洗礼灵魂,修炼python--从一个简单的print代码揭露编码问题,运行原理和语法习惯
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了洗礼灵魂,修炼python--从一个简单的print代码揭露编码问题,运行原理和语法习惯相关的知识,希望对你有一定的参考价值。
前期工作已经准备好后,可以打开IDE编辑器了,你可以选择python自带的IDLE,也可以选择第三方的,这里我使用pycharm——一个专门为python而生的编译器
第一个python代码当然是所有开发语言里入门必学“hello,world”,no,你错了,我偏不
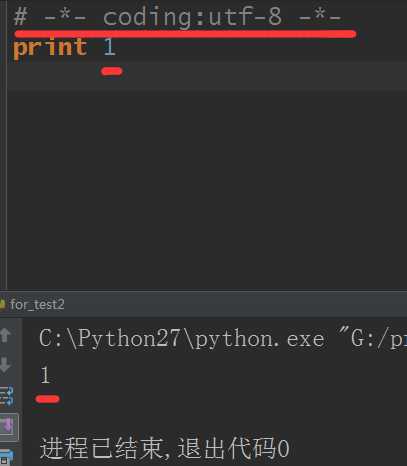
第一行是编码,utf-8这是国际使用标准,如果我不加的话,很容易出错
第二行print(打印的意思)语句,是python的关键词语句,可以打印一个字符,可以打印一个数字,可以打印任何你想打印的东西,只要你想让它显示出来,你就可以使用print打印
下面的C:\\python。。。就是python安装的位置,可以侧边的看出我当前使用的是python2版本来运行这个代码的
1——即为当前我的代码运行的结果,把1打印到屏幕上了。
由此出现了几个问题:
1.编码,什么是编码?为什么要使用编码?
答:这是个国际标准,简单的理解就是计算机中存储数据的格式,在计算机中数据都是以0/1来进行保存,所以为了把0/1转换为人类可以理解的内容就需要编码来进行转换。而人类写的字符要让计算机识别,也需要转换编码。开发语言写出来的代码,如果是高级语言(代码贴近人类语言的则为高级语言,0和1则为机器语言),都需要解释器解释为机器可以认识的字符。
最开始的字符编码是ASCII
ASCII:美国人用的,只能解释数字和英文字母。ascii是ANSI标准,包含128个字符(7 bits)我们说的ansi编码,通常特指windows平台的一种ascii扩展码(因为windows默认的编码就是ANSI),它将ascii码扩展到8bits,增加了0x80-0xff共128个字符。在cjk(chinese japanese korean)系统中,ansi还常常指代包括多字节内码的编码。不难看出,所谓ansi编码,就是一种未经国际标准化(也没办法标准化,因为扩展部分的内码存在交集)的兼容ascii编码的,非unicode字符集编码。
EASCII:因为欧洲德语等语言会用到派生拉丁字符。
但这些对世界上其他语言汉语、日语、韩语是不够用的,需要多个字节。
GBK系列:为了解决中文编码问题,编写了GBK编码集,其兼容ASCII,需要注意的是不同的编码集会存在兼容问题,GBK一个汉字使用两个字节表示。
虽然GBK解决了中文编码问题,但是如果中国用自己开发的编码集,日本、韩国也用自己的,这样在信息交互时如果对方的计算机没有对应的编码集解码出的数据就是错误的,能不能开发一套世界通用的编码集呢,Unicode应运而生,所以Unicode就是大一统,Unicode编码不用查码表
Unicode:该编码集采用4个字节表示一个字符;可以容纳世界上所有的字符;但问题也很明显,假设要传一篇英文文档,使用ASCII编码与使用Unicode的传输量相差4倍,换句话说Unicode传输效率太低;为了解决这个问题,出现了UTF-8,它是Unicode的一种实现方式。
| Unicode范围 | UTF-8编码 |
|---|---|
| 单字节:0000 0000 - 0000 007F | 0xxxxxxx |
| 双字节:0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 三字节:0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 四字节:0001 0000 - 001F FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Unicode编码规范下有UTF-8,UTF-16,UTF-32三种具体实现。
UTF-32每个字符都使用4字节表示。
UTF-8,采用变长技术,占用1到4字节,兼容ASCII编码,汉字占用3个字节。
UTF-16统一采用两个字节表示一个字符。
UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作,因为英文字母在ascii中是一个字节,在utf-8中也是一个字节,而ascii不支持中文。
例:中国的中字:
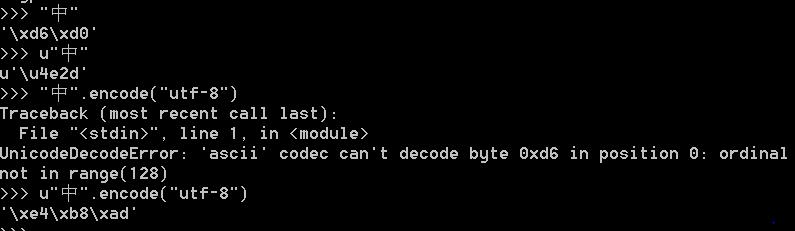
从上到下分别为GBK,unicode和utf编码,其中需要注意的是无法从GBK直接转化为utf-8,可以吧Unicode字符串encode("utf-8")到UTF8,可以把Utf-8字符串decode("utf-8")到Unicode字符串
encode主要是把unicode encode到utf-8,decode主要是从utf-8到unicode,windows内核都是unicode
python在print时,会自动把字符串encode为sys.stdout.encoding,当python把一个已经encode的字符串再进行encode会报错。
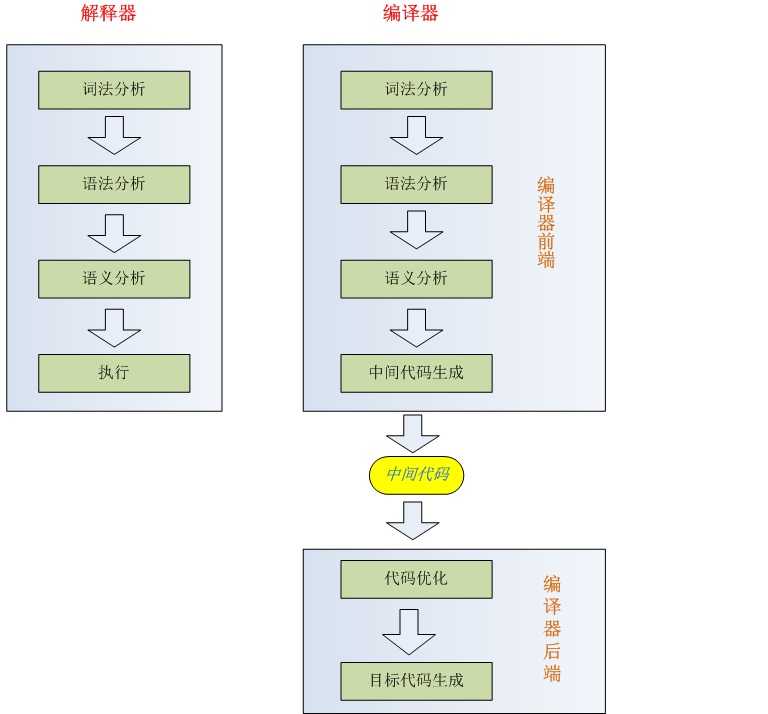
既然说到编码,那顺便把编译器和解释器,也一起说了,高级语言因为十分贴近人类用语,所以机器是无法识别的,这就需要解释器来解释
字节码和机器码:
字节码和机器码(或者native code)的区别:
C代码被编译成机器码,将在处理器上直接执行。每一条指令控制CPU工作,而python就是用C写的。
Java代码被编译成字节码,将在Java虚拟机(JVM)这个抽象的计算机上执行。每一条指令由JVM处理,JVM同计算机本身之间交互,再由解释器解释或者翻译成可执行文件
简而言之:机器码快的多,但字节码更易迁移,也更安全。
解释性语言定义:
程序不需要编译,在运行程序的时候才翻译,每个语句都是执行的时候才翻译。这样解释性语言每执行一次就需要逐行翻译一次,效率比较低。
现代解释性语言通常把源程序编译成中间代码,然后用解释器把中间代码一条条翻译成目标机器代码,一条条执行。
编译性语言定义:
编译性语言写的程序在被执行之前,需要一个专门的编译过程,把程序编译成为机器语言的文件,比如exe文件,以后要运行的话就不用重新翻译了,直接使用编译的结果就行了(exe文件),因为翻译只做了一次,运行时不需要翻译,所以编译型语言的程序执行效率高。
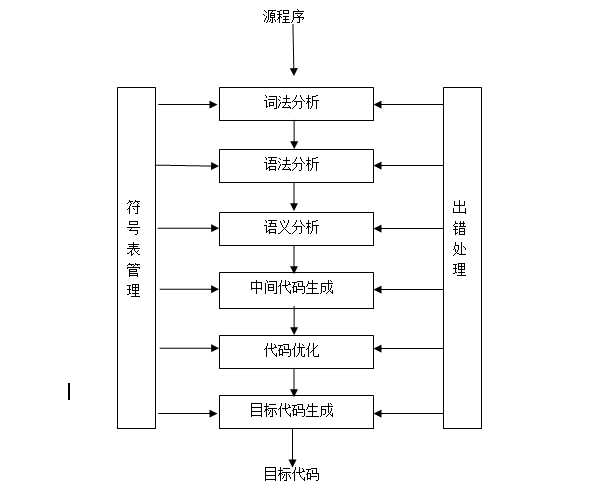
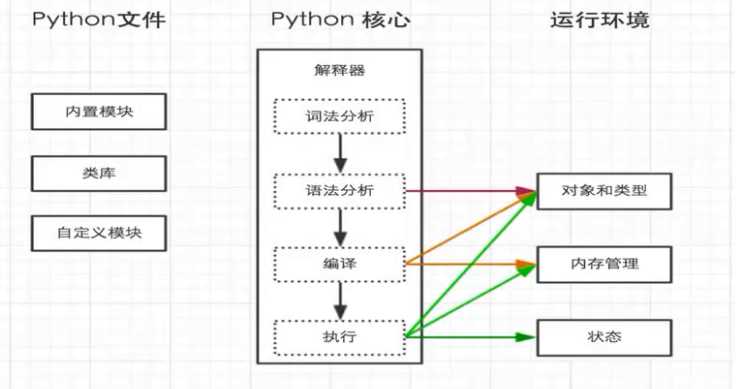
Python工作过程:
python 是解释型的编程语言。也可以把python脚本编译成pyc文件,不然编译后也是一种python虚拟指令,在python中运行。
Python先把代码编译成字节码,在对字节码解释执行。字节码在python虚拟机程序里对应的是PyCodeObject对象,pyc文件是字节码在磁盘上的表现形式。
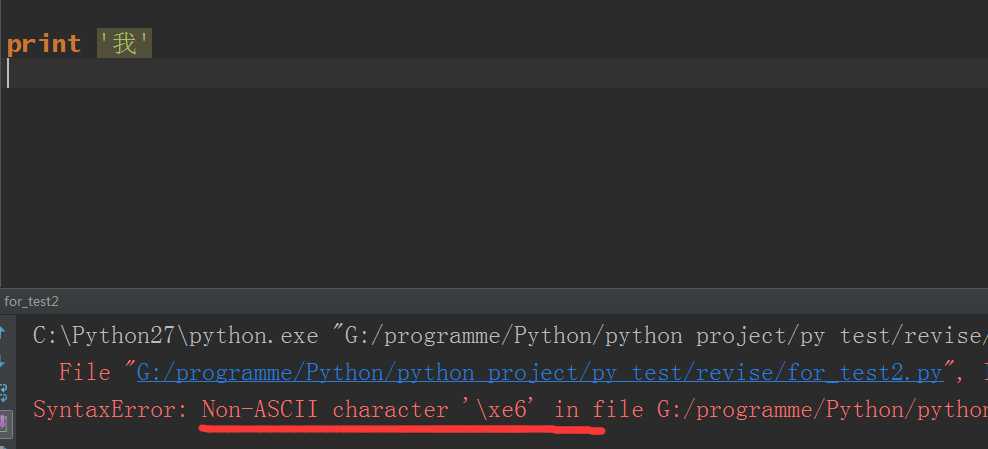
2.不加为什么会报错?
答:如果不加utf-8的话,是一定会报错的,报错提示的意思就是没有设置默认编码
在python3里,官方已经把这个编码问题解决了,因为python2的编码问题(默认是ASCII)确实很烦,在后面说到爬虫时很能体现这个问题
注意如果在python3下打印这段代码
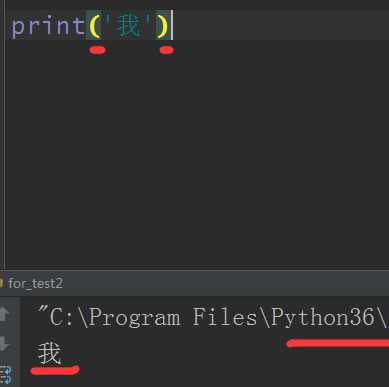
注意:
- 1.在python3里已经把print改为一个内置函数,不再是一个语法关键词,所以必须加括号,在python2里如果printt加上括号也是可以的,不会报错
- 2.python3里的默认编码已经是Unicode,解决了编码问题,所以可以正常打印,但是建议还是加上默认编码:#-*- coding:utf-8 -*-,其实直接写 #coding:utf-8也是可以的,但是前者写法是国际习惯,一个好的习惯可以体现你的编程能力
- 3.如果要打印字符串,必须用引号包括住,后面在类型篇会讲到
- 如果你使用的是python自带的IDLE,在python2里IDLE用的是cp936编码,是ASCII码的一种
3.为什么又会只使用utf-8编码?
答:前面编码问题已经说了,Unicode是一个大一统,utf-8属于Unicode的一种,也是最优的选择,可以兼容各个国家的语言,所以要使用utf-8
4.print这个单词,我可以写其他的吗?如果我想打印一段中文,怎么打印?
答:python的关键词是设定好的语法关键词,不可更改,但可以当作变量重新定义,但原则上不要重新定义,也不能使用其他来代替。
打印中文的效果上面已经给出,附上代码自己练习:
# -*- coding:utf-8 -*- print(‘我‘)
5.使用python3可以吗?
答:可以的,完全没问题,注意print语法就行
以上是关于洗礼灵魂,修炼python--从一个简单的print代码揭露编码问题,运行原理和语法习惯的主要内容,如果未能解决你的问题,请参考以下文章