语音特征的提取
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语音特征的提取相关的知识,希望对你有一定的参考价值。
一、语音特征
对于语音识别来说,好的语音特征应该:
包含区分音素的有效信息:良好的时域分辨率,良好的频域分辨率;
分离基频F0以及它的谐波成分;
对不同说话人具有鲁棒性;
对噪音或信道失真具有鲁棒性;
有着良好的模式识别特性:低维特征,特征独立(GMM需,NN无需)。
二、提取MFCC特征的整体流程
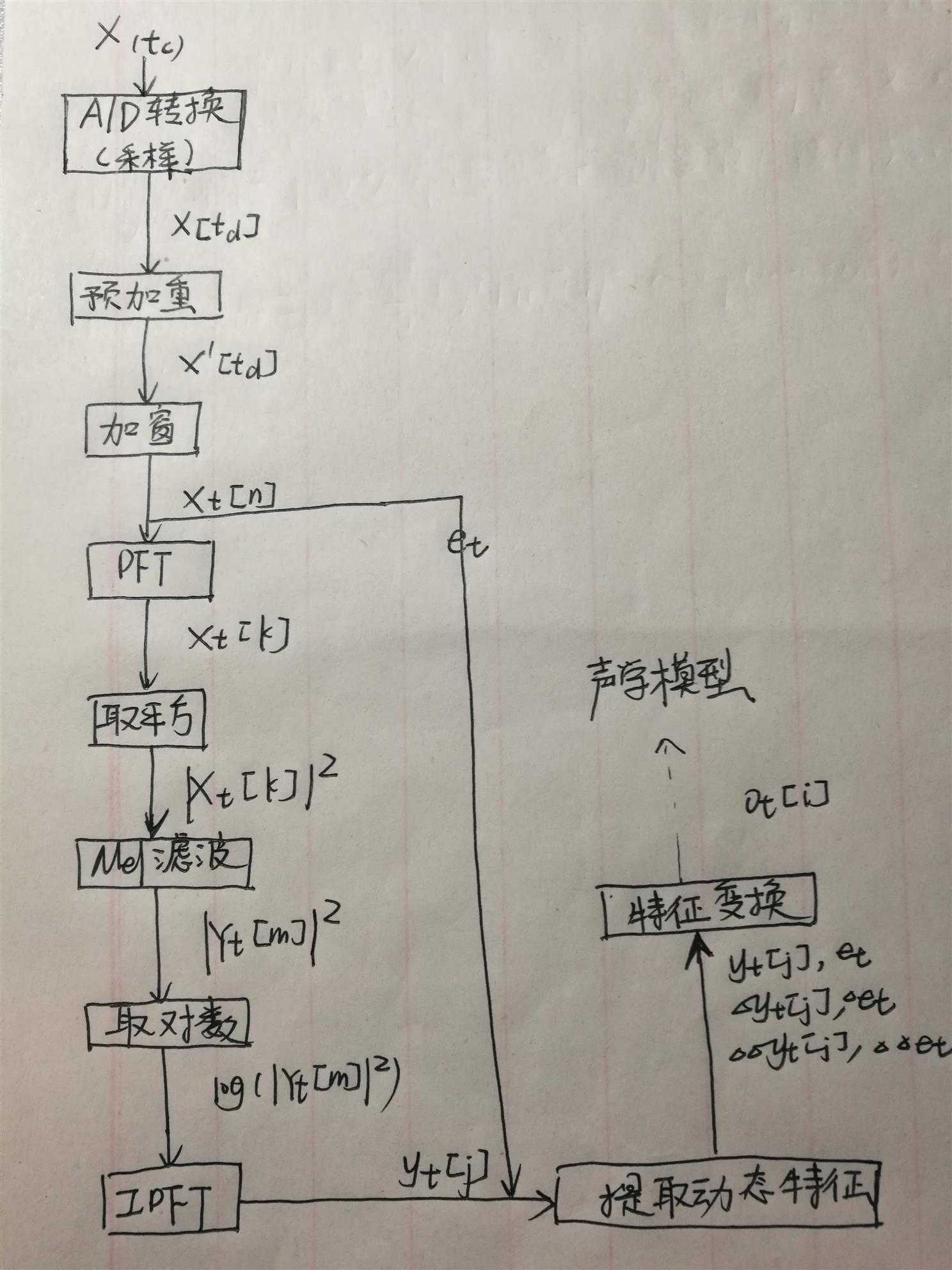
三、提取MFCC特征
(一)A/D转换(采样)

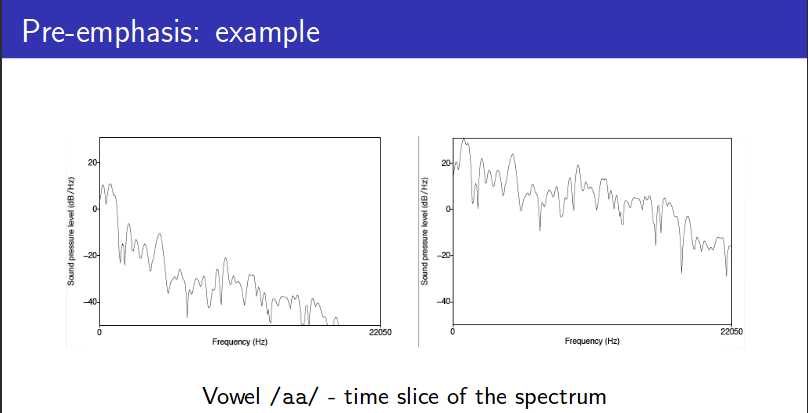
(二)预加重
为消除声门激励、口鼻辐射、传播时高频衰减更大的影响。

(三)加窗
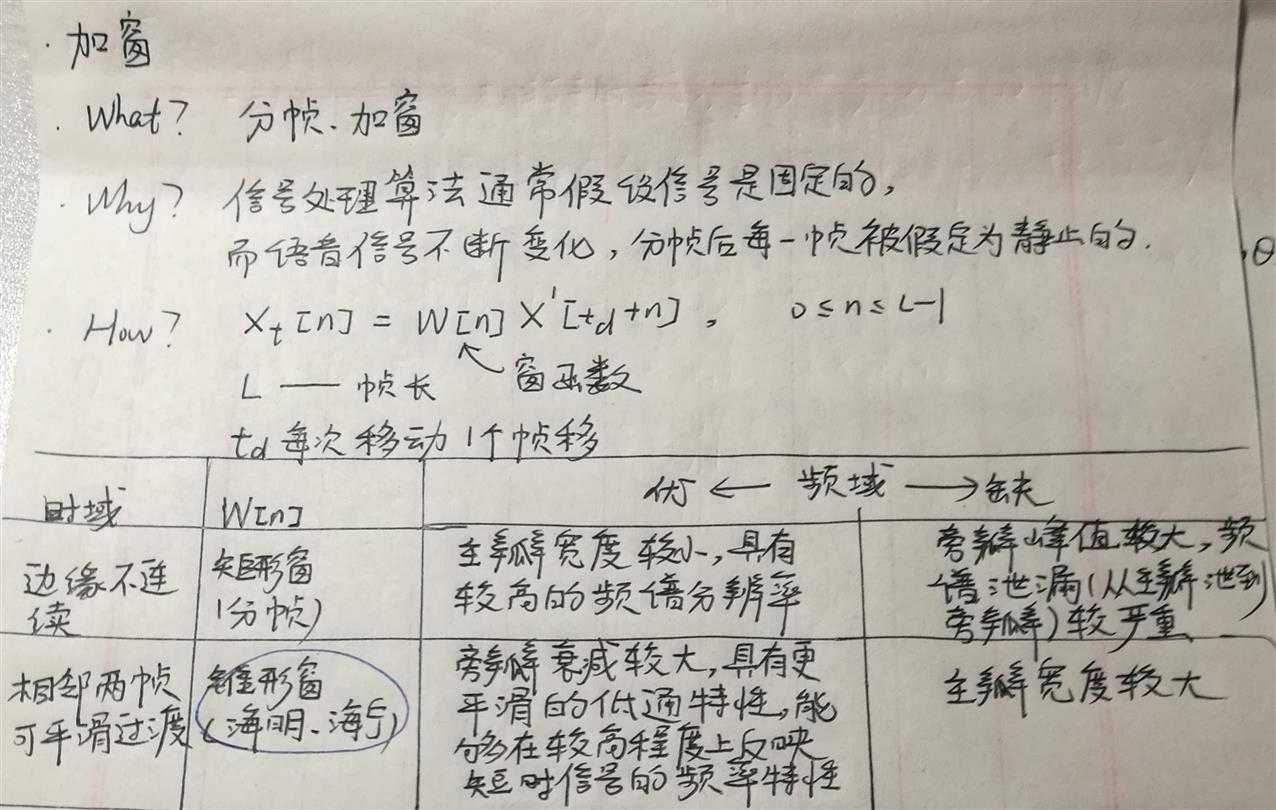
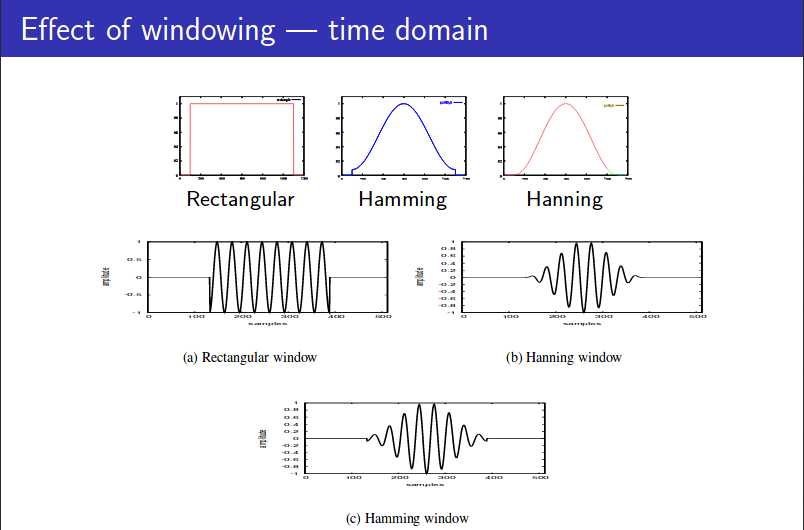
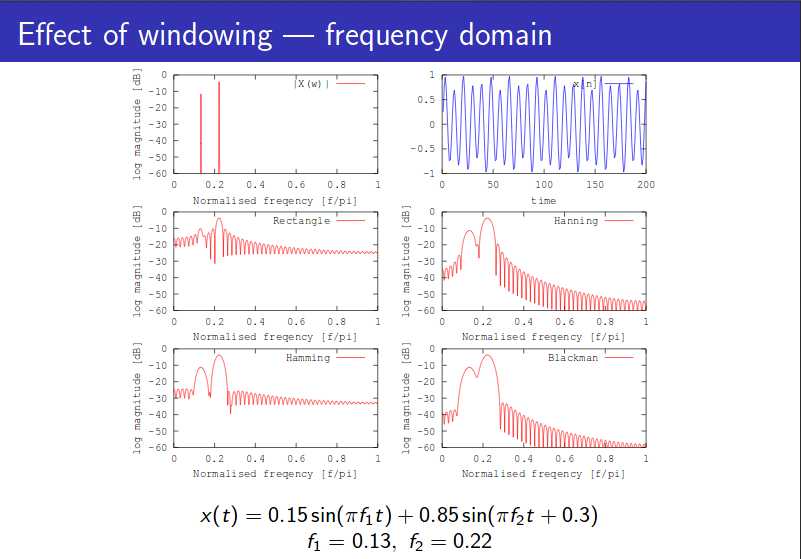
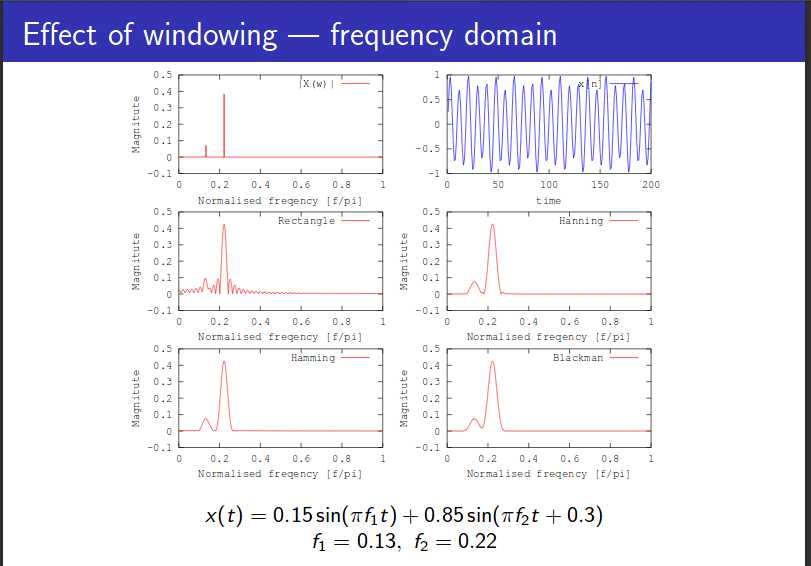
长帧窗对应窄带语谱图,时域分辨率低,频域分辨率高,语谱图线条横向明显;
短帧窗对应宽带语谱图,时域分辨率高,频域分辨率低,语谱图线条纵向明显。
窄带语谱图清晰显示谐波结构,反映基频的时变过程;
宽带语谱图清晰显示共振峰结构和语谱包络,反映频谱快速时变过程。
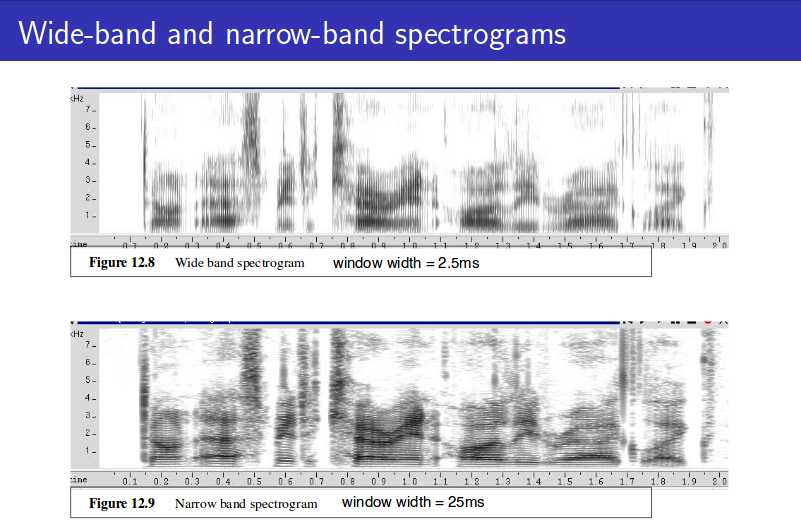
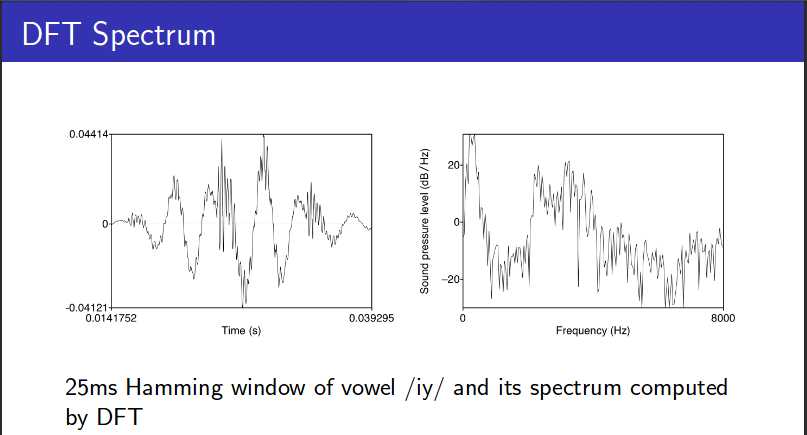
通常ASR中,帧长取25ms,帧移取10ms。
帧移使得帧与帧之间过渡更加平稳,否则,帧与帧连接处的信号会因为加窗而被弱化,这部分信息就丢失了。
加窗后对每一帧计算短时平均能量(一帧样本点的加权平方和)。
(四)DFT+取平方


(五)梅尔滤波


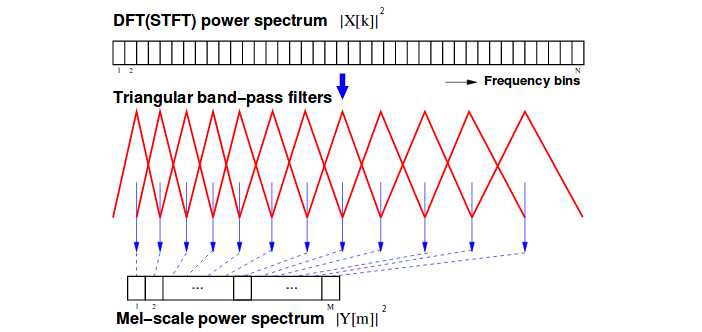
(六)取对数

对数梅尔滤波器组输出/FBANK特征在以DNN-HMM为基础的ASR中广泛应用。
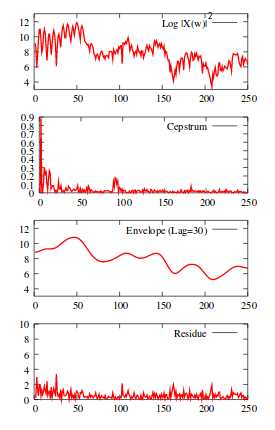
(七)IDFT
生成倒谱系数。

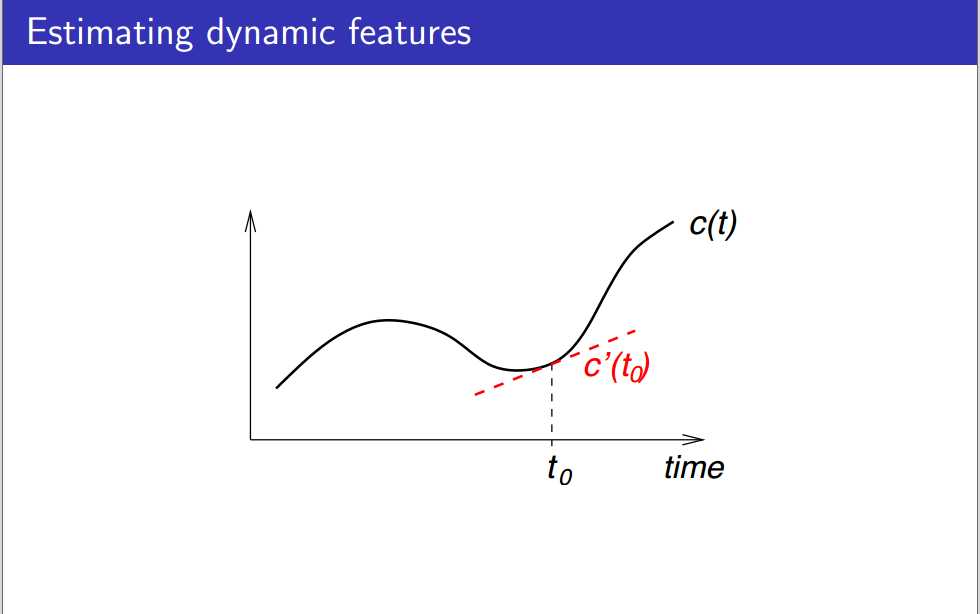
(八)动态特征
描述倒谱系数随着时间的变化。
注意:
通常,一阶差分是计算当前时刻的后一时刻与前一时刻的差值,二阶差分是将一阶差分结果作为当前序列,计算当前时刻的后一时刻与前一时刻的差值,所以一定程度上可以认为当前时刻的动态特征与当前时刻的倒谱系数不相关。
常用于基于GMM-HMM的SR中。

也可以用回归的方法拟合曲线,计算曲线导数/斜率作为动态特征,常前后各取4帧数据进行曲线的拟合。

(九)MFCC总结
在以HMM为基础的ASR中作为声学模型特征广泛使用;
与频谱特征相比,相关性小,更易建模;
用12维的特征描述一个25ms的数据帧,是非常紧凑的表示;
对于标准的基于HMM的系统,MFCCs比滤波器组或频谱图特征产生更好的ASR性能;
对噪声不鲁棒。
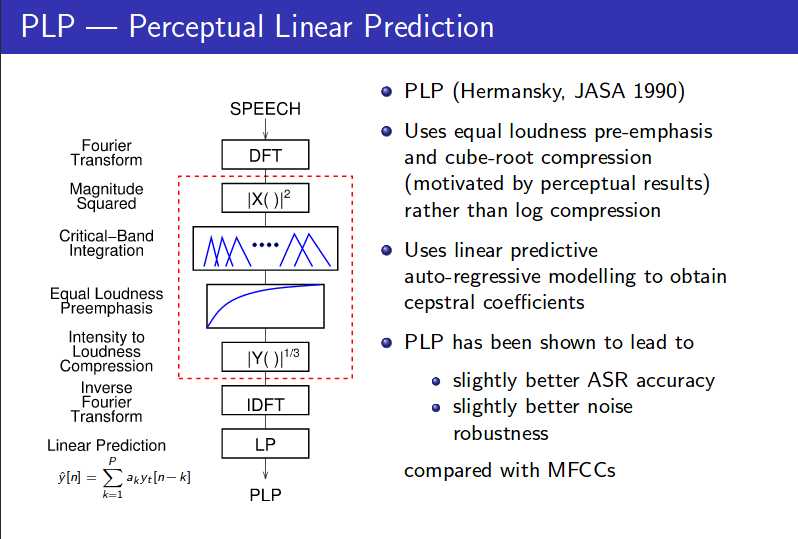
四、PLP特征
五、特征变换及归一化
(一)特征变换
1、正交变换:
DCT、PCA
2、最大化类间可分性:
LDA/Fisher‘s Linear Discriminant、HLDA(异方差性LDA)
(二)特征归一化
CMN:倒谱均值归一化
CVN:倒谱方差归一化
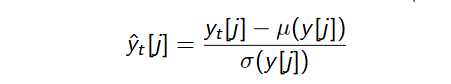
实时归一化:计算移动平均线
以上是关于语音特征的提取的主要内容,如果未能解决你的问题,请参考以下文章