java对象序列化反序列化
Posted 人,总要有点追求的
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java对象序列化反序列化相关的知识,希望对你有一定的参考价值。
平时我们在Java内存中的对象,是无法进行IO操作或者网络通信的,因为在进行IO操作或者网络通信的时候,人家根本不知道内存中的对象是个什么东西,因此必须将对象以某种方式表示出来,即存储对象中的状态。一个Java对象的表示有各种各样的方式,Java本身也提供给了用户一种表示对象的方式,那就是序列化。换句话说,序列化只是表示对象的一种方式而已。OK,有了序列化,那么必然有反序列化,我们先看一下序列化、反序列化是什么意思。
序列化:将一个对象转换成一串二进制表示的字节数组,通过保存或转移这些字节数据来达到持久化的目的。
反序列化:将字节数组重新构造成对象。
默认序列化
序列化只需要实现java.io.Serializable接口就可以了。序列化的时候有一个serialVersionUID参数,Java序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化,Java虚拟机会把传过来的字节流中的serialVersionUID和本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的实体类,可以进行反序列化,否则Java虚拟机会拒绝对这个实体类进行反序列化并抛出异常。serialVersionUID有两种生成方式:
1、默认的1L
2、根据类名、接口名、成员方法以及属性等来生成一个64位的Hash字段
如果实现java.io.Serializable接口的实体类没有显式定义一个名为serialVersionUID、类型为long的变量时,Java序列化机制会根据编译的.class文件自动生成一个serialVersionUID,如果.class文件没有变化,那么就算编译再多次,serialVersionUID也不会变化。换言之,Java为用户定义了默认的序列化、反序列化方法,其实就是ObjectOutputStream的defaultWriteObject方法和ObjectInputStream的defaultReadObject方法。看一个例子:

1 public class SerializableObject implements Serializable
2 {
3 private static final long serialVersionUID = 1L;
4
5 private String str0;
6 private transient String str1;
7 private static String str2 = "abc";
8
9 public SerializableObject(String str0, String str1)
10 {
11 this.str0 = str0;
12 this.str1 = str1;
13 }
14
15 public String getStr0()
16 {
17 return str0;
18 }
19
20 public String getStr1()
21 {
22 return str1;
23 }
24 }
1 public static void main(String[] args) throws Exception
2 {
3 File file = new File("D:" + File.separator + "s.txt");
4 OutputStream os = new FileOutputStream(file);
5 ObjectOutputStream oos = new ObjectOutputStream(os);
6 oos.writeObject(new SerializableObject("str0", "str1"));
7 oos.close();
8
9 InputStream is = new FileInputStream(file);
10 ObjectInputStream ois = new ObjectInputStream(is);
11 SerializableObject so = (SerializableObject)ois.readObject();
12 System.out.println("str0 = " + so.getStr0());
13 System.out.println("str1 = " + so.getStr1());
14 ois.close();
15 }
先不运行,用一个二进制查看器查看一下s.txt这个文件,并详细解释一下每一部分的内容。

第1部分是序列化文件头
◇AC ED:STREAM_MAGIC序列化协议
◇00 05:STREAM_VERSION序列化协议版本
◇73:TC_OBJECT声明这是一个新的对象
第2部分是要序列化的类的描述,在这里是SerializableObject类
◇72:TC_CLASSDESC声明这里开始一个新的class
◇00 1F:十进制的31,表示class名字的长度是31个字节
◇63 6F 6D ... 65 63 74:表示的是“com.xrq.test.SerializableObject”这一串字符,可以数一下确实是31个字节
◇00 00 00 00 00 00 00 01:SerialVersion,序列化ID,1
◇02:标记号,声明该对象支持序列化
◇00 01:该类所包含的域的个数为1个
第3部分是对象中各个属性项的描述
◇4C:字符"L",表示该属性是一个对象类型而不是一个基本类型
◇00 04:十进制的4,表示属性名的长度
◇73 74 72 30:字符串“str0”,属性名
◇74:TC_STRING,代表一个new String,用String来引用对象
第4部分是该对象父类的信息,如果没有父类就没有这部分。有父类和第2部分差不多
◇00 12:十进制的18,表示父类的长度
◇4C 6A 61 ... 6E 67 3B:“L/java/lang/String;”表示的是父类属性
◇78:TC_ENDBLOCKDATA,对象块结束的标志
◇70:TC_NULL,说明没有其他超类的标志
第5部分输出对象的属性项的实际值,如果属性项是一个对象,这里还将序列化这个对象,规则和第2部分一样
◇00 04:十进制的4,属性的长度
◇73 74 72 30:字符串“str0”,str0的属性值
从以上对于序列化后的二进制文件的解析,我们可以得出以下几个关键的结论:
1、序列化之后保存的是类的信息
2、被声明为transient的属性不会被序列化,这就是transient关键字的作用
3、被声明为static的属性不会被序列化,这个问题可以这么理解,序列化保存的是对象的状态,但是static修饰的变量是属于类的而不是属于变量的,因此序列化的时候不会序列化它
接下来运行一下上面的代码看一下
str0 = str0 str1 = null
因为str1是一个transient类型的变量,没有被序列化,因此反序列化出来也是没有任何内容的,显示的null,符合我们的结论。
手动指定序列化过程
Java并不强求用户非要使用默认的序列化方式,用户也可以按照自己的喜好自己指定自己想要的序列化方式----只要你自己能保证序列化前后能得到想要的数据就好了。手动指定序列化方式的规则是:
进行序列化、反序列化时,虚拟机会首先试图调用对象里的writeObject和readObject方法,进行用户自定义的序列化和反序列化。如果没有这样的方法,那么默认调用的是ObjectOutputStream的defaultWriteObject以及ObjectInputStream的defaultReadObject方法。换言之,利用自定义的writeObject方法和readObject方法,用户可以自己控制序列化和反序列化的过程。
这是非常有用的。比如:
1、有些场景下,某些字段我们并不想要使用Java提供给我们的序列化方式,而是想要以自定义的方式去序列化它,比如ArrayList的elementData、HashMap的table(至于为什么在之后写这两个类的时候会解释原因),就可以通过将这些字段声明为transient,然后在writeObject和readObject中去使用自己想要的方式去序列化它们
2、因为序列化并不安全,因此有些场景下我们需要对一些敏感字段进行加密再序列化,然后再反序列化的时候按照同样的方式进行解密,就在一定程度上保证了安全性了。要这么做,就必须自己写writeObject和readObject,writeObject方法在序列化前对字段加密,readObject方法在序列化之后对字段解密
上面的例子SerializObject这个类修改一下,主函数不需要修改:
1 public class SerializableObject implements Serializable
2 {
3 private static final long serialVersionUID = 1L;
4
5 private String str0;
6 private transient String str1;
7 private static String str2 = "abc";
8
9 public SerializableObject(String str0, String str1)
10 {
11 this.str0 = str0;
12 this.str1 = str1;
13 }
14
15 public String getStr0()
16 {
17 return str0;
18 }
19
20 public String getStr1()
21 {
22 return str1;
23 }
24
25 private void writeObject(java.io.ObjectOutputStream s) throws Exception
26 {
27 System.out.println("我想自己控制序列化的过程");
28 s.defaultWriteObject();
29 s.writeInt(str1.length());
30 for (int i = 0; i < str1.length(); i++)
31 s.writeChar(str1.charAt(i));
32 }
33
34 private void readObject(java.io.ObjectInputStream s) throws Exception
35 {
36 System.out.println("我想自己控制反序列化的过程");
37 s.defaultReadObject();
38 int length = s.readInt();
39 char[] cs = new char[length];
40 for (int i = 0; i < length; i++)
41 cs[i] = s.readChar();
42 str1 = new String(cs, 0, length);
43 }
44 }
直接看一下运行结果
我想自己控制序列化的过程 我想自己控制反序列化的过程 str0 = str0 str1 = str1
看到,程序走到了我们自己写的writeObject和readObject中,而且被transient修饰的str1也成功序列化、反序列化出来了----因为手动将str1写入了文件和从文件中读了出来。不妨再看一下s.txt文件的二进制:
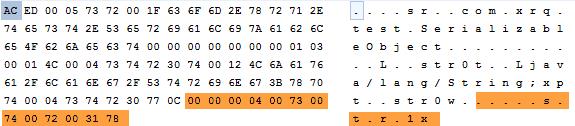
看到橘黄色的部分就是writeObject方法追加的str1的内容。至此,总结一下writeObject和readObject的通常用法:
先通过defaultWriteObject和defaultReadObject方法序列化、反序列化对象,然后在文件结尾追加需要额外序列化的内容/从文件的结尾读取额外需要读取的内容。
复杂序列化情况总结
虽然Java的序列化能够保证对象状态的持久保存,但是遇到一些对象结构复杂的情况还是比较难处理的,最后对一些复杂的对象情况作一个总结:
1、当父类继承Serializable接口时,所有子类都可以被序列化
2、子类实现了Serializable接口,父类没有,父类中的属性不能序列化(不报错,数据丢失),但是在子类中属性仍能正确序列化
3、如果序列化的属性是对象,则这个对象也必须实现Serializable接口,否则会报错
4、反序列化时,如果对象的属性有修改或删减,则修改的部分属性会丢失,但不会报错
5、反序列化时,如果serialVersionUID被修改,则反序列化时会失败
以上是关于java对象序列化反序列化的主要内容,如果未能解决你的问题,请参考以下文章