scrapy爬虫框架处理流程简介
Posted pyqb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy爬虫框架处理流程简介相关的知识,希望对你有一定的参考价值。
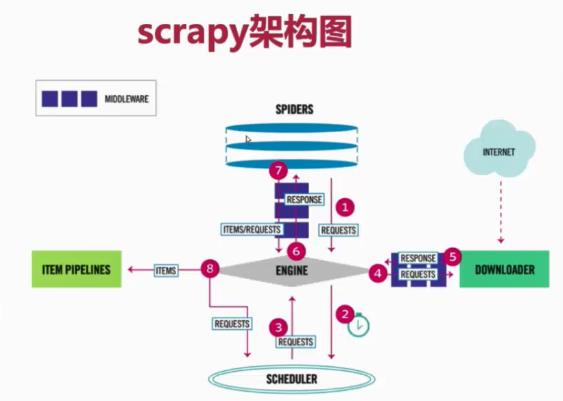
1、SPIDERS的yeild将request发送给ENGIN
2、ENGINE对request不做任何处理发送给SCHEDULER
3、SCHEDULER( url调度器),生成request交给ENGIN
4、ENGINE拿到request,通过MIDDLEWARE进行层层过滤发送给DOWNLOADER
5、DOWNLOADER在网上获取到response数据之后,又经过MIDDLEWARE进行层层过滤发送给ENGIN
6、ENGINE获取到response数据之后,返回给SPIDERS,SPIDERS的parse()方法对获取到的response数据进行处理,解析出items或者requests
7、将解析出来的items或者requests发送给ENGIN
8、ENGIN获取到items或者requests,将items发送给ITEM PIPELINES,将requests发送给SCHEDULER
以上是关于scrapy爬虫框架处理流程简介的主要内容,如果未能解决你的问题,请参考以下文章