Zeppelin 学习笔记之 Zeppelin安装和elasticsearch整合
Posted AK47Sonic
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zeppelin 学习笔记之 Zeppelin安装和elasticsearch整合相关的知识,希望对你有一定的参考价值。
Zeppelin安装:
Apache Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化。背后可以接入不同的数据处理引擎,包括spark, hive, tajo等,原生支持scala, java, shell, markdown等。
http://zeppelin.apache.org
安装:
tar –zxvf zeppelin-0.7.3-bin-all.tgz
cd conf/
mv zeppelin-env.sh.template zeppelin-env.sh
修改:
export JAVA_HOME=/usr/java/jdk1.8.0_144
mv zeppelin-site.xml.template zeppelin-site.xml
修改:
<property> <name>zeppelin.server.port</name> <value>8089</value> <description>Server port.</description> </property>
这次先不配置Spark,由于最新在学习ELK,就先拿elasticsearch作为例子。
进入zeppelin/bin启动:
zeppelin-daemon.sh start
访问:hadoop1:8089

创建新note:(选择elasticsearch)

测试elastisearch:
很不幸,测试失败,没有连通。
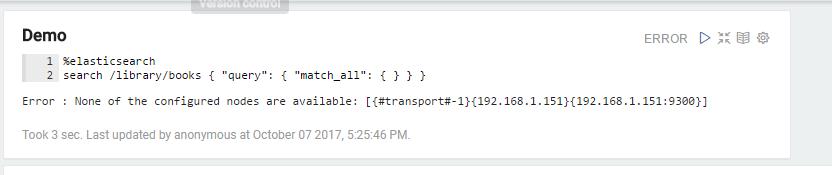
查看日志发现:Zeppelin还没有支持elasticsearch5,汗汗汗

修改连接方式,再试试:

transport->http
9300->9200

再次查询:
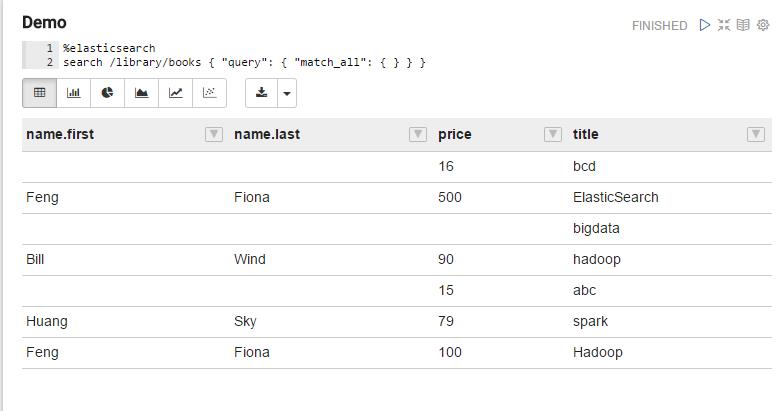
数据出来了,搞定!
以上是关于Zeppelin 学习笔记之 Zeppelin安装和elasticsearch整合的主要内容,如果未能解决你的问题,请参考以下文章
Zeppelin部署 01Zeppelin最新版本zeppelin-0.10.1下载安装配置启动及问题处理(一篇学会部署Zeppelin)