机器学习day12 机器学习实战adaboost集成方法与重新进行疝马病的预测
Posted flowertree花树
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习day12 机器学习实战adaboost集成方法与重新进行疝马病的预测相关的知识,希望对你有一定的参考价值。
今天终于完成了分类器的学习,SVM基本不怎么会,很是头疼,先放一下吧,有机会问问大神讲解一下。接下来的几天进行监督学习回归部分的学习,先看看adaboost的理解。
我们再决定一个重要的事情时,往往不是听取一个人的意见,听取大家的意见,然后投票表决最终结果。这一个特点也可以应用于机器学习的算法中来,每一个人都是弱的分类器,若是指一个人的力量很小,很多人汇集在一起就构成了强分类器。好比政府的投票系统。
有一个有趣的现象,若每个人都有51%的几率选择正确,则汇集很多人的投票信息之后选择正确的人比选择错误的人多很多,我们认为多数人的选择是正确的,选择错误的人很难扳回来,因为差的人数太多了,投票的人越多,这种现象越得到加强。9个人选A,11个人选B,A和B没什么区别,9000个人选A,11000个人选B,这样A和B就差很多了,我们认为B是正确的。多个弱分类器好比多个人,分类器越多分类结果越得到加强,这样就解释了多个弱分类器可以构成强分类器。
对一组训练样本分类N次,每一次结合更新的权值。
每次听取一个分类器的意见和比重alpha的乘积,最后N个分类器的意见听取结束后最终结果作为预测结果。
每一个阈值分类器为低级分类器,每个循环选择最佳阈值分类器。
算法关键流程(写一点关键步骤,详细步骤参见博客http://www.csdn123.com/html/topnews201408/87/6287.htm或者搜索adaboost的原理与推导):
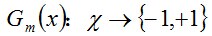 每一轮最佳阈值分类器
每一轮最佳阈值分类器
误差率就是被选错的样本权值之和,选择一个误差率最小的,并且误差率高于50%的不要。
然后计算这个阈值分类器在最终分类器中的权重
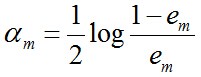
em越大am越小,说明不好的分类器所占权重越小。
然后更新每个样本的权值
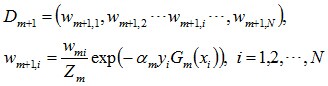
接下来上代码:
step1:
读取简单测试数据:
#读取简单数据
def loadData():
datamat = matrix([[1, 2.1],
[2, 1.1],
[1.3, 1],
[1, 1],
[2, 1]])
lavels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datamat, lavelsstep2:
单层决策树的阈值分类器分类函数和分类器选择函数:
#弱分类器分类函数
#参数:数据集 特性所在列 特性阈值 分类值为1或-1
def lowType(Data, x, num, t):
res = ones((Data.shape[0], 1))
if t == 'less':
res[Data[ : ,x] <= num] = -1
else:
res[Data[ : ,x] > num] = -1
return res
#训练一个低级分类器,从多个弱分类器中选出误差值最小的
def trainClassify(datas, lavel, D):
Datamat = mat(datas)
Lavels = mat(lavel).T
m ,n = shape(Datamat)
best = {}
bestlavels = mat(ones((m, 1)))
step = 10.0
minerror = inf
for i in range(n):
minnum = Datamat[ : , i].min()
maxnum = Datamat[ : , i].max()
times = (maxnum - minnum) / step
for j in range(-1, int(step) + 1):
number = minnum + j * times
for k in ['less', 'large']:
r = lowType(Datamat, i, number, k)
error = mat(ones((m, 1)))
error[r == Lavels] = 0
weights = error.T * D
print "特性行:%d 特性分类值:%f 特性值选择方式:%s 误差值%f"% (i, number, k, weights)
if weights < minerror:
minerror = weights
bestlavels = r.copy()
best['row'] = i
best['number'] = number
best['types'] = k
return best, minerror, bestlavelsstep3:
adaboost训练器,每次训练一个弱分类器直到误差率0或次数限制
#adaboost训练器
def adaboostTrain(dataset, lavels, cycle = 40):
adaboost = []
m, n = shape(dataset)
D = mat(ones((m, 1)) / m)
lastlavels = zeros((m ,1))
for i in range(cycle):
temp, temperror, templavels = trainClassify(dataset, lavels, D)
print "D:", D.T
alpha = float(0.5 * log((1.0 - temperror) / max(temperror, 1e-16)))
temp['alpha'] = alpha
adaboost.append(temp)
print "第%d次预测的结果:"%(i + 1), templavels.T
e = multiply(-1 * alpha * mat(lavels).T, templavels)
D = multiply(D, exp(e))
D = D / D.sum()
lastlavels += alpha * templavels
print "高级分类器的结果:", lastlavels.T
lasterror = multiply(sign(lastlavels) != mat(lavels).T, ones((m, 1)))
errorRate = lasterror.sum() / m
print "错误率为%f"%(errorRate)
if errorRate == 0.0:
break
return adabooststep4:
把训练出来的分类器用于分类测试
#分类预测,参数为测试数据和adaboost分类器
def adaboostClassify(testdata, adaboost):
testmat = mat(testdata)
m = shape(testmat)[0]
classifylavels = zeros((m, 1))
for i in range(len(adaboost)):
templavels = lowType(testmat, adaboost[i]['row'], adaboost[i]['number'], adaboost[i]['types'])
classifylavels += adaboost[i]['alpha'] * templavels
print classifylavels
return sign(classifylavels) 到此为止,训练器完成,我们应用与LR中疝马病的预测的难数据集实验以下效果
step5:
读取疝马病数据:
#数据加载函数
def loadDataSet(filename):
featruenum = len(open(filename).readline().split('\t'))
f = open(filename)
data = []
l = []
for i in f.readlines():
line = i.strip().split('\t')
temp = []
for arr in range(featruenum - 1):
temp.append(float(line[arr]))
data.append(temp)
l.append(float(line[-1]))
return mat(data), l测试结果如下图:

在数据缺失30%的情况下错误率24%左右,比LR的30%满意很多,另外在弱分类器的个数增加到一个数量后错误率稳定,之后随着分类器的增加错误率反而上升,称之为过拟合现象。
具体测试程序请参见《机器学习实战》,这里不列出来。
全部代码:
#!usr/bin/python
#coding:utf-8
#adaboost.py
import numpy
from numpy import *
import operator
#读取简单数据
def loadData():
datamat = matrix([[1, 2.1],
[2, 1.1],
[1.3, 1],
[1, 1],
[2, 1]])
lavels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datamat, lavels
#弱分类器分类函数
#参数:数据集 特性所在列 特性阈值 分类值为1或-1
def lowType(Data, x, num, t):
res = ones((Data.shape[0], 1))
if t == 'less':
res[Data[ : ,x] <= num] = -1
else:
res[Data[ : ,x] > num] = -1
return res
#训练一个低级分类器,从多个弱分类器中选出误差值最小的
def trainClassify(datas, lavel, D):
Datamat = mat(datas)
Lavels = mat(lavel).T
m ,n = shape(Datamat)
best = {}
bestlavels = mat(ones((m, 1)))
step = 10.0
minerror = inf
for i in range(n):
minnum = Datamat[ : , i].min()
maxnum = Datamat[ : , i].max()
times = (maxnum - minnum) / step
for j in range(-1, int(step) + 1):
number = minnum + j * times
for k in ['less', 'large']:
r = lowType(Datamat, i, number, k)
error = mat(ones((m, 1)))
error[r == Lavels] = 0
weights = error.T * D
print "特性行:%d 特性分类值:%f 特性值选择方式:%s 误差值%f"% (i, number, k, weights)
if weights < minerror:
minerror = weights
bestlavels = r.copy()
best['row'] = i
best['number'] = number
best['types'] = k
return best, minerror, bestlavels
#adaboost训练器
def adaboostTrain(dataset, lavels, cycle = 40):
adaboost = []
m, n = shape(dataset)
D = mat(ones((m, 1)) / m)
lastlavels = zeros((m ,1))
for i in range(cycle):
temp, temperror, templavels = trainClassify(dataset, lavels, D)
print "D:", D.T
alpha = float(0.5 * log((1.0 - temperror) / max(temperror, 1e-16)))
temp['alpha'] = alpha
adaboost.append(temp)
print "第%d次预测的结果:"%(i + 1), templavels.T
e = multiply(-1 * alpha * mat(lavels).T, templavels)
D = multiply(D, exp(e))
D = D / D.sum()
lastlavels += alpha * templavels
print "高级分类器的结果:", lastlavels.T
lasterror = multiply(sign(lastlavels) != mat(lavels).T, ones((m, 1)))
errorRate = lasterror.sum() / m
print "错误率为%f"%(errorRate)
if errorRate == 0.0:
break
return adaboost
#分类预测,参数为测试数据和adaboost分类器
def adaboostClassify(testdata, adaboost):
testmat = mat(testdata)
m = shape(testmat)[0]
classifylavels = zeros((m, 1))
for i in range(len(adaboost)):
templavels = lowType(testmat, adaboost[i]['row'], adaboost[i]['number'], adaboost[i]['types'])
classifylavels += adaboost[i]['alpha'] * templavels
print classifylavels
return sign(classifylavels)
#数据加载函数
def loadDataSet(filename):
featruenum = len(open(filename).readline().split('\t'))
f = open(filename)
data = []
l = []
for i in f.readlines():
line = i.strip().split('\t')
temp = []
for arr in range(featruenum - 1):
temp.append(float(line[arr]))
data.append(temp)
l.append(float(line[-1]))
return mat(data), l以上是关于机器学习day12 机器学习实战adaboost集成方法与重新进行疝马病的预测的主要内容,如果未能解决你的问题,请参考以下文章