『TensorFlow』迁移学习_他山之石,可以攻玉_V2
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了『TensorFlow』迁移学习_他山之石,可以攻玉_V2相关的知识,希望对你有一定的参考价值。
絮絮叨叨
开学以来课业繁重(虽然也不怎么认真听讲...)一直没怎么闲着,一直没写什么长的代码,正巧好几件事赶在一块了:导师催着我把超新星检测的神经网络实现,我不想用现有的demo(当然一时间也没有合适的,之前写的AlexNet不太喜欢,毕竟是个老掉牙的网络架构,很多结构今天看来并不漂亮),而且分类之后需要考虑扩充为检测网络;和武师兄一起参加了个遥感影像识别的比赛,由于我对遥感是一窍不通而且也没什么兴趣学(逃),所以基本上要做的也是利用tensorflow搭建DL网络了,正好也需要一个图片处理的DL架构,不过这里需要我去额外学习一下语义分割了;这次的十一假期真的挺长,天文系的筒子们都回家了,新班级除了宿舍的熟人也不多,正是宅学校的好时机。于是就利用这个假期自己写了个迁移学习的类,蛮大的架构(原谅我见识少)完全自己来设计机会还真是不多,搭建的速度很慢,而且遇到了不少问题,当然过程是曲折的,结果算是圆满的,至此,分类部分是搭建完了,还是有蛮多体会的,对tensorflow以及编程思想什么的(玄学大师),记录一下,算是不愧对这个假期233
简介
1.这暂时是个基于vgg16(可更换模型)的迁移学习的分类网络,之后会考虑升级语义分割部分以适应之后的任务,不过应该是很久以后了(因为太难...)。
2.除了分类外,它可以做一部分图像预处理的活,暂时是批量图片尺寸调整(特意升级成了三线程加速,飞一般感觉),以后可能会升级为图像增强模块(因为现在的数据已经被师兄做了扩充,所以暂时用不到增强,也就没加)。
3.这是个人的一点执念了,前几天开始写的时候我对它的期望是(程序本体)简洁,(调用方式)简单,现在我发现基本不可能同时实现了...,我选择了前者,虽然是一个class,实际上各个方法之间基本是线性的,交叉调用很少,数据流基本也就只有一个方向,函数也写的简单易懂(当然和我菜也有关系),相对的,main的调用部分看起来又臭又长,不过套路模式很固定,我感觉还是不错的。
思路是这样的,对于一批图片,
- 我们首先批量裁剪,裁剪为网络需要的大小
- 然后送入预训练好的模型中,完成特征提取(实际就是个数据降维),写入新的二进制文件
- 自写一个分类头(实际就是个单层的神经网络),使用降维特征及标签进行训练
整个流程中我们使用字典来标记数据和标签,作为各个方法之间交流的格式。
代码
对于我的二分类问题,下面的程序会生成如下的目录架构,
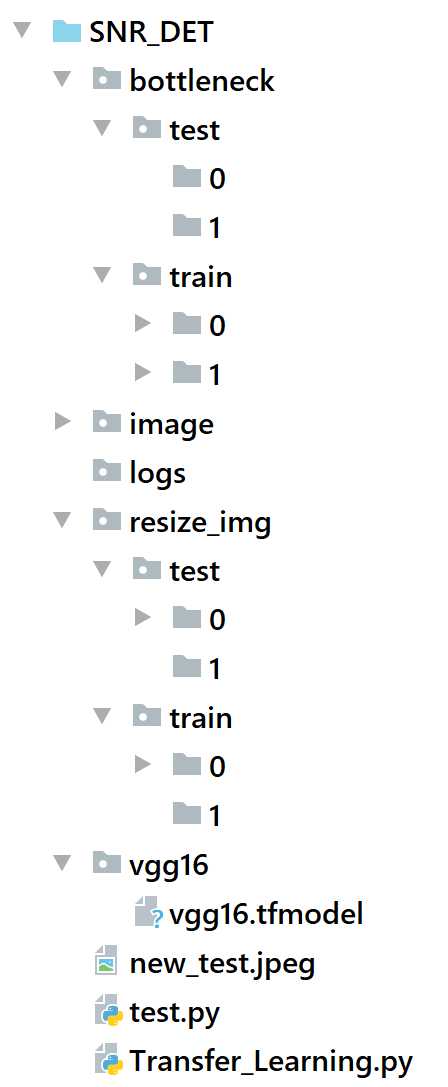
其中vgg16文件夹和image文件夹以及其中文件(预训练模型和训练数据)是需要自己事先准备的(废话),其他的都由程序自己生成。
程序如下,
import os
import glob
import pprint
import datetime
import threading
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
os.environ[‘TF_CPP_MIN_LOG_LEVEL‘] = ‘2‘
class image_process():
def __init__(self,
train_path = ‘./image/SNRDetect/train‘,
test_path=‘./image/SNRDetect/val‘):
# train0_path = ‘./image/SNRDetect/train/0‘,
# train1_path = ‘./image/SNRDetect/train/1‘,
# val0_path = ‘./image/SNRDetect/val/0‘,
# val1_path = ‘./image/SNRDetect/val/1‘):
‘‘‘
读入图片名称,每个类别图片名称以一维numpy数组形式存储
为了保证扩展性,本class下各方法尽量使用文件名array作为参数,而不去直接调用内置属性
目录给到分类一级(即path的下一级目录是类别名,里面是该类的文件)
‘‘‘
# self.dict = {}
# self.dict[‘train0_name‘] = [train0_path + ‘/‘ + name for name in np.squeeze([name[2] for name in os.walk(train0_path)])]
# self.dict[‘train1_name‘] = [train1_path + ‘/‘ + name for name in np.squeeze([name[2] for name in os.walk(train1_path)])]
# self.dict[‘val0_name‘] = [val0_path + ‘/‘ + name for name in np.squeeze([name[2] for name in os.walk(val0_path)])]
# self.dict[‘val1_name‘] = [val1_path + ‘/‘ + name for name in np.squeeze([name[2] for name in os.walk(val1_path)])]
# map(np.random.shuffle, [self.dict[‘train0_name‘], self.dict[‘train1_name‘], self.dict[‘val0_name‘], self.dict[‘val1_name‘]])
# np.random.shuffle(self.dict[‘train0_name‘])
# np.random.shuffle(self.dict[‘train1_name‘])
# np.random.shuffle(self.dict[‘val0_name‘])
# np.random.shuffle(self.dict[‘val1_name‘])
dir_train = [f[0] for f in [file for file in os.walk(train_path)][1:]]
file_train = [f[2] for f in [file for file in os.walk(train_path)][1:]]
self.train_dict = {}
for k,v in zip(dir_train,file_train):
np.random.shuffle(v)
self.train_dict[k.split(‘\\\\‘)[-1]] = v
dir_test = [f[0] for f in [file for file in os.walk(test_path)][1:]]
file_test = [f[2] for f in [file for file in os.walk(test_path)][1:]]
self.test_dict = {}
for k,v in zip(dir_test,file_test):
np.random.shuffle(v)
self.test_dict[k.split(‘\\\\‘)[-1]] = v
def reload_dict(self,
train_path = ‘./image/SNRDetect/train‘,
test_path=‘./image/SNRDetect/val‘):
dir_train = [f[0] for f in [file for file in os.walk(train_path)][1:]]
file_train = [f[2] for f in [file for file in os.walk(train_path)][1:]]
self.train_dict = {}
for k,v in zip(dir_train,file_train):
np.random.shuffle(v)
self.train_dict[k.split(‘\\\\‘)[-1]] = v
dir_test = [f[0] for f in [file for file in os.walk(test_path)][1:]]
file_test = [f[2] for f in [file for file in os.walk(test_path)][1:]]
self.test_dict = {}
for k,v in zip(dir_test,file_test):
np.random.shuffle(v)
self.test_dict[k.split(‘\\\\‘)[-1]] = v
# def re_load(self,
# train0_path = ‘./image/SNRDetect/train/0‘,
# train1_path = ‘./image/SNRDetect/train/1‘,
# val0_path = ‘./image/SNRDetect/val/0‘,
# val1_path = ‘./image/SNRDetect/val/1‘):
# self.dict[‘train0_name‘] = [train0_path + ‘/‘ + name for name in
# np.squeeze([name[2] for name in os.walk(train0_path)])]
# self.dict[‘train1_name‘] = [train1_path + ‘/‘ + name for name in
# np.squeeze([name[2] for name in os.walk(train1_path)])]
# self.dict[‘val0_name‘] = [val0_path + ‘/‘ + name for name in
# np.squeeze([name[2] for name in os.walk(val0_path)])]
# self.dict[‘val1_name‘] = [val1_path + ‘/‘ + name for name in
# np.squeeze([name[2] for name in os.walk(val1_path)])]
# map(np.random.shuffle,
# [self.dict[‘train0_name‘],self.dict[‘train1_name‘],self.dict[‘val0_name‘],self.dict[‘val1_name‘]])
def resize_img(self,
name_list,
img_path=‘./image/SNRDetect/train/0‘,
file_name=‘test/0‘,
size=(224,224)):
self._name_list = name_list
def resize_img_thread():
print(‘图片尺寸调整子线程(代号{})启动‘.format(threading.current_thread().name))
if not os.path.exists(‘resize_img‘):
os.mkdir(‘./resize_img‘)
if not os.path.exists(‘resize_img/train‘):
os.mkdir(‘./resize_img/train‘)
if not os.path.exists(‘resize_img/test‘):
os.mkdir(‘./resize_img/test‘)
# if not os.path.exists(‘./resize_img/{}‘.format(file_name.split(‘/‘)[-1])):
if not os.path.exists(‘./resize_img/{}‘.format(file_name)):
os.mkdir(‘./resize_img/{}‘.format(file_name))
with tf.Session() as sess:
for img in self._name_list:
self._name_list.remove(img)
print(‘\\r‘+img)
print(os.path.join(img_path,img))
img_raw = tf.gfile.FastGFile(os.path.join(img_path,img), ‘rb‘).read()
img_0 = tf.image.decode_jpeg(img_raw)
img_1 = tf.image.resize_images(img_0, size, method=3)
re_img = np.asarray(sess.run(img_1),dtype=‘uint8‘)
# print(img.split(‘/‘)[-1].split(‘.‘))
with tf.gfile.FastGFile(‘./resize_img/{2}/{0}_{1}.jpeg‘.format(
img.split(‘/‘)[-1].split(‘.‘)[0],
size[0],
file_name) ,‘wb‘) as f:
f.write(sess.run(tf.image.encode_jpeg(re_img)))
f.flush()
# 多线程调整图片尺寸
threads = []
t1 = threading.Thread(target=resize_img_thread, name=‘resize_img_thread:0‘)
threads.append(t1)
t2 = threading.Thread(target=resize_img_thread, name=‘resize_img_thread:1‘)
threads.append(t2)
t3 = threading.Thread(target=resize_img_thread, name=‘resize_img_thread:2‘)
threads.append(t3)
for t in threads:
t.start()
for t in threads:
t.join()
def bottlenecks_tensor_write(self,
name_list,
img_path=‘./image/SNRDetect/train/0‘,
file_name = ‘train/0‘,
model_name = ‘vgg16/vgg16.tfmodel‘):
‘‘‘
张量瓶颈层文件写入方法,路径为:bottleneck/类名/文件名
:param name_list: 图片名称列表
:param img_path: 图片路径(对应上面的列表)
:param file_name: 保存张量的文件名称
:param model_dir: 模型文件夹
:param model_name: 模型文件名
:return:
‘‘‘
self._name_list = name_list
if not os.path.exists(‘bottleneck‘):
os.mkdir(‘./bottleneck‘)
if not os.path.exists(‘bottleneck/train‘):
os.mkdir(‘./bottleneck/train‘)
if not os.path.exists(‘bottleneck/test‘):
os.mkdir(‘./bottleneck/test‘)
if not os.path.exists(‘./bottleneck/{}‘.format(file_name)):
os.mkdir(‘./bottleneck/{}‘.format(file_name))
def bottlenecks_tensor_get_thread():
print(‘瓶颈层张量获取子线程(代号{})启动‘.format(threading.current_thread().name))
Pp = pprint.PrettyPrinter()
g = tf.Graph()
with g.as_default():
with open(os.path.join(model_name),‘rb‘) as f: # 阅读器上下文
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# 获取输入层tensor和瓶颈层tensor
image_input_tensor, bottleneck_tensor = tf.import_graph_def(graph_def,
return_elements=[‘images:0‘,
‘MatMul:0‘])
#‘conv5_3/conv5_3:0‘])
# Pp.pprint(g.get_operations())
with tf.Session() as sess:
Pp.pprint(self._name_list)
for img in self._name_list:
self._name_list.remove(img)
print(‘\\r‘ + os.path.join(img_path,img))
image_data = open(os.path.join(img_path,img),‘rb‘).read()
# 防止array被压缩
np.set_printoptions(threshold=np.nan)
# 张量对象是不能作为feed对象的,而且维度必须是4维
bottleneck_values = sess.run(bottleneck_tensor,
feed_dict={image_input_tensor:sess.run(tf.expand_dims(
tf.image.decode_jpeg(image_data),axis=0))})
# bottleneck_string = ‘,‘.join(str(x) for x in bottleneck_values)
# with open(‘./bottleneck/{1}/{0}.txt‘.format(
# img.split(‘/‘)[-1].split(‘.‘)[0], file_name) ,‘w‘) as f:
# f.write(bottleneck_string)
# f.flush()
print(‘./bottleneck/{1}/{0}‘.format(img.split(‘/‘)[-1].split(‘.‘)[0], file_name))
np.save(‘./bottleneck/{1}/{0}‘.format(img.split(‘/‘)[-1].split(‘.‘)[0], file_name),bottleneck_values)
# 多线程书写张量文件
threads = []
t1 = threading.Thread(target=bottlenecks_tensor_get_thread, name=‘bottlenecks_tensor_get_thread:0‘)
threads.append(t1)
t2 = threading.Thread(target=bottlenecks_tensor_get_thread, name=‘bottlenecks_tensor_get_thread:1‘)
threads.append(t2)
t3 = threading.Thread(target=bottlenecks_tensor_get_thread, name=‘bottlenecks_tensor_get_thread:2‘)
threads.append(t3)
for t in threads:
t.start()
for t in threads:
t.join()
def bottlenecks_dict_get(self, path = ‘C:\\Projects\\python3_5\\SNR_DET\\\\bottleneck‘):
‘‘‘
生成bottlenecks文件字典{类名:[文件名]}
:param path:
:return:
‘‘‘
dir = [f[0] for f in [file for file in os.walk(path)][1:]]
file = [f[2] for f in [file for file in os.walk(path)][1:]]
self.bottlenecks_dict = {}
for k,v in zip(dir, file):
np.random.shuffle(v)
if v != []:
self.bottlenecks_dict[k.split(‘\\\\‘)[-1]] = v
def bottlenecks_tensor_get(self,
dict,
batch_size,
train=True,
base_path=‘./‘):
‘‘‘
随机获取batch_size的瓶颈层张量
:param dict:
:param batch_size:
:param base_path:
:return: 两个list,张量list和标签list[array(one_hot编码)]
‘‘‘
bottlenecks = []
ground_truths = []
n_class = len(dict)
for i in range(batch_size):
label_index = np.random.randint(n_class)
label_name = list(dict.keys())[label_index]
bottlenecks_tensor_name = np.random.choice(dict[label_name])
if train == True:
train_or_test = ‘train‘
else:
train_or_test = ‘test‘
bottleneck_string = np.load(os.path.join(base_path,
‘bottleneck‘,
train_or_test,
label_name,
bottlenecks_tensor_name))
bottlenecks.append(bottleneck_string)
ground_truth = np.zeros(n_class,dtype=np.float32)
ground_truth[label_index] = 1.0
ground_truths.append(ground_truth)
return bottlenecks, ground_truths
def class_head(self, n_class=2,batch_size=100,steps=20000):
‘‘‘
分类头
:param n_class:
:return:
‘‘‘
# 添加占位符
X = tf.placeholder(tf.float32,[None,None],name=‘BottleneckInputPlaceholder‘)
y = tf.placeholder(tf.float32,[None,n_class],name=‘label‘)
# 全连接层
with tf.name_scope(‘final_train_ops‘):
Weights = tf.Variable(tf.truncated_normal([4096,n_class],stddev=0.001))
biases = tf.Variable(tf.zeros([n_class]))
logits = tf.matmul(X,Weights) + biases
final_tensor = tf.nn.softmax(logits)
# 交叉熵损失函数
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=y))
# 优化器
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(cross_entropy)
# 准确率计算
with tf.name_scope(‘evaluation‘):
correct_prediction = tf.equal(tf.argmax(final_tensor,1),tf.argmax(y,1))
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
self.bottlenecks_dict_get()
for i in range(steps):
batch_X, batch_y = self.bottlenecks_tensor_get(self.bottlenecks_dict,
batch_size,
base_path=‘./‘)
sess.run(train_step,feed_dict={X:np.squeeze(np.asarray(batch_X)), y:batch_y})
if i % 500 == 0:
print(‘当前为第{0}轮,\\r误差值为:‘.format(i),
sess.run(cross_entropy,feed_dict={X:np.squeeze(np.asarray(batch_X)), y:batch_y}))
print(‘准确率为:{:.2f}%‘.format(
sess.run(evaluation_step,feed_dict={X:np.squeeze(np.asarray(batch_X))*100, y:batch_y})))
def graph_view(self,
log_dir = ‘logs‘,
model_name = ‘vgg16/vgg16.tfmodel‘):
‘‘‘可视化图,并输出节点‘‘‘
Pp = pprint.PrettyPrinter()
g = tf.Graph()
with g.as_default():
with open(model_name,‘rb‘) as f: # 阅读器上下文
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def)
Pp.pprint(g.get_operations())
with tf.Session() as sess:
summary_writer = tf.summary.FileWriter(log_dir,sess.graph)
if __name__==‘__main__‘:
SNR = image_process()
start_time = datetime.datetime.now()
‘‘‘
图片裁剪
图片裁剪时建议注释掉本部分之后的程序,在裁剪完成后注释掉本部分单独运行后面的瓶颈张量部分
另注,本方法保存目录一级名称必须是train或者test中的一个,二级目录自取,建议使用类名
‘‘‘
SNR.resize_img(SNR.train_dict[‘0‘],img_path=‘./image/SNRDetect/train/0‘,file_name=‘train/0‘,
size=(224,224))
SNR.resize_img(SNR.train_dict[‘1‘],img_path=‘./image/SNRDetect/train/1‘,file_name=‘train/1‘,
size=(224,224))
SNR.resize_img(SNR.test_dict[‘0‘],img_path=‘./image/SNRDetect/val/0‘,file_name=‘test/0‘,
size=(224,224))
SNR.resize_img(SNR.test_dict[‘1‘],img_path=‘./image/SNRDetect/test/1‘,file_name=‘test/1‘,
size=(224,224))
‘‘‘
瓶颈层张量获取
‘‘‘
# 重载裁剪后的图片
# SNR.reload_dict(train_path=‘C:/Projects/python3_5/SNR_DET/resize_img/train‘,
# test_path=‘C:/Projects/python3_5/SNR_DET/resize_img/test‘)
# 瓶颈层张量文件写入
# SNR.bottlenecks_tensor_write(
# SNR.train_dict[‘0‘],
# img_path=‘./resize_img/train/0‘,
# file_name=‘train/0‘,
# model_name=‘vgg16/vgg16.tfmodel‘)
# SNR.bottlenecks_tensor_write(
# SNR.train_dict[‘1‘],
# img_path=‘./resize_img/train/1‘,
# file_name=‘train/1‘,
# model_name=‘vgg16/vgg16.tfmodel‘)
# SNR.bottlenecks_tensor_write(
# SNR.test_dict[‘0‘],
# img_path=‘./resize_img/test/0‘,
# file_name=‘test/0‘,
# model_name=‘vgg16/vgg16.tfmodel‘)
# SNR.bottlenecks_tensor_write(
# SNR.test_dict[‘1‘],
# img_path=‘./resize_img/test/1‘,
# file_name=‘test/1‘,
# model_name=‘vgg16/vgg16.tfmodel‘)
# 瓶颈层张量文件字典获取
# SNR.bottlenecks_dict_get()
# 利用瓶颈层张量文件和字典训练分类器
# SNR.class_head(n_class=2)
end_time = datetime.datetime.now()
time = end_time - start_time
print(‘\\n总计耗时{}‘.format(time))
注意一下,main部分中大块的注释不是废弃代码,是因为我pycharm的设置,导致不能一次运行全部,实际我的操作是先运行图片裁剪(后面的注释掉,如上面所示),然后注释掉裁剪部分,取消注释下面的部分,重新运行,训练分类器。
简单介绍一下几个之前用的不太熟的函数
os.walk()
[i for i in os.walk(‘C:\\Projects\\python3_5\\Gephi‘)] Out[6]: [(‘C:\\\\Projects\\\\python3_5\\\\Gephi‘, [‘.ipynb_checkpoints‘], [‘17级学硕导师情况.csv‘, ‘17级学硕导师情况.xlsx‘, ‘bear.py‘, ‘bear.txt‘, ‘csv_init.py‘, ‘EuroSiS Generale Pays.gexf‘, ‘kmeans.py‘, ‘lesmiserables.gml‘, ‘network_x.py‘, ‘pd_nx_test.py‘, ‘result.csv‘, ‘result.txt‘, ‘Untitled.ipynb‘, ‘西游记.csv‘]), (‘C:\\\\Projects\\\\python3_5\\\\Gephi\\\\.ipynb_checkpoints‘, [], [‘Untitled-checkpoint.ipynb‘])]
首先,它返回一个迭代器,其次,每一层(tuple)有三个元素(list),如下:
[
([本层目录名],
[本目录下的目录],
[本目录下的文件]),
... ...
]
os.mkdir()
这个函数一次只能建立一级目录,所以想要建立多级目录需要连用,
os.mkdir(‘./file1‘)
os.mkdir(‘./file1/file2‘)
另外经常和os.path.exists()连用。
更新v1
好吧,我得承认,我愚蠢了,实际上os.makedirs()是可以同时创建多级目录的,
os.makedirs(‘./1/2‘)
以上是关于『TensorFlow』迁移学习_他山之石,可以攻玉_V2的主要内容,如果未能解决你的问题,请参考以下文章