推荐系统--splitting approaches for context-aware recommendation
Posted JD_Beatles
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统--splitting approaches for context-aware recommendation相关的知识,希望对你有一定的参考价值。
开篇语:
大一的时候,在实验室老师和师兄的带领下,我开始接触推荐系统。时光匆匆,转眼已是大三,由于大三课甚是少,于是便有了时间将自己所学的东西做下总结。第一篇博客,献给过去三年里带我飞的老师和师兄们,感谢你们的无私帮助与教导!协同过滤算法:
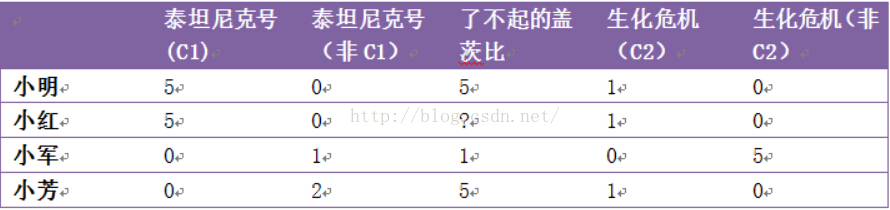
在传统的协同过滤算法中,算法是基于如图一的用户评分矩阵对用户进行推荐的,其核心思想大致是利用相似用户或者相似商品的信息对用户进行推荐,拿图一举例,在这里我们要预测小红对《了不起的盖茨比》这部电影的评分是多少(1-5),一个最简单的想法就是从所有用户中找到跟小红的品味相似的人,一眼望过去,小明跟小红的品味最相近(都是小李子的粉丝?都比较喜欢看煽情一点的电影?),所以我们可以预测小红对《了不起的盖兹比》这部电影的评分应该是比较高的,所以在做电影推荐的时候,我们可以把《了不起的盖茨比》这部电影推荐给小红,这种利用相似用户的信息进行推荐的算法叫做user-based(基于用户的)协同过滤算法,这种而相对应的,就有item-based(基于商品的)协同过滤算法,基于商品协同过滤算法思想大致是,那些跟用户喜欢的商品相似的商品,在某种程度上说用户也应该喜欢,放在这里的话,小红喜欢《泰坦尼克号》这部电影,由于《泰坦尼克号》跟《了不起的盖茨比》比较相似,那么小红也理所当然地喜欢《了不起的盖茨比》这部电影。有关协同过滤算法,这篇博客进行了详细的介绍。
 (图一)
(图一)为了引出下文,这里插个没啥剧情没啥品味的小故事:
Splitting:
splitting的分类:splitting方法分为item-splitting,user-splitting,UI-splitting三种。
splitting的基本思想:
对于某个事物X,如果它随着环境(上下文)的改变,X也发生很大的变化,则应该认为X在不同的环境(上下文)中是属于不同的事物,因此我们应该把它们分割开来,当成不同的事物对待。
splitting的做法:
这里以item-splitting来举例说明,item-splitting嘛,翻译成中文就是“项目-分割”,字面意思就是对一个项目(商品)进行分割,将其分割成几份,既然要分割,我们要拿什么来分割?怎么分割?分割成几份?
分割???~~~

言归正传,先来看第一个和第二个问题,拿什么来分割,怎么分割?看回前面的小故事,我们会很自然而然地想到,这时候我们会用到上下文的信息来对item进行分割,在这里,我们看图二和图三中的两个矩阵:
 (图二)
(图二) (图三)
(图三)图三是用户对泰坦尼克号的评分,而图二是用户在看这部电影时的一些上下文信息,item-splitting方法的思想是利用某个上下文条件对项目尝试进行分割,尝试分割成两个向量后,如果这两个向量有显著地不同,则应该把原来这个项目进行分割,假设上面的上下文条件中,“是否跟恋人”这个上下文条件可以让泰坦尼克号这个列向量在分割之后有显著地不同,则应该将其划分为两个向量,如图四:
 (图四)
(图四)在图四中,依据“是否跟恋人”这个上下文条件对《泰坦尼克号》这个列向量进行分割后,形成了两个不同的向量(跟恋人,不跟恋人),在item-splitting方法中,对应的其实是两个不同的电影。
在这里,引入一个新的问题,如何判断一个向量在分割成两个向量之后,这两个向量有显著的不同,即如何评判泰坦尼克号(跟恋人)和泰坦尼克号(不跟恋人)这两个列向量有显著的不同?
论文[1]中详细地讲解了splitting的整个过程,在这里摘取其中一个评判两个向量是否有显著不同的公式:
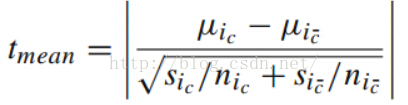 (图五)
(图五)该公式是两个样本的t检验,在p值满足阈值(通常是p<=0.05满足)的情况下,t值越大,这两个向量越不同,其中,Ui是该电影的平均分,Si为该电影的评分方差,ni为该电影有多少个非零值,下标C和非C表示不同的上下文(跟恋人和不跟恋人)。
item-splitting的算法伪代码(摘自论文[1])如图六所示:
 (图六)
(图六)将图一的矩阵在执行item-splitting后,假设除了《了不起的盖茨比》外,其他两部电影都被splitting了,则将会变成如图七的矩阵:
 (图七)
(图七)利用上下文信息得到如图七的矩阵后,可以在该矩阵上套用传统的协同过滤算法。
最后看一下上面说到的分割成几份的问题,在上述过程中,对于每个item,我们都是划分成2份,即是这个上下文的和不是这个上下文的,那么,我们可以将其划分成更多份吗?比如对于图二中的天气这一个上下文维度,对每个项目划分成4份,即晴,下雨,阴天,下雪这四个,可以是可以,但论文[1]有提到这样划分不仅会带来时间成本的增加,也会导致评分矩阵过度稀疏,也会造成过拟合的问题。
splitting方法的优缺点及思考:
首先说下优点,splitting方法可以把有价值的上下文信息融入到传统的协同过滤算法中,从而提升推荐的效果。再来说下缺点,从上面的伪代码来分析,我们可以知道,在上下文的维度很高,且每个维度有很多值的情况下,整个splitting过程是十分耗时的,而且splitting耗费的这些时间不一定能很大幅度的提升推荐的效果,注意我上面说splitting的优点的时候, 有特别地说明“有价值的上下文信息”,但是,什么上下文信息是有价值的呢?这又与业务背景有关,有人专门对上下文的选取做过研究,发现并不是所有的上下文信息都能提升推荐的效果的,有时候引入不恰当的上下文,反而会降低推荐的效果,因此,对于splitting过程中要用什么上下文才能提升推荐效果,这也需要我们对业务背景有一定的了解。
在这里推荐一个github上的有关上下文推荐系统相当不错的项目:
https://github.com/irecsys/CARSKit参考学习资料:
[1]L. Baltrunas and F. Ricci. Experimental evaluation of context-dependent collaborative filtering using item splitting.2013.[2]Yong Zheng,Robin Burke,Bamshad Mobasher.Splitting Approaches for Context-Aware Recommendation: An Empirical Study.2014
以上是关于推荐系统--splitting approaches for context-aware recommendation的主要内容,如果未能解决你的问题,请参考以下文章
文献阅读11期:A Deep Value-network Based Approach for Multi-Driver Order Dispatching
文献阅读11期:A Deep Value-network Based Approach for Multi-Driver Order Dispatching