kmp算法的个人理解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kmp算法的个人理解相关的知识,希望对你有一定的参考价值。
自从从书上看到kmp算法,很长一段时间不能理解其实现的原理是怎样的,以至于很长一段时间查找字符串片段都是用的蛮力查找,网上也找了很多资源,但是仍然感觉没能打通这个任督二脉。遂决定以自己写下自己的一点见解。
规定:StringLength()为求字符串长度的方法。
首先用蛮力查找的方法:

很简单可以发现,每匹配失败一次则模式串 t 将会回溯到开头重新匹配,s回溯到上次开始位置的下一个位置开始匹配,其时间很多都浪费在回溯上,时间复杂度为O(m*n)。当处理大量数据时,劣势将逐渐显现出来,于是kmp算法就能很好的解决这个问题。
kmp算法:
当遇到匹配字符串问题回溯会白白增加时间的消耗,于是怎样解决回溯的问题就能很好的解决这个劣势。kmp算法时间复杂度为O(n),主串不回溯,相当于每个主串字符只匹配一遍,就能匹配出结果。
首先解决模式串每次回溯到第一个字符的问题,能不能只回溯到中间的某个地方,现在我们对字符串“abbabcab”为例进行分析,当此时匹配字符c时匹配失败,可以得到主串里面与字符c匹配失败的字符(记为x)的前5个字符一定是“abbab”,因为匹配失败的字符前面的字符一定匹配成功。这样我们就知道了主串中的几个字符,仔细观察发现c字符前面的字符串“abbab”中前两个字符和后两个字符相同都为“ab”,而且这是除了字符串本身以外靠前字符串和靠后字符串相等的最长串。此时如果模式串回溯到第一个a,主串回溯到第二个模式串b,对应的位置是完全没有必要的。因为模式串c前面的字符都与主串相匹配,回溯后相当于模式串a与b比较。所以我们可以直接将模式串第二个b字符开始与x比较,因为主串x字符前两个字符和模式串第二个b字符的前两个字符相同,都为ab。而此时模式串第二个b所在的位置就是前面的“ab”的长度。我们可以用next数组存储每个模式串字符匹配失败是回溯到的位置。
next数组计算如下:
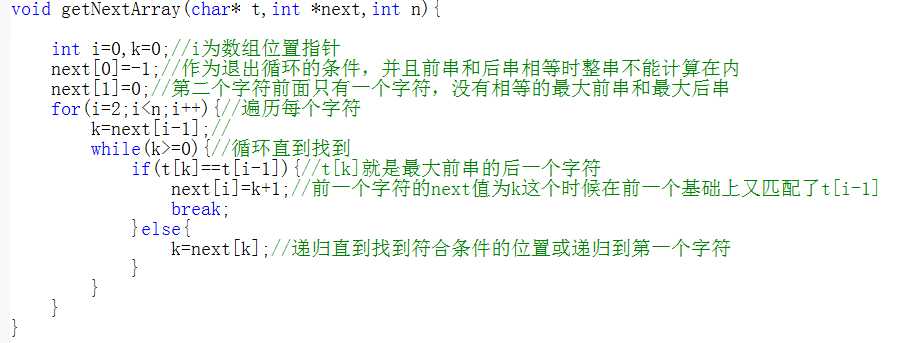
匹配计算如下:

综上所述:kmp算法核心为next数组,其值为对应的模式串字符前面除本身外最大前串和最大后串相等的长度,学会计算next数组的值为重中之重。
以上是关于kmp算法的个人理解的主要内容,如果未能解决你的问题,请参考以下文章