STL标准库-hash
Posted 勿在浮沙筑高台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了STL标准库-hash相关的知识,希望对你有一定的参考价值。
技术在于交流、沟通,本文为博主原创文章转载请注明出处并保持作品的完整性
hash的结构图如下图
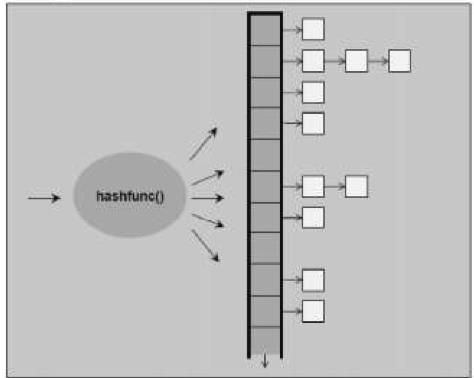 oject通过hashfunc转换成hashcode然后插入到相应篮子中
oject通过hashfunc转换成hashcode然后插入到相应篮子中
hash同rb_tree是一种底层实现,在实际应用中很少能直接用到,但是做为容器的底层实现,所以了解一下还是很有必要的
hash的作用机制可以理解成一个vector上面挂着一些单向链表,vecotr中的元素(篮子buckets)指向单向链表.
hash将传进来的object通过hashfunc转换成相应的数值,然后将这些数值放入指定的篮子中,通常的放入篮子的方法取余操作,
如下面片段

上面的图中我们可以看到该结构一共有53个篮子(vector元素个数),每个篮子下面对应着一个单向链表,hashFunc是取余操作,即value/53,余出几就放在第几个篮子中
如53: 53%53 = 0,那么53应该放在第一个篮子中
55: 55%53 = 2,那么55应该放在第三个篮子中
那么我们放55后又放一个2呢?
2%53 = 2,也应该放在第二个篮子中(在hash上叫做碰撞),这个时候就用到了单向链表,将2串接在55后面
为了保证效率,篮子的个数不应该过多.很多实现方式都是当元素个数大于篮子个数时,扩充篮子,并重新排列
G2.9的扩充规则如下
enum { __stl_num_primes = 28 }; static const unsigned long __stl_prime_list[__stl_num_primes] = { 53ul, 97ul, 193ul, 389ul, 769ul, 1543ul, 3079ul, 6151ul, 12289ul, 24593ul, 49157ul, 98317ul, 196613ul, 393241ul, 786433ul, 1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul, 50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul, 1610612741ul, 3221225473ul, 4294967291ul };
默认的hash的篮子个数为53,然后二倍扩充取最近质数为扩充后的篮子数.如53*2 = 106 最近质数为97
扩充的顺序,跟vector相似.先申请内存,然后重新排列
扩充后的hashtable应该是这样

重新排列:这个时候53%97 = 53 所以53应该放在第54个篮子中
55%97 = 55 放在第56个篮子中
2%97 = 2 放在第三个篮子中
如果继续追加元素当元素个数大于篮子个数时在扩充这个时候会扩充到193个篮子,然后再重新排序.....,以上就是hash的概括知识
我们结合一下上面提到的内容一起看看G2.9的源码实现.现在已经是G4.9.但是4.9有些不好理解
1.定义
template <class _Val, class _Key, class _HashFcn, class _ExtractKey, class _EqualKey, class _Alloc> class hashtable { //参数1 _Key key值 参数2 _Value value值 参数3 _HashFcn 获取转换之后key值 参数4 ExtractKey key的萃取机 参数5 _Equal 比较key是否相等 参数6 _Allocator 分配器 public: typedef _Key key_type; typedef _Val value_type; typedef _HashFcn hasher; typedef _EqualKey key_equal; typedef size_t size_type;//元素个数 typedef ptrdiff_t difference_type; typedef value_type* pointer; typedef const value_type* const_pointer; typedef value_type& reference; typedef const value_type& const_reference; hasher hash_funct() const { return _M_hash; }//取篮子编号函数,即上面的_HashFcn key_equal key_eq() const { return _M_equals; }//判断key是否相等 private: typedef _Hashtable_node<_Val> _Node;//节点 ... private: hasher _M_hash; key_equal _M_equals; _ExtractKey _M_get_key; vector<_Node*,_Alloc> _M_buckets;//用vector维护buckets size_type _M_num_elements;//hashtable中list节点个数即元素个数 ... }
2.节点
它有一个成员变量_Node,他的实现如下,就是我上文提到的vector上面挂载的list
//hashtable中链表的节点结构 //类似于单链表的节点结构 template <class _Val> struct _Hashtable_node { _Hashtable_node* _M_next;//指向下一节点 _Val _M_val;//节点元素值 };
3.初始化篮子个数_M_initialize_buckets(size_type __n)
//预留空间,并将其初始化为0 void _M_initialize_buckets(size_type __n) { //返回大于n的最小素数__n_buckets(就是上面的53 97 193...) const size_type __n_buckets = _M_next_size(__n); //这里调用vector的成员函数reserve //reserve该函数功能是改变可用空间的大小 //Requests that the vector capacity be at least enough to contain __n_buckets elements. _M_buckets.reserve(__n_buckets);//vector.reserve //调用vector的插入函数insert //在原始end后面连续插入__n_buckets个0 _M_buckets.insert(_M_buckets.end(), __n_buckets, (_Node*) 0); _M_num_elements = 0; }
4.hashFunc
//获取键值key在篮子的位置 size_type _M_bkt_num_key(const key_type& __key) const { return _M_bkt_num_key(__key, _M_buckets.size()); } //获取在篮子的序号,也就是键值 //输入参数是实值value size_type _M_bkt_num(const value_type& __obj) const { return _M_bkt_num_key(_M_get_key(__obj)); } size_type _M_bkt_num_key(const key_type& __key, size_t __n) const { return _M_hash(__key) % __n;//最后都是采取取余 }
5.insert_unique冲入不可重复元素
pair<iterator, bool> insert_unique(const value_type& __obj) { //判断容量是否够用, 否则就重新配置 resize(_M_num_elements + 1); //插入元素,不允许存在重复元素 return insert_unique_noresize(__obj); }
resize()
//调整hashtable的容量 //新的容量大小为__num_elements_hint template <class _Val, class _Key, class _HF, class _Ex, class _Eq, class _All> void hashtable<_Val,_Key,_HF,_Ex,_Eq,_All> ::resize(size_type __num_elements_hint) { //hashtable原始大小 const size_type __old_n = _M_buckets.size(); if (__num_elements_hint > __old_n) {//若新的容量大小比原始的大 //查找不低于__num_elements_hint的最小素数 const size_type __n = _M_next_size(__num_elements_hint); if (__n > __old_n) { //创建新的线性表,容量为__n,只是起到中介作用 vector<_Node*, _All> __tmp(__n, (_Node*)(0), _M_buckets.get_allocator()); __STL_TRY {//以下是复制数据 for (size_type __bucket = 0; __bucket < __old_n; ++__bucket) { _Node* __first = _M_buckets[__bucket]; while (__first) { //获取实值在新篮子的键值位置 size_type __new_bucket = _M_bkt_num(__first->_M_val, __n); //这个只是为了方便while循环里面__first的迭代 _M_buckets[__bucket] = __first->_M_next; //将当前节点插入到新的篮子__new_bucket里面,成为list的第一个节点 __first->_M_next = __tmp[__new_bucket];//__first->_M_next指向null指针,因为新篮子是空的 __tmp[__new_bucket] = __first;//新篮子对应键值指向第一个节点 __first = _M_buckets[__bucket];//更新当前指针 } } _M_buckets.swap(__tmp);//交换内容 } # ifdef __STL_USE_EXCEPTIONS catch(...) {//释放临时hashtable的线性表tmp for (size_type __bucket = 0; __bucket < __tmp.size(); ++__bucket) { while (__tmp[__bucket]) { _Node* __next = __tmp[__bucket]->_M_next; _M_delete_node(__tmp[__bucket]); __tmp[__bucket] = __next; } } throw; } # endif /* __STL_USE_EXCEPTIONS */ } } }
insert_unique_noresize
//插入元素,不需要重新调整内存空间,不允许存在重复元素 template <class _Val, class _Key, class _HF, class _Ex, class _Eq, class _All> pair<typename hashtable<_Val,_Key,_HF,_Ex,_Eq,_All>::iterator, bool> hashtable<_Val,_Key,_HF,_Ex,_Eq,_All> ::insert_unique_noresize(const value_type& __obj) { //获取待插入元素在hashtable中的篮子位置 const size_type __n = _M_bkt_num(__obj); _Node* __first = _M_buckets[__n]; //判断hashtable中是否存在与之相等的键值元素 //若存在则不插入 //否则插入该元素 for (_Node* __cur = __first; __cur; __cur = __cur->_M_next) if (_M_equals(_M_get_key(__cur->_M_val), _M_get_key(__obj))) return pair<iterator, bool>(iterator(__cur, this), false); //把元素插入到第一个节点位置 _Node* __tmp = _M_new_node(__obj); __tmp->_M_next = __first; _M_buckets[__n] = __tmp; ++_M_num_elements; return pair<iterator, bool>(iterator(__tmp, this), true); }
6.迭代器
//hashtable迭代器定义 //注意:hash table迭代器没有提供后退操作operator-- //也没用提供逆向迭代器reverse iterator template <class _Val, class _Key, class _HashFcn, class _ExtractKey, class _EqualKey, class _Alloc> struct _Hashtable_iterator { //内嵌类型别名 typedef hashtable<_Val,_Key,_HashFcn,_ExtractKey,_EqualKey,_Alloc> _Hashtable; typedef _Hashtable_iterator<_Val, _Key, _HashFcn, _ExtractKey, _EqualKey, _Alloc> iterator; typedef _Hashtable_const_iterator<_Val, _Key, _HashFcn, _ExtractKey, _EqualKey, _Alloc> const_iterator; typedef _Hashtable_node<_Val> _Node; typedef forward_iterator_tag iterator_category;//采用正向迭代器 typedef _Val value_type; typedef ptrdiff_t difference_type; typedef size_t size_type; typedef _Val& reference; typedef _Val* pointer; _Node* _M_cur;//当前迭代器所指位置 _Hashtable* _M_ht;//hashtable中的位置,控制访问篮子连续性 ... }
operator++满足自动识别到每个list的末端时跳到下一个篮子
//前缀operator++重载,前进一个list节点 template <class _Val, class _Key, class _HF, class _ExK, class _EqK, class _All> _Hashtable_iterator<_Val,_Key,_HF,_ExK,_EqK,_All>& _Hashtable_iterator<_Val,_Key,_HF,_ExK,_EqK,_All>::operator++() { const _Node* __old = _M_cur; _M_cur = _M_cur->_M_next;//若存在,则返回 //若当前节点为空,则需前进到下一个篮子的节点 if (!_M_cur) { //根据元素值,定位出下一个bucket的位置,其起始位置就是我们的目的地 size_type __bucket = _M_ht->_M_bkt_num(__old->_M_val); while (!_M_cur && ++__bucket < _M_ht->_M_buckets.size()) _M_cur = _M_ht->_M_buckets[__bucket]; } return *this; } //后缀operator++重载 template <class _Val, class _Key, class _HF, class _ExK, class _EqK, class _All> inline _Hashtable_iterator<_Val,_Key,_HF,_ExK,_EqK,_All> _Hashtable_iterator<_Val,_Key,_HF,_ExK,_EqK,_All>::operator++(int) { iterator __tmp = *this; ++*this;//调用operator++ return __tmp; }
以上是关于STL标准库-hash的主要内容,如果未能解决你的问题,请参考以下文章