分类不平衡对软件缺陷预测模型性能的影响研究(笔记)
Posted 豆子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分类不平衡对软件缺陷预测模型性能的影响研究(笔记)相关的知识,希望对你有一定的参考价值。
摘要
分类不平衡 : 不同 类别间样本 数量分布不均衡的现象
分类不平衡影响分析方法:
设计一种 新数据集构造算法
将 原不平衡数据集 转换为 一组 不平衡率依次递增的新数据集
然后,选取 不同的 分类模型 作为 缺陷预测模型 ,分别对 构造的 新数据集 进行预测, 采用 AUC 指标来度量 不同预测模型 的 分类性能。
最后, 采用 变异系数C·V 来评价 各个预测模型 在 分类不平衡时的性能稳定程度 。
结果:
C4.5、 RIPPER 和 SMO 三种预测模型的 性能: 随着不平衡率的 增加 而 下降
代价敏感学习 和 集成学习 能够有效 提高它们在分类不平衡时 的 性能 和 性能稳定程度
更稳定: 逻辑回归、 朴素贝叶斯、 随机森林 等
一些解释:
AUC ( Area under curve )
概念: 一个模型评价指标,只能用于二分类模型的评价 (AUC和logloss基本是最常见的模型评价指标),可以避免 把 预测概率 转换成 类别
ROC 曲线:基于样本的 真实类别 和 预测概率 来画的。
二分类问题
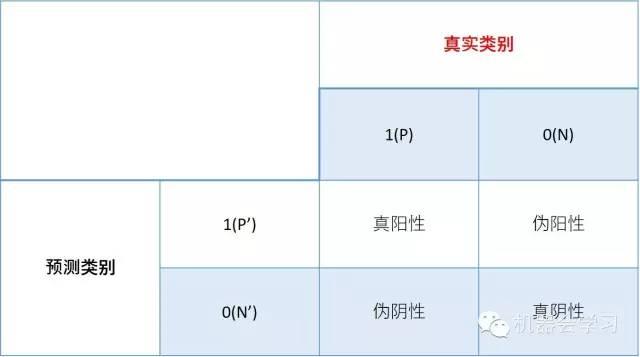
二、解决分类不平衡的方法
-
采样法:
-
过采样(上采样): 增加少数样本
-
欠采样(下采样): 减小多数样本
-
-
代价敏感学习
-
正确识别 少数类 比 正确识别 多数类 更有价值
-
即:错分少数类 比 错分多数类 要付出更大的 代价
-
为不同的类别 赋予 不同的错分代价 提供少数类的 分类性能
-
-
-
集成学习
-
通过 聚集 多个模型的 预测结果 来提高 分类性能。
-
集成模型性能 要 优于 单个模型性能
-
注: 并不是为了解决分类不平衡问题提出的,但是处理其取得较好结果
-
三、预测模型
-
目标: 掌握 不同预测模型 在 分类不平衡时的 性能稳定程度,则可在 实际应用中 针对性地 选择合理的 预测模型。
-
提出 分类不平衡影响分析 方法 ==> 评价 分类不平衡对软件缺陷预测模型性能 的影响程度
四、 分类不平衡影响分析法 (摘要已写)
-
构造 一组 不平衡率依次递增 的 新数据集
-
对构造的新数据集进行 预测
-
ROC 曲线下方的面积 - AUC => 评价 不同预测模型的分类性能
-
采用 变异系数 C · V => 评价不同预测模型 在分类不平衡时 性能稳定程度
-
五、预测模型介绍
-
C4.5
采用新型增益率 选择属性时偏向选择选择值多的属性 的 问题
-
K-Nearest Neighbor (KNN)
K 近邻算法 是 一种 基于实例 的 分类算法
基本思想: 一个样本应与其 特征空间 中 最近邻的k个样本 中的 多数样本 属于同一个类别。
k的取值 会 对分类结果产生影响。
-
Logistic Regression (LR)
-
MultiLayer Perceptron(MLP)
多层感知器 是 一种 前反馈人工神经网络模型
可以解决 线性不可分问题
-
Naive Bayes (NB)
朴素贝叶斯 基于贝叶斯定理的 概率模型
目前使用最广泛 分类模型
-
Random Forest (RF)
随机森林 是 一种 由 多棵决策树组成 的 集成学习模型
对于分类问题,随机森林的输出 是 由 多颗决策树投票 得到的
对于回归问题,依据多颗决策树的 平均值 得到的
-
RIPPER
RIPPER 是一种 基于规则的 分类算法
通过 对 命题规则 进行 重复增量 地 修剪 使得产生的错误最少,其能有效处理噪声数据
-
SMO
SMO 是一种 实现 支持向量机(Support Vector Machine, SVM) 的 序列最小优化(Sequential Minimal Optimization)
将 二次型求解问题 转换为 多个优化子问题, 并采用 启发式搜索策略 进行 迭代求解, 加快算法收敛速度。
六、性能影响
-
分类不平衡影响分析方法
-
新数据集构造
% 需要一组 具有 不同不平衡率的 数据集 % 这里设计了 一种 新数据集 构造算法 % 原不平衡数据集 转换为 一组不平衡率依次递增的 新数据集 function newDataSet = ConvertNewSet(DataSet) ? DefectSet = ConvertToDefect(DataSet); % 有缺陷样本 NonDefectSet = ConverToNonDefect(DataSet); % 无 n1 = DefectSet.size(); % 有缺陷样本数 n1 n2 = NonDefectSet.size(); % 无 r = Math.floor(n2 / n1); % 计算不平衡率 newDataSet = DefectSet; % 用有缺陷样本 初始化 newDataSet restNonDefectSet = NonDefectSet; % 数据集 ? while restNonDefectSet != NULL restNonDefectSet = RandomTreat(restNonDefectSet); % 对其 进行随机化处理 if restNonDefectSet.size() >= 2 * n1 % 从 restNonDefectSet 中随机选取 n1 个样本, 并保存到 newDataSet tmp = RandomSelectSample(restNonDefectSet, n1); newDataSet.append(tmp); % 从restNonDefectSet 中 移除 n1 个样本 restNonDefectSet.remove(tmp) else % 将restNonDefectSet的剩余样本 保存至 newDataSet newDataSet.append(restNonDefectSet); restNonDecfectSet = NULL; end save newDataSet ; % 保存新数据集 end % 返回新数据集 newDataSet;-
以上算法是用 欠采样法 来实现的
-
预测模型评价
基本模型:在 Weka 上实现 (五的8个预测模型) (默认参数)
代价敏感模型 ===> 进行预测,并计算各个预测模型的变异系数C·V
集成模型
目标:
研究 基本模型 在分类不平衡情况性能稳定程度,对于不稳定的预测模型,再进一步探究他们的 代价敏感模型 和 集成模型 的性能稳定程度
采用ROC曲线下方的面积 - AUC 指标进行评价.
ROC :描述分类模型 真正例率TPR 和 假正例率FPR 之间关系的一种图形化方法。
-
-
实验设计
-
哪些模型性能更稳定?
-
不稳定的模型,代价敏感学习是否能提高其性能的稳定程度?
-
集成学习是否能进一步提高其性能稳定程度?
-
采用AUC指标评价模型
-
采用10次10折交叉验证

参考:https://www.zhihu.com/question/29350545
-
实验结果与分析
C·V 值越大,AUC值离散程度 越大,性能越不稳定。
结果:C4.5,RIPPER, SMO 三种预测模型在大部分 数据集上的 C·V 值相对较高 ==》 不稳定
以上是关于分类不平衡对软件缺陷预测模型性能的影响研究(笔记)的主要内容,如果未能解决你的问题,请参考以下文章