的桶表入门(适用于抽样查询)
Posted fee先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive中的桶表入门(适用于抽样查询)相关的知识,希望对你有一定的参考价值。
1、基本概念
(1)桶表是对某一列数据进行哈希取值以将数据打散,然后放到不同文件中存储。
(2)在hive分区表中,分区中的数据量过于庞大时,建议使用桶。
(3)在分桶时,对指定字段的值进行hash运算得到hash值,并使用hash值除以桶的个数做取余运算得到的值进行分桶,保证每个桶中有数据但每个桶中的数据不一定相等。
做hash运算时,hash函数的选择取决于分桶字段的数据类型
(4)分桶后的查询效率比分区后的查询效率更高
2、桶表的创建
create table btable1 (id int) clustered by(id) into 4 buckets;
创建只有一个字段(id)的桶表,按照id分桶,分为4个bucket,而bucket的数量等于实际数据插入中reduce的数量。
3、间接加载数据
桶表不能通过load的方式直接加载数据,只能从另一张表中插入数据
4、操作示例
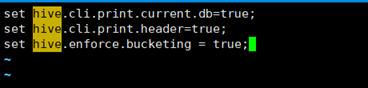
(1)环境配置,使hive能够识别桶
必须按照如下配置: vim ~/.hiverc 添加:set hive.enforce.bucketing = true;
(2)创建桶表
create table btable1 (id int) clustered by(id) into 4 buckets;
(3)创建中间过渡表并为其加载数据
create table btest2(id int); load data local inpath \'btest2\' into table btest2;
(4)桶表的数据插入
insert into table btest1 select * from btest2;
(5)修改桶表中bueket数量
alter table btest3 clustered by(name,age) sorted by(age) into 10 buckets;
(6)Hive中的抽样查询
select * from table_name tablesample(bucket X out of Y on field);
X表示从哪个桶中开始抽取,Y表示相隔多少个桶再次抽取。
Y必须为分桶数量的倍数或者因子,比如分桶数为6,Y为6,则表示只从桶中抽取1个bucket的数据;若Y为3,则表示从桶中抽取6/3(2)个bucket的数据
create table bkt(name string,id string,phone string,card_num bigint,email string,addr string) clustered by(card_num) into 30 buckets; create table bak(name string,id string,phone string,card_num bigint,email string,addr string) row format delimited fields terminated by \',\' load data local inpath \'/home/xfvm/bak\' into table bak; insert into table bkt select * from bak;
示例:
select * from bkt tablesample(bucket 2 out of 6 on card_num)
表示从桶中抽取5(30/6)个bucket数据,从第2个bucket开始抽取,抽取的个数由每个桶中的数据量决定。相隔6个桶再次抽取,因此,依次抽取的桶为:2,8,14,20,26
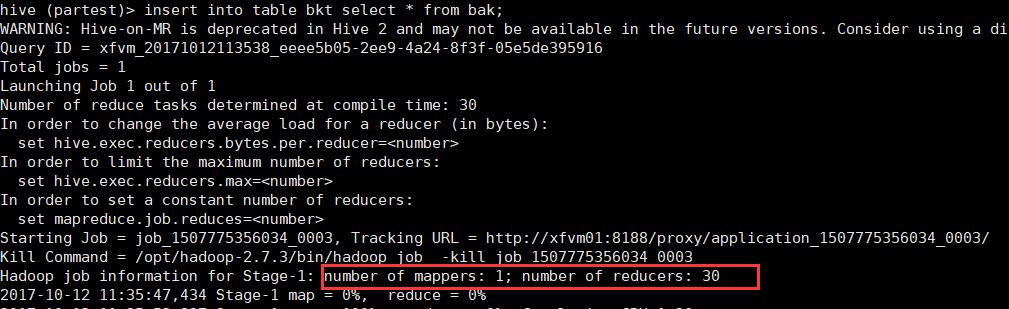
注意:执行数据插入时,reduce数量等于分桶数量
5、Hive中的视图(按需查询,提高查询效率)
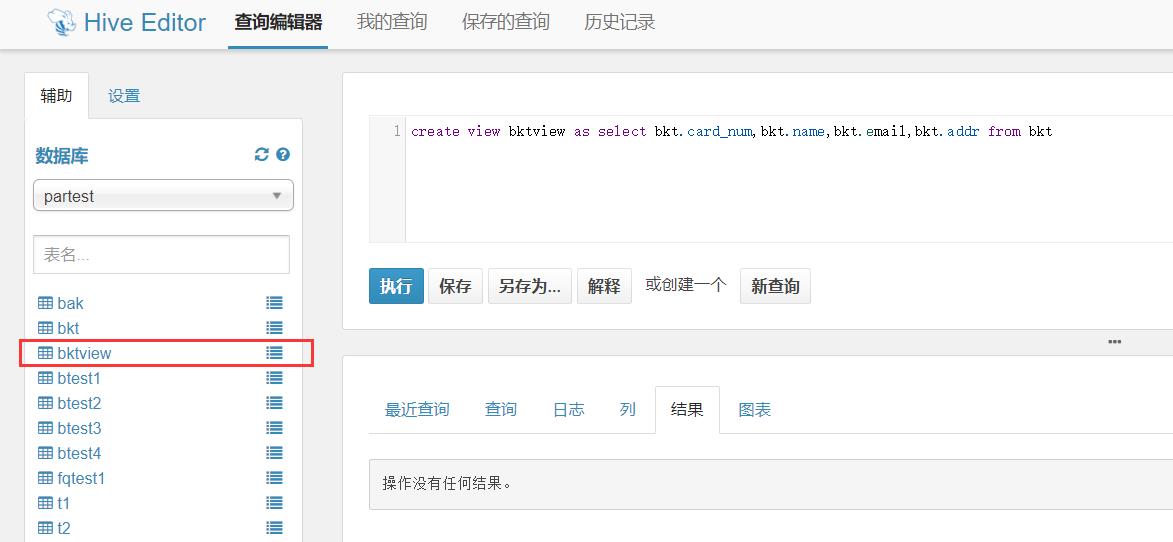
创建视图时只是创建一个与源表的映射,视图中的字段由用户按需决定。
create view bktview as select bkt.card_num,bkt.name,bkt.email,bkt.addr from bkt
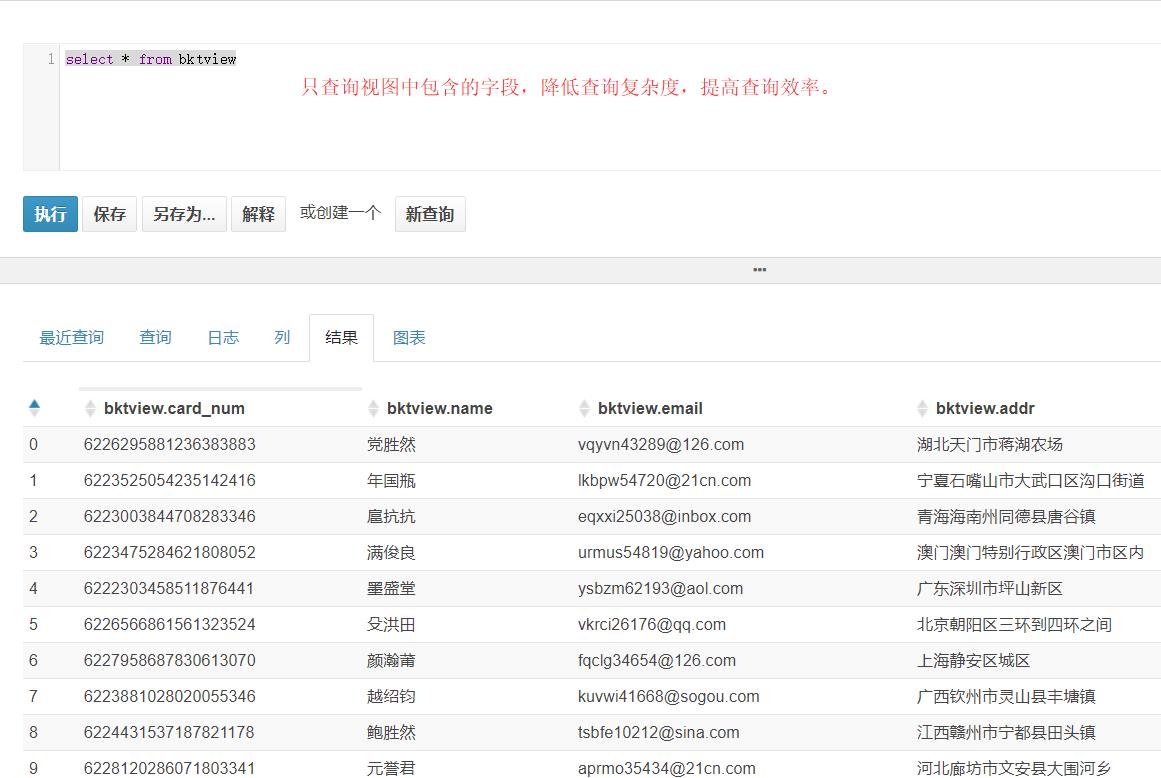
视图的查询结果,数据实际上仍然存放在源表中。
以上是关于Hive中的桶表入门(适用于抽样查询)的主要内容,如果未能解决你的问题,请参考以下文章