《Linux内核设计与实现》学习总结 Chap18
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Linux内核设计与实现》学习总结 Chap18相关的知识,希望对你有一定的参考价值。
一、准备开始
1、一个确定的bug,但大部分bug通常都不是行为可靠且定义明确的。
2、一个藏匿bug的内核版本。
3、相关内核代码的知识和运气。
二、内核中的bug
1、bug的表象:
明白无误的错误代码,同步时发生的错误,错误地管理硬件,降低所有程序的运行性能,毁坏数据,使系统处于死锁状态。
2、引用空指针会导致产生一个oops,垃圾数据可能会导致系统崩溃。
三、通过打印来调试
1、printk()是内核的格式化打印函数,与C库提供的printf()函数功能基本相同。
2、printk()在任何时候、任何地方都能调用它。除了系统启动过程中,终端还没有初始化之前,在某些地方不能使用它。
early_printk()在启动过程的初期就具备在终端上打印的能力,但缺少可移植性。
3、printk()和printf()的最主要区别:
printk()可以指定一个日志级别,内核根据这个级别来判断是否在终端上打印消息。
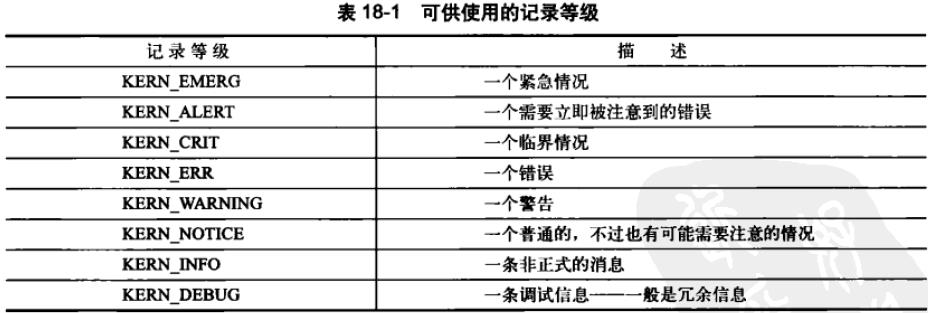
内核同这个指定的记录等级和当前终端的记录等级console_loglevel来决定是不是向终端上打印。
如果你没有特别指定一个记录等级,函数会选用默认的DEFAULT_MESSAGE_LOGLEVEL。
内核将最重要的记录等级KERN_EMERG定为“<0>”,将无关紧要的记录等级KERN_DEBUG定为“<7>”。
例:

当编译预处理完成后,代码被编译成如下格式:

4、给调用的printk()赋记录等级的方法
(1)保持终端的默认记录等级不变,给所有调试信息KERN_CRIT或更低的等级。
(2)给所有调试信息KERN_DEBUG等级,而调整终端的默认记录等级。
5、内核消息都被保存在一个LOG_BUF_LEN大小的环形队列中。
该缓冲区大小可以在编译时通过设置CONFIG_LOG_BUF_SHIFT进行调整,在单处理器的系统上其默认值是16KB。
**使用环形队列的优劣**

6、用户空间的守护进程klogd从记录缓冲区中获取内核消息,再通过syslogd守护进程将它们保存在系统日志文件中。
四、OOPS
1、oops是内核告知用户有不幸发生的最常用的方式。
这个过程包括向终端上输出错误消息,输出寄存器中保存的信息并输出可供跟踪的回溯线索。
2、如果oops在中断上下文时发生,内核根本无法继续,它会陷入混乱,导致系统死机。
如果oops在idle进程(pid为0)或者init进程(pid为1)时发生,结果同样是系统陷入混乱。
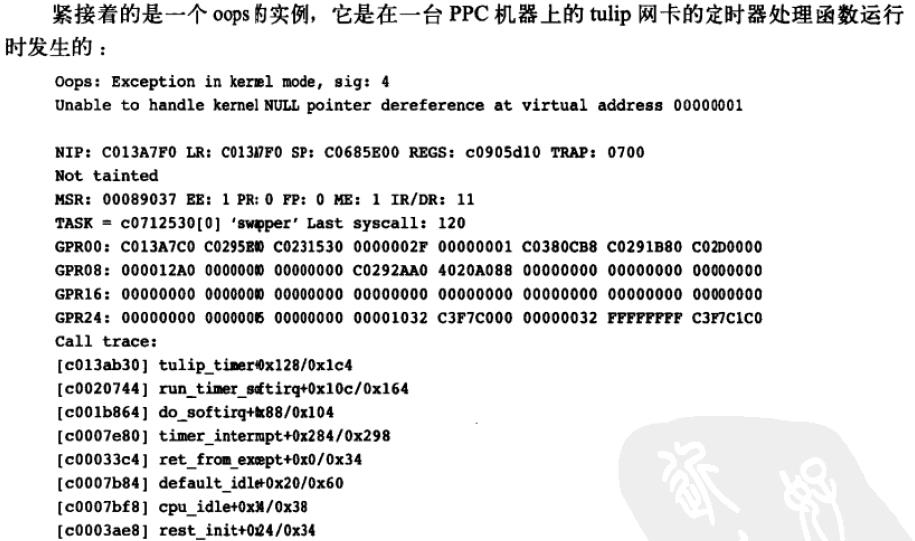
3、oops中包含的重要信息:寄存器上下文和回溯线索。
回溯线索中的地址需要转化成有意义的符号名称:调用ksymoops命令,并且提供编译内核时产生的System.map;如果使用的是模块,还需要一些模块信息。
ksymoops saved_oops.txt
4、kallsyms特性,它可以通过定义CONFIG_KALLSYMS配置选项启用。
五、内核调试配置选项

原子操作:指那些能够不分隔执行的东西,在执行时不能中断否则就是完不成的代码。
六、引发bug并打印信息
1、一些内核调用可以用来方便标记bug,提供断言并输出信息。最常用的两个是BUG()和BUG_ON()。
当被调用的时候,会引发oops。可以把这些调用当做断言使用,想要断言某种情况不该发生:

BUG_ON()比BUG()更清晰、更可读,而且BUG_ON()会将其声明作为一个语句放入unlikely()中。
BUILD_BUG_ON()与BUG_ON()作用相同,仅在编译时调用。
可以用panic()引发更严重的错误:打印错误信息,挂起整个系统,但应该在最糟糕的情况下使用它。

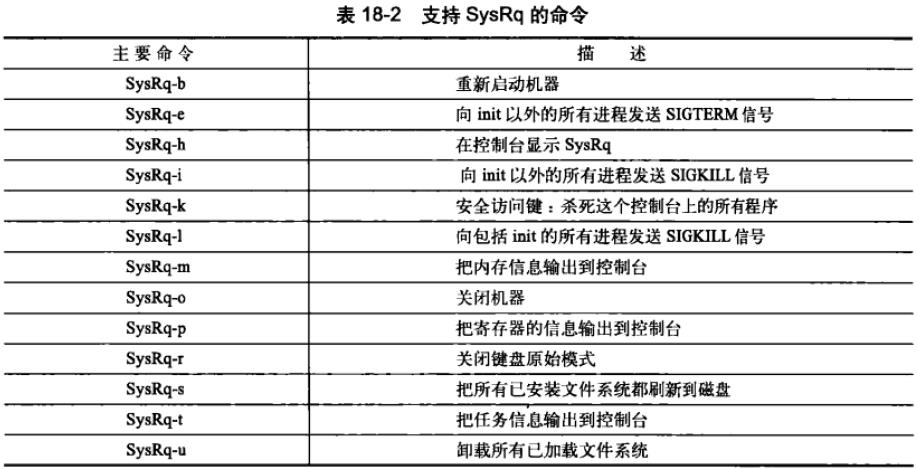
七、神奇的系统请求键
1、神奇的系统请求键(Magic SysRq key),该功能可以通过定义CONFIG_MAGIC_SYSRQ配置选项来启用。当该功能被启用的时候,无论内核处于什么状态,都可以通过特殊的组合键跟内核进行通信。
2、除了配置选项外,还要通过一个sysctl用来标记该特性的开或关:
echo 1 > /proc/sys/kernel/sysrq
八、内核调试器的传奇
1、gdb
可以使用标准的GNU调试器对正在运行的内核进行查看:gdb vmlinux /proc/kcore
其中vmlinux文件时未经压缩的内核映像,它存放在源代码树的根目录上。
/proc/kcore作为一个参数选项,是作为core文件来用的,通过它能够访问到内核驻留的高端内存。
如果编译内核的时候使用-g参数,gdb还可以提供更多的信息。

2、kgdb
是一个补丁,它可以让我们在远端主机上通过串口利用gdb的所有功能对内核进行调试。
九、探测系统
1、用UID作为选择条件


2、使用条件变量
如果代码与进程无关,或者希望有一个针对所有情况都能使用的机制来控制某个特性,可以使用条件变量。
3、使用统计量
需要掌握某个特定事件的发生规律或需要比较多个事件并从中得出规律。
4、重复频率限制:某种事件发生的非常频繁,而又需要观察它的整体进展情况。

发生次数限制:确认在特定情况下某段代码确实被执行了。

不管哪种情况,用到的变量都应该是静态的static,并且应该限制在函数的局部范围以内,这样才能保证变量的值在经历多次函数调用后仍然能够保留下来。
十、用二分查找法找出引发罪恶的变更
一开始,需要一个可靠的可复制的错误,最好是系统一启动就能查证的bug。
接下来,需要一个能确保没问题的内核。
接下来,还需要一个肯定有问题的内核。

十一、使用Git进行二分搜索
一开始,告诉Git进行二分搜索:git bisect start。

如果这个版本一切正常,可以运行下面的命令:git bisect good。
如果证明这个给定的内核版本有bug,可以运行:git bisect bad。
如果你已经知道引发bug的源(比如,x86机型的启动代码),你可以指定git仅仅在与错误相关的目录列表中去二分搜索提交的补丁:git bisect start - arch/x86
总结:
这一章主要介绍了系统调用的知识,与MOOC中的视频教学相辅相成,在许多细节上作了补充,尤其在如何增加一个新的系统调用上介绍的很详细。另外,编写规范的、最优化的、安全的系统调用所遵循的概念和内核接口规范也值得我们注意。
系统调用是利用了软中断的机制,由API、POSIX和C库协调工作。虽然系统调用使用起来非常方便,但仍要尽量避免每出现一种新的抽象就简单的加入一个新的系统调用,而新系统调用增添频率很低也反映出Linux是一个相对较为稳定并且功能已经较为完善的操作系统。
以上是关于《Linux内核设计与实现》学习总结 Chap18的主要内容,如果未能解决你的问题,请参考以下文章
Linux内核设计第二周学习总结 完成一个简单的时间片轮转多道程序内核代码