JXLS 2.4.0系列教程——多sheet是怎么做到的
Posted 李狐同学的异世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JXLS 2.4.0系列教程——多sheet是怎么做到的相关的知识,希望对你有一定的参考价值。
注:本文代码在第一篇文章基础上修改而成,请务必先阅读第一篇文章。
http://www.cnblogs.com/foxlee1024/p/7616987.html
本文也不会过多的讲解模板中遍历表达式的写法和说明,请先阅读第二篇文章。
http://www.cnblogs.com/foxlee1024/p/7617120.html
好吧,今天是国庆第二天,大清早起来先把文章给写了吧!
这篇内容主要讲解一些如何导出多sheet的报表,我将用一个学生成绩表作为讲解案例。多sheet的导出不单单是简单分sheet而已,还加入了分页的功能。效果先看下图:
Sheet1

Sheet2
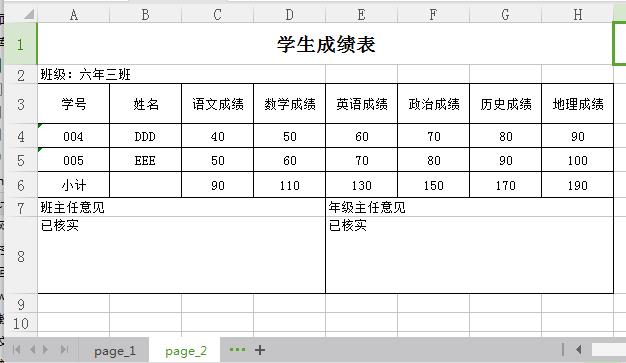
大家可以看到,两个不同sheet中,表结构是一样,但是里面的学生数据有了个分页的效果。这是怎么做到的呢?
这里,我们得从模板制作讲起,知道了多sheet模板的原理后,写代码就轻松多了。

大家看红框里的注释:
jx:area(lastCell="I8")
jx:each(items="pages", var="page", lastCell="I8" multisheet="sheetNames")
第一行不用说,是划定模板区域。第二行看起来是一个很正常的遍历注释,但是里面多了一个multisheet="sheetNames"参数,这个参数就是分sheet的参数。我们连起来看就是,以整个Excel报表为一个遍历输出的对象,每一个sheet就是一条输出的记录。简单的说,就是遍历一个集合(List)items,将集合内每一个对象输出到每一个独立的sheet中。
只要写上“multisheet”属性JXLS就会自动的分sheet了。那么还有一个问题,就是multisheet属性的值sheetNames是什么意思?这个值是从model中传来的一个集合(一般用List),里面存放着每一页sheet应该起的名字,JXLS在读取pages进行分sheet遍历的时候,也会读取sheetNames进行遍历给每一个sheet改名。
接下来我们看看A4单元格的注释,大家看过第三篇文章应该知道怎么嵌套循环了,这里本质上也是一个嵌套,所以A4里的遍历标签的items写的值就是A1(红框)遍历标签里的page,然后点上对应的属性。
标签讲完了,具体怎么做呢?我们打算用一个叫做Page的类作为分页的javaBean对象,这个对象里存放着这一页应该显示的学生记录(List<Student>)和每一页的页名(sheet名)。然后将这个page对象放进一个链表中,传给model。
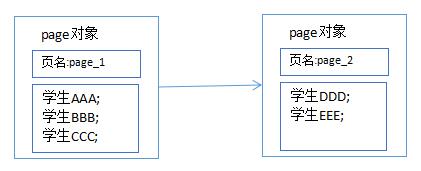
上图就是文章开头两张图片中学生成绩分页的链表示意图。
接下来我们开始写代码,假设数据库查询出来的结果就是一个装有学生对象的一长串链表。那么我们从最基本的学生类(student)开始写起,
public class Student {
String id;
String name;
Integer chinese;
Integer math;
Integer english;
Integer politics;
Integer history;
Integer geography;
public Student(String id, String name, Integer chinese, Integer math, Integer english, Integer politics, Integer history, Integer geography) {
super();
this.id = id;
this.name = name;
this.chinese = chinese;
this.math = math;
this.english = english;
this.politics = politics;
this.history = history;
this.geography = geography;
}
public Student() {
}
/** 以下省略了get/set方法,请自行补全 */
}
学生类没什么好说的,学生的基本信息。接下来我们写页面类(Page),也就是每一个sheet应该包含什么信息。
/**
* 该类用来封装每一页的数据
*/
public class Page {
/**
* 页面信息
*/
private String sheetName; // 每个sheet名字
private String currentPage; // 当前页
private String tolalPage; // 总页
/**
* 页面遍历的数据 List 的泛型自行设置,如果所有数据都来着同一个类就写那个类,
* 不是同一个类有继承就写继承类的泛型,没有就写问号。
*/
private List<?> data;
public Page(String sheetName, String currentPage, String tolalPage, List<?> data) {
super();
this.sheetName = sheetName;
this.currentPage = currentPage;
this.tolalPage = tolalPage;
this.data = data;
}
public Page() {
}
/** 以下省略了get/set方法,请自行补全 */
}
这个类说两句,属性data的类型的List,泛型如果你能确定传进来的对象就写上该对象,或者泛型继承,不能就写上问号。还有两个属性:currentPage和tolalPage这算是保留属性,本篇教程中没有用到,但是我还是写上了,建议同学们也可以写上,因为当前页或总页码可以往后使用工具标签时候可以判断是否最后一页。
接下来是重点了,我们已经有了从数据库中查询的一长串装有学生对象的链表,有了每一页应该装什么数据的页面对象,接下来我们要做的就是分页了。
把一长串装有学生对象的链表截成一段段的数据,然后装进page对象中,然后再把一节一节装有数据的page对象装进一个新链表中。返回给JXSL的model。
我们看下分页代码:
/**
* 此类用于分页,就是把从数据库查询出来的一个完整的List链表变成一截一截是数据。
* @author foxlee1024
*/
public class DataByPage {
static int pagesize = 3; // 每页记录数
/**
* 根据每页显示多少条数据计算总页数
* @param dataList 数据库查询的数据
*/
public static int countPages(List<?> dataList) {
int recordcount = dataList.size(); // 总记录数
return (recordcount + pagesize - 1) / pagesize;
}
public static List<Page> byPage(List<?> dataList) {
int pagecount; // 总页数
int nowDataListPoint = 0; // 读取到接收的哪一条数据
pagecount = countPages(dataList); // 计算页码
List<Page> pageList = new ArrayList<Page>(); // 页面分页
for (int i = 0; i < pagecount; i++) {
List<Object> pagedata = new ArrayList<Object>();
// 把传来的数据取出
while (nowDataListPoint < dataList.size()) {
pagedata.add(dataList.get(nowDataListPoint));
nowDataListPoint += 1;
if (nowDataListPoint != 0 && nowDataListPoint % pagesize == 0) {
break;
}
}
Page page = new Page("page_" + (i + 1), (i + 1) + "", pagecount + "", pagedata);
pageList.add(page);
}
return pageList;
}
}
原理就是遍历传进来的一长串链表,然后根据判断将他截成一段后装进链表中,然后把链表封装进page类的data属性里,接着再把page类装进链表中,然后返回装有page对象的链表。
好了,全都齐全了,我们可以开始写main方法了。
public class TestMain {
public static void main(String[] args) throws Exception {
// 模板位置,输出流
String templatePath = "E:/template5.xls";
OutputStream os = new FileOutputStream("E:/out5.xls");
List<Student> list = generateData(); // 模拟数据库获取数据
List<Page> page = DataByPage.byPage(list); // 把获取的数据进行分页转换
Map<String, Object> model = new HashMap<String, Object>();
model.put("pages", page);
model.put("sheetNames", getSheetName(page));
model.put("className", "六年三班");
model.put("teacherComment", "已核实");
model.put("directorComment", "已核实");
JxlsUtils.exportExcel(templatePath, os, model);
os.close();
System.out.println("完成");
}
/**
* Excel 的分页名(页码)的封装
* 此方法用来获取分好页的页名信息,将信息放入一个链表中返回
*/
public static ArrayList<String> getSheetName(List<Page> page) {
ArrayList<String> al = new ArrayList<String>();
for (int i = 0; i < page.size(); i++) {
al.add(page.get(i).getSheetName());
}
return al;
}
/**
* 模拟生成数据
*/
public static List<Student> generateData(){
List<Student> list = new ArrayList<Student>();
Student stu1 = new Student("001", "AAA", 10, 20, 30, 40, 50, 60);
Student stu2 = new Student("002", "BBB", 20, 30, 40, 50, 60, 70);
Student stu3 = new Student("003", "CCC", 30, 40, 50, 60, 70, 80);
Student stu4 = new Student("004", "DDD", 40, 50, 60, 70, 80, 90);
Student stu5 = new Student("005", "EEE", 50, 60, 70, 80, 90, 100);
list.add(stu1);
list.add(stu2);
list.add(stu3);
list.add(stu4);
list.add(stu5);
return list;
}
}
其他没要讲的,唯一有一个就是需要一个getSheetName() 方法,遍历获取每一个page的sheeName,然后装进链表中。然后put入model的sheetNames键里。
模板就按照前边开头我们讲解的那个模板写,接下来我们运行一下代码。
当你看到控制台打出“完成”,欣喜的打开excel文件时候,你会发现第一页sheet是空白的......从第二页开始才是真正的内容。然后你看到第一页的sheet名是你模板的sheet名,你就知道肯定是JXLS在复制模板时候没有删除模板页面造成的。

这个问题我没办法解决,我尝试过在JxlsUtils中设置JxlsHelper的属性:jxlsHelper.setDeleteTemplateSheet(true); 然而并没什么卵用,不知道是我设置的地方不对,还是别的原因。请知道解决方案的同学务必留言告知一下,万分感谢!
虽然没办法从根本上解决,但是可以找到凑活解决的办法,就是利用POI把多余的sheet给删掉,写一个工具类,代码如下:
public class DelSheet {
/**
* 删除指定的Sheet
* @param targetFile 目标文件
* @param sheetName Sheet名称
*/
public static void deleteSheet(String targetFile,String sheetName) {
try {
FileInputStream fis = new FileInputStream(targetFile);
HSSFWorkbook wb = new HSSFWorkbook(fis);
fileWrite(targetFile, wb);
//删除Sheet
wb.removeSheetAt(wb.getSheetIndex(sheetName));
fileWrite(targetFile, wb);
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 写隐藏/删除后的Excel文件
* @param targetFile 目标文件
* @param wb Excel对象
* @throws Exception
*/
public static void fileWrite(String targetFile,HSSFWorkbook wb) throws Exception{
FileOutputStream fileOut = new FileOutputStream(targetFile);
wb.write(fileOut);
fileOut.flush();
fileOut.close();
}
}
接下来我们就在main方法中,执行完excel导出的代码后调用下删除sheet的语句:
JxlsUtils.exportExcel(templatePath, os, model);
os.close();
// 删除多出来的sheet
DelSheet.deleteSheet("E:/out5.xls", "template");
System.out.println("完成");
传入的是excel导出的路径和要删除的sheet名字,其实可以传入sheet的编号的,但是我觉得传入名字可以防止误删除。要传入编号的同学请自行修改deleteSheet方法,wb.getSheetIndex(sheetName)既可以接收String也可以接收Integer,如果我没有记错的话。
我们再运行一遍代码看看,我们就可以看到开头的那样的效果了!
一般来说,这篇文章到这里应该就结束了。但是还有一个问题,就是如果我想做每一个学生的成绩分页呢?怎么做?就是一个学生独占一个sheet。
我不卖关子了,我们记得,每一个sheet的信息其实是对应一个page对象的,这个对象里有一个List<Student> data,所以在一个sheet里才能够将这个data取出,交给模板进行遍历。如果我们要一个学生独占一个sheet,我们只需要在Page类中加入一个对象类型的属性就可以了,在模板中直接取这个对象具体的属性。这也是我为什么要用page对象的原因,扩展性高。
public class Page {
/**
* 页面信息
*/
private String sheetName; // 每个sheet名字
private String currentPage; // 当前页
private String tolalPage; // 总页
/**
* 页面遍历的数据 List 的泛型自行设置,如果所有数据都来着同一个类就写那个类,
* 不是同一个类有继承就写继承类的泛型,没有就写问号。
*/
private List<?> data;
/**
* 一页只保存一个人的信息
*/
private Object onlyOne;
/** 省略构造器和其他get/set方法 */
public Object getOnlyOne() {
return onlyOne;
}
public void setOnlyOne(Object onlyOne) {
this.onlyOne = onlyOne;
}
接下来我们修改一下main方法,把原本用来分页的List<Page> page = DataByPage.byPage(list) 注释掉。然后新加一句List<Page> page = individual(list) :
public static void main(String[] args) throws Exception {
// 模板位置,输出流
String templatePath = "E:/template5.xls";
OutputStream os = new FileOutputStream("E:/out5.xls");
List<Student> list = generateData(); // 模拟数据库获取数据
//List<Page> page = DataByPage.byPage(list); // 把获取的数据进行分页转换
List<Page> page = individual(list); // 一页一个人
Map<String, Object> model = new HashMap<String, Object>();
model.put("pages", page);
model.put("sheetNames", getSheetName(page));
model.put("className", "六年三班");
model.put("teacherComment", "已核实");
model.put("directorComment", "已核实");
JxlsUtils.exportExcel(templatePath, os, model);
os.close();
// 删除多出来的sheet
DelSheet.deleteSheet("E:/out5.xls", "template");
System.out.println("完成");
}
Individual() 方法的代码如下:
/**
* 将数据获取的数据封装成一页一个人的List
*/
public static List<Page> individual(List<Student> list){
List<Page> pages = new ArrayList<Page>();
for(int i = 0; i < list.size(); i++){
Page p = new Page();
p.setOnlyOne(list.get(i));
p.setSheetName(list.get(i).getName());
pages.add(p);
}
return pages;
}
接收传进来的List<Student> list链表数据,然后遍历该链表,将其封装Page对象中,并且别忘了设置sheetName。
模板是这样的:

模板中不需要两层循环了,直接在页面中取page的onlyOne属性(装的是Student对象)的值就好了。例如:${page.onlyOne.id}、${page.onlyOne.chinese}。
行了,执行代码看一下效果:
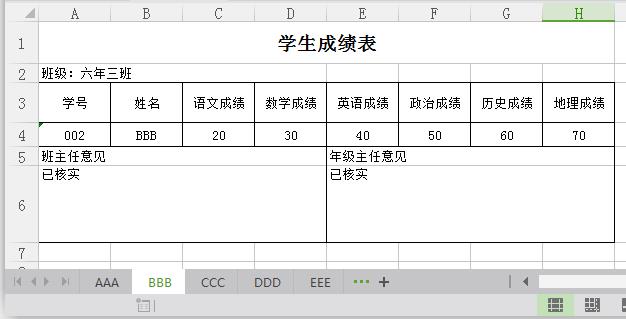
到这里就真的是结束了,这篇文章内容有点多,主要讲了分sheet导出的方法,本质上只是一种的,我先讲了比较复杂的,带有分页效果的分sheet。然后再讲了单纯的分sheet。介于代码比较多,我就把源码发上了让大家一起研究。源码里的jar包我给删掉了,要使用就在第一篇文章先下载jar包吧!
顺便说一句,前几篇教程的源码是不存在的,因为我每一篇都是在原来代码基础上改的,其实所有代码我都发上来了。这篇我是专门开新工程弄的例子。哦,还有一句,家里eclipse太久不用了,编码居然是GBK而不是通用的UTF-8(写完了才发现),大家看着改吧。
jar包下载地址(内有官方2.4.0版本,2.4依赖的jar包,klguang 的demo):这里下载
本文源码下载(内有模板,无jar包,请配合上边jar包使用): 源码下载
以上是关于JXLS 2.4.0系列教程——多sheet是怎么做到的的主要内容,如果未能解决你的问题,请参考以下文章