第五周——集合ArrayListTreeSet
Posted 7不积跬步无以至千里7
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第五周——集合ArrayListTreeSet相关的知识,希望对你有一定的参考价值。
1
一、 回忆数组
1.1数组
存储同一数据类型的集合容器。
1.2数组的特点
1.只能存储同一种数据类型的数据。
2.一旦初始化,长度固定。
3.数组中的元素与元素之间的内存地址是连续的。
1.3注意事项
Object类型的数组可以存储任意类型的数据。
二、为什么要学习集合
2.1需求
收集我们班同学的兴趣爱好。
数组存储兴趣爱好:
String[] arr = new String[];
难处在于,无法初始化数组的长度,因为每个人的兴趣爱好都不一样,有的人有很多的兴趣爱好,有的人的兴趣爱好比较少。如果给的太短,无法满足兴趣多的人,给的特别长的话浪费空间。
2.2集合
集合是存储对象数据的集合容器。
集合比数组的优势:
-1.集合可以存储任意类型的数据对象,数组只能存储同一种数据类型的数据。
-2.集合的长度是会发生变化的,数据的长度是固定的。
2.3规范

如上图所示,各种各样的形状都是容器,这样的话不利于管理,于是乎,就需要一种规范来约束。在java中接口是用来约束的。也就是说,接口定义了容器的规范,所以说,如果,类实现了规范接口的接口,那么,这个类就是容器。
-----------| Collection 单例集合的根接口。
-------------------|List Collection的子接口。
-------------------|Set Collection的子接口。
List:如果是实现了List接口的集合类,具备的特点:有序,可重复。
Set:如果是实现了Set接口的集合类,具备的特点:无序,不可重复。
三、Collection接口
3.1增加
add(E e) 添加成功返回true,添加 失败返回false.
addAll(Collection c) 把一个集合 的元素添加到另外一个集合中去。

3.2删除
clear()
remove(Object o)
removeAll(Collection c)
例如:c.removeAll(c2);
删除c集合中与c2的交集元素。
retainAll(Collection c)
例如:c.retainAll(c2);
保留交集元素,删除其他元素;上述是保留c集合与c2的交集元素,其他的一并删除。
3.3查看
size()
例如:c.size()
查看元素的个数。
3.4判断
isEmpty() 判断集合是否为空;
contains(Object o) 判断是否存在谋元素:
其实contains方法内部是依赖于equals方法进行比较的。这里调用的是实参的equals()方法。
containsAll(Collection<?> c)
例如:c.containsAll(c2)
判断c集合是否有包含c2集合中的所有元素。
3.5迭代
toArray() 把集合中的元素全部存储到一个Object的数组中返回。
例如: Object[ ] arr =c.toArray();
从Object类型声明变量接收,如果需要其他的类型,则需要进行强制类型转换。
Iterator() 返回的是接口的类型
例如:Iterator it = c.iterator();
Iterator()迭代器:作用,用于抓取集合中的元素。
迭代器,可以想象成抓娃娃机的抓子。而此迭代器是用于抓取集合中的元素的。
疑问:iterator()方法返回的是一个接口类型,为什么接口又可以调用方法可以使用呢? iterator 实际 上返回的是iterator接口的实现类对象。

迭代器的方法:
hasNext() 问是否有元素可遍历。如果有元素可以遍历,返回true,否则返回false 。
next() 获取元素...
Next() 常见异常
java.util.NoSuchElementException
没有元素异常
迭代器在集合中的应用非常广泛,是个重点

remove() 移除迭代器最后一次返回 的元素,如果没有返回,执行该方法,则会报错。
四、集合的体系:
---------|Collection 单列集合的根接口
---------------|List 如果是实现了List接口的集合类,该接口的特点:有序,可重复。
---------------|Set 如果是实现了Set接口的集合类,该接口的特点:无序,不可重复。
五、List 接口中特有的方法:
2.1添加
add(int index, E element)
例如:list.add(1,”赵本山”)把元素添加到集合中的指定索引位置上。
addAll(int index, Collection<? extends E> c)
例如:listaddAll(2,list2)把list2的元素添加到list结合指定索引值的位置上
2.2获取:
get(int index)
例如:list.get(1) 根据索引值获取结合中的元素
indexOf(Object o)
找出指定元素第一次出现在集合中 的索引值
lastIndexOf(Object o)
找指定的元素最后一次出现在集合中的索引值
subList(int fromIndex, int toIndex)
例如:List subList = list.subList(1, 3); //指定开始与结束的索引值截取集合中的元素
2.3修改:
set(int index, E element)
例如:list.set(3, "赵本山"); //使用指定的元素替换指定索引值位置的元素。
2.4迭代
listIterator()
2.5有序
集合的有序不是指自然顺序,而是指添加进去的顺序与元素出来的顺序是一致的。
List接口中特有的方法具备的特点:操作的方法都存在索引值
只有List接口下面的集合类才具备索引值。其他接口下面的集合类都没有索引值。
2.6迭代(vip)
listIterator() 返回的是一个List接口中特有的迭代器,他的超级接口是Iterator。
ListIterator特有的方法:
添加:
hasPrevious() 判断是否存在上一个元素。
previous() 当前指针先向上移动一个单位,然后再取出当前指针指向的元素。
next(); 先取出当前指针指向的元素,然后指针向下移动一个单位。
add(E e) 把当前有元素插入到当前指针指向的位置上。
set(E e) 替换迭代器最后一次返回的元素。
六、迭代器需要注意的事项
1.1引包
迭代器所引用的数据包是:java.util.List;
1.2声明
声明需要用List进行声明,不能够用Collection进行声明,只有使用List声明的,才有可能有list特有的方法。
1.3迭代器在变量元素的时候要注意事项:
在迭代器迭代元素 的过程中,不允许使用集合对象改变集合中的元素 个数,如果需要添加或者删除只能使用迭代器的方法进行操作。
如果使用过了集合对象改变集合中元素个数那么就会出现ConcurrentModificationException异常。
迭代元素 的过程中: 迭代器创建到使用结束的时间。
七、List接口下的实现类
1.1集合的体系:
----------| Collection 单列集合的根接口
----------------| List 如果实现了List接口的集合类,具备的特点: 有序,可重复。
----------------------| ArrayList
----------------------| LinkedList
----------------------| Vector(了解即可)
----------------| Set 如果实现了Set接口的集合类, 具备的特点: 无序,不可重复。
1.2ArrayList原理:
使用ArrayList无参的构造函数创建一个 对象时, 默认的容量是多少? 如果长度不够使用时又自增增长多少?
ArrayList底层是维护了一个Object数组实现 的,使用无参构造函数时,Object数组默认的容量是10,当长度不够时,自动增长0.5倍。
ArrayList 底层是维护了一个Object数组实现 的, 特点: 查询速度快,增删慢。
查询快:是由于数组的特点决定的。可以根据索引进行查找。
增删慢:
增加慢的原因:假设现有数组的容量是7,添加第八个元素的时候,由于长度不够,则需要新创建一个1.5倍长度的新数组,然后,把旧数组的内容copy到新的数组中,然后在进行添加。如图所示.

图:添加大数据量的数据
删除慢的原因:删除的原理是先要找到需要删除的元素 ,然后进行删除,删除后,ArrayList会把后面的元素copy到前面的空缺,所以数据量比较庞大。
什么时候使用ArrayList: 如果目前的数据是查询比较多,增删比较少的时候,那么就使用ArrayList存储这批数据。 比如 :高校的 图书馆
八、ArrayList 特有的方法:
1.ensureCapacity(int minCapacity) 可以初始化默认的长度。
2.trimToSize() 将ArrayList调整为列表当前大小。
九、LinkedList的实现原理
1.1 LinkedList底层
LinkedList底层是使用了链表数据结构实现的, 特点: 查询速度慢,增删快。
1.2LinkedList的特有方法
方法介绍
addFirst(E e)
addLast(E e)
getFirst()
getLast()
removeFirst()
removeLast()
1.3LinkedList的数据结构

如上图所示:每个元素不但记录了元素,还记录了内存地址。
1.栈方法 :
主要是用于实现堆栈数据结构的存储方式。
先进后出
push()
pop()
2:队列方法
(双端队列1.5): 主要是为了让你们可以使用LinkedList模拟队列数据结构的存储方式。
先进先出
offer()
poll()
十、Vector(了解即可)
1.Vector底层原理
vector底层也是维护了一个Object的数组实现的,实现与ArrayList是一样的,但是Vector是线程安全的,操作效率低。
2.ArrayList与Vector的区别
相同点: ArrayList与Vector底层都是使用了Object数组实现的。
不同点:
1. ArrayList是线程不同步的,操作效率高。
Vector是线程同步的,操作效率低。
2. ArrayList是JDK1.2出现,Vector是jdk1.0的时候出现的。
十一、集合的体系:
------------| Collection 单例集合的根接口
----------------| List 如果是实现了List接口的集合类,具备的特点: 有序,可重复。
-------------------| ArrayList ArrayList 底层是维护了一个Object数组实现的。 特点: 查询速度快,增删慢。
-------------------| LinkedList LinkedList 底层是使用了链表数据结构实现的, 特点: 查询速度慢,增删快。
-------------------| Vector(了解即可) 底层也是维护了一个Object的数组实现的,实现与ArrayList是一样的,但是Vector是线程安全的,操作效率低。
----------------| Set 如果是实现了Set接口的集合类,具备的特点: 无序,不可重复。
-------------------| HashSet 底层是使用了哈希表来支持的,特点: 存取速度快.
无序: 添加元素 的顺序与元素出来的顺序是不一致的。
-------------------| TreeSet
小例子:
——
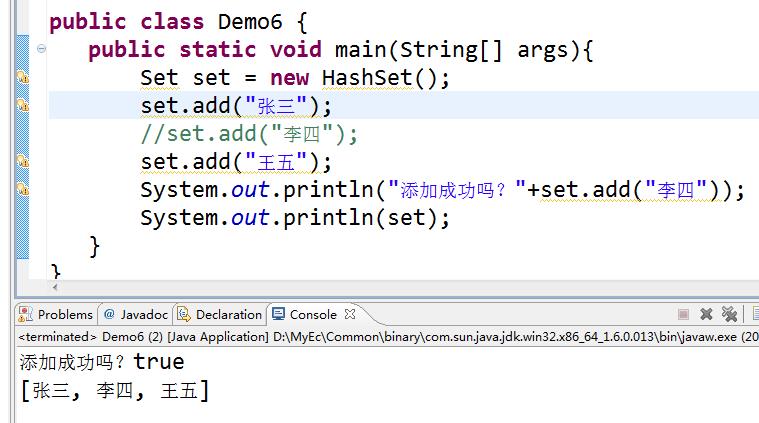
十二、set接口下的实现类------------hashSet的实现原理
往Haset添加元素的时候,HashSet会先调用元素的hashCode方法得到元素的哈希值 ,
然后通过元素 的哈希值经过移位等运算,就可以算出该元素在哈希表中 的存储位置。

情况1: 如果算出元素存储的位置目前没有任何元素存储,那么该元素可以直接存储到该位置上。
情况2: 如果算出该元素的存储位置目前已经存在有其他的元素了,那么会调用该元素的equals方法与该位置的元素再比较一次,如果equals返回的是true,那么该元素与这个位置上的元素就视为重复元素,不允许添加,如果equals方法返回的是false,那么该元素运行 添加。
2.1 哈希表的特点:桶式结构。
即哈希表的一个位置可以存放多个元素。
2.3hashCode()原理

HashCode默认情况下表示的是内存地址,String类已经重写了Object的hashCode方法了。
注意:如果两个字符串的内容一致,那么返回的hashCode码肯定也会一致的。因为String重写Object的hashCode的方法,是将内容存在数组里面了,就已经不是hashCode的内存地址了。
十三、TreeSet
1.往TreeSet中添加自定义元素需要注意的事项:
1. 往TreeSet添加元素的时候,如果元素本身具备了自然顺序的特性,那么就按照元素自然顺序的特性进行排序存储。
2. 往TreeSet添加元素的时候,如果元素本身不具备自然顺序的特性,那么该元素所属的类必须要实现Comparable接口,把元素的比较规则定义在compareTo(T o)方法上。
也就是说,需要把元素与元素之间的比较规则,写在compareTo方法中。
//负整数、零或正整数,根据此对象是小于、等于还是大于指定对象。
Public int compareTo (Object o) {
Emp e = (Emp) o;
Return this.salary-e.salary;
}
官方定义:
如何自定义定义比较器: 自定义一个类实现Comparator接口即可,把元素与元素之间的比较规则定义在compare方法内即可。
自定义比较器的格式 :
class 类名 implements Comparator{
}
推荐使用:使用比较器(Comparator)。
实例代码:

3. 如果比较元素的时候,compareTo方法返回 的是0,那么该元素就被视为重复元素,不允许添加.(注意:TreeSet与HashCode、equals方法是没有任何关系。)
4. 往TreeSet添加元素的时候, 如果元素本身没有具备自然顺序 的特性,而元素所属的类也没有实现Comparable接口,那么必须要在创建TreeSet的时候传入一个比较器。
如何自定义定义比较器: 自定义一个类实现Comparator接口即可,把元素与元素之间的比较规则定义在compare方法内即可。
自定义比较器的格式 :
class 类名 implements Comparator{
}
推荐使用:使用比较器(Comparator)。
5. 往TreeSet添加元素的时候,如果元素本身不具备自然顺序的特性,而元素所属的类已经实现了Comparable接口, 在创建TreeSet对象的时候也传入了比较器,那么是以比较器的比较规则优先使用。
6.TreeSet是可以对字符串进行排序的,因为字符串已经实现了Comparable接口。
字符串的比较规则:
情况一: 对应位置有不同的字符出现, 就比较的就是对应位置不同的字符。
情况 二:对应位置上 的字符都一样,比较的就是字符串的长度。
十四、treeSet的存储原理
1.treeSet存储原理


2.treeSet小练习

以上是关于第五周——集合ArrayListTreeSet的主要内容,如果未能解决你的问题,请参考以下文章