反-反爬虫:用几行代码写出和人类一样的动态爬虫
Posted 腾讯云加社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了反-反爬虫:用几行代码写出和人类一样的动态爬虫相关的知识,希望对你有一定的参考价值。
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~
作者:李大伟
Phantomjs简介
什么是Phantomjs
Phantomjs官网介绍是:不需要浏览器的完整web协议栈(Full web stack No browser required),也就是常说的无头浏览器——或者好听点叫做:无界面的web解析器。
Phantomjs的特点
由于“无头”——免去了渲染可视化的网页界面,她的速度要比一般的浏览器快不少,又因为她是完整的web协议栈,所以不仅仅提供了javascript API,还完整的支持各类web标准:DOM操作、CSS选择器、JSON、Canvas和SVG,以及文件系统API和操作系统API。此外她还提供很多web事件监控处理接口(event handle),这一点也是Phantomjs区别于selenium等web自动化测试工具的关键所在,具体的将在后续安全检测中详细说明。
笔者将Phantomjs的特征汇总如下表:
Phantomjs提供的API汇总
The WebPage API
- html documents
- DOM
- Handle cookies
- Handle events
- Send requests
- Receive responces
- Wait For AJAX
- User Interaction
- Render Full Images
The System API
- Get OS information
- command-line
The FileSystem API
- Read data from file
- Writing JSON data to file
The WebServer API
- process client requests
小结
鉴于以上特点,我们就会发现Phantomjs特别适合用来写!爬!虫!
支持JavaScript便可以动态加载资源,或完成一些模拟人类的动作;支持DOM操作便可以结构化页面;CSS的支持便可以快捷方便的完成页面文档的渲染,供我们保存图片或到处PDF;支持JSON、Canvas和SVG更是对与数据或多媒体页面处理的加分项;同时文件系统API的提供,也让我们很方便的将处理结果格式化存储起来。
Phantomjs常见的用法
1: 交互模式/REPL/Interactive mode
下载Phantomjs后,直接运行Phantomjs就进入了交互模式,这时我们可以把她当做一个JavaScript解释器使用,运算、js方法、使用window.navigator对象查看“浏览器”信息等等,大家如果安装了Phantomjs可以随意输入一些命令感受一下。感受结束后输入phantom.exit()`退出。
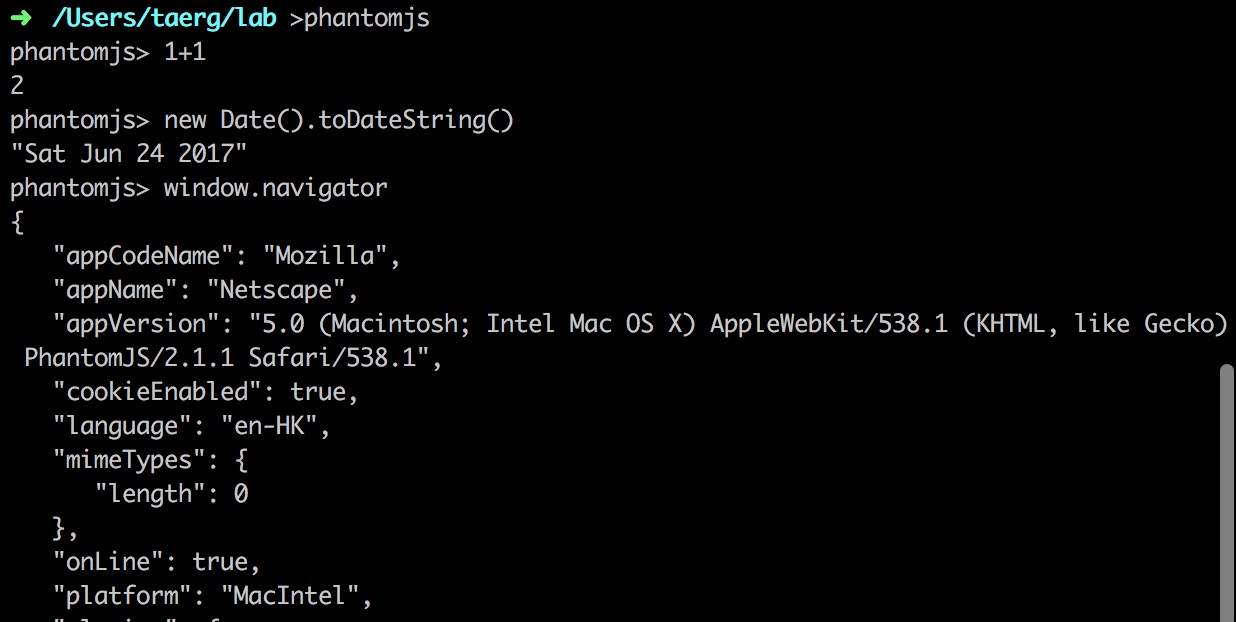
图:REPL 模式下的 Phantomjs
如果是初学js的同学,这个模式可能会比chrome的console栏更大一些,方便用来练习js命令。此外,这个这个模式并不常用,我们更多的是将Phantomjs看做一个二进制工具来使用。
2: 作为一个二进制工具
这也是Phantomjs最常用的一个模式:phantomjs /scripts/somejavascript.js来运行一个JavaScript脚本。脚本中可以使用Phantomjs提供的各类API(KM的markdown语法不支持页内锚点,详见文章前部分的“Phantomjs提供的API汇总”);
打开页面
创建一个webpage的实例,然后使用open方法打开腾讯网首页,如果返回值是成功,则日志打印出网页标题,之后退出。
/**************************************************************** * create an instance of the webpage module * get the page and echo the page‘s title * file: somejavascript.js * auther : Taerg * date : 12/05/2017 *****************************************************************/ var page = require(‘webpage‘).create(); // open the webpage // defined callback: check the status and echo teh status page.open("http://www.qq.com", function(status) { if ( status === "success" ) { console.log("Page load success.The page title is:"); console.log(page.title); } else { console.log("Page load failed."); } phantom.exit(0); });
获取cookie
当然,我们也可以用page.content来获取页面的所有内容,使用page.cookies来获取cookie。
如下,我们获取访问王者荣耀网站时的cookie,并使用键值对的方式打印在log里:
/**************************************************************** * create an instance of the webpage module * echo the cookies * auther : Taerg * date : 12/05/2017 *****************************************************************/ var page = require(‘webpage‘).create(); console.log(1); page.open("http://www.qq.com/", function(status) { if (status === ‘success‘) { var cookies = page.cookies; for(var i in cookies) { console.log(cookies[i].name + ‘=‘ + cookies[i].value); } } phantom.exit(0); });
对应的输出为:
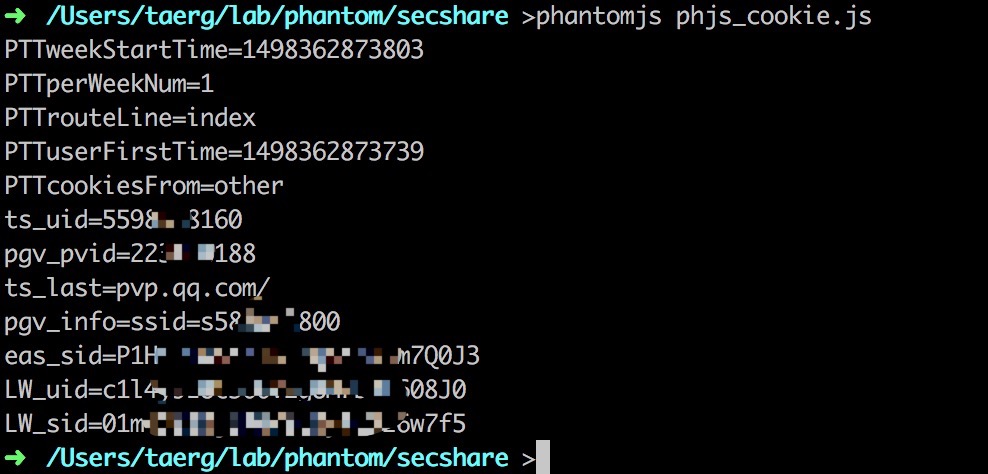
图:phantomjs_getcookie
执行JavaScript
Phantomjs作为无头“浏览器“,当然对JavaScript的支持也是极好的。如下,我们定义了一个简单的函数,来获取页面标题后返回。只需要简单的调用page.evaluate()来执行这段JavaScript代码即可。
/**************************************************************** * create an instance of the webpage module * include system module * auther : Taerg * date : 12/05/2017 *****************************************************************/ var system = require(‘system‘); var url = system.args[1]; console.log(url); var page = require(‘webpage‘).create(); page.open(url, function(status) { if ( status === "success" ) { var title = page.evaluate(function () { return document.title; }); console.log(title); } }) phantom.exit(0);
使用第三方js库(如jQuery)
如果觉得自己用JavaScript代码来重复造轮子太麻烦,我们也可以在Phantomjs中使用第三方的JavaScript库。Phantomjs为我们提供了2中使用第三方库的方法:
- 方法一:includeJs()
- 方法二:injectJs()
二者常常混用,主要的区别在于injectJs是阻塞加载,而includeJs是动态加载。injectJs可以理解为代码执行到这里时,程序阻塞,加载这个js文件到内存后,程序继续运行,在操作页面时不会对这个文件发起请求。而includeJs则是在加载页面用到此js文件时动态加载文件。
实例代码如下:
/**************************************************************** * create an instance of the webpage module * load third part js lib * auther : Taerg * date : 12/05/2017 *****************************************************************/ var page = require(‘webpage‘).create(); // open the webpage page.open("http://www.qq.com", function(status) { page.injectJs(‘jquery321.js‘); //different with page.includeJs if (status === ‘success‘) { var aoffset = page.evaluate(function() { return (typeof jQuery === ‘function‘) ? jQuery.fn.jquery : undefined; }); console.log(aoffset); }else{ console.log(‘open error‘); } phantom.exit(0); });
输出如下:
我们先inject了版本号为3.2.1的本地jQuery文件,之后便可以使用jQuery的方法来查看jQuery版本。当然,这只是验证jQuery加载成功,在我们完全可以使用其他jQuery提供快捷方法来实现我们的需求。
保存指定页面区间截图
在我们处理页面时,常常会有保存页面截图的需求,比如:保存页面BUG的样子、关键信息的留证等等。这时我们就可以使用Phantomjs的page提供的render方法,她支持将完整的页面(自动滚屏截图)、指定区间的页面保存下来(.png, .pdf, .jpg等格式均支持)。
如下,我们想获取天气网站”我的天气“详情,而不去关注网页其他各种新闻和广告,我们只需指定区间,然后保存截图即可:
/**************************************************************** * phjs_clip.js * get the weather pic * auther : Taerg * date : 12/05/2017 *****************************************************************/ var page = new WebPage(); page.open(‘http://www.weather.com.cn‘, function (status) { if (status !== ‘success‘) { output.error = ‘Unable to access network‘; } else { page.clipRect = { top: 200, left: 750, width: 300, height: 500 } page.render(‘weather.png‘); console.log(‘Capture saved‘); } phantom.exit(); });
保存的图片如下所示:
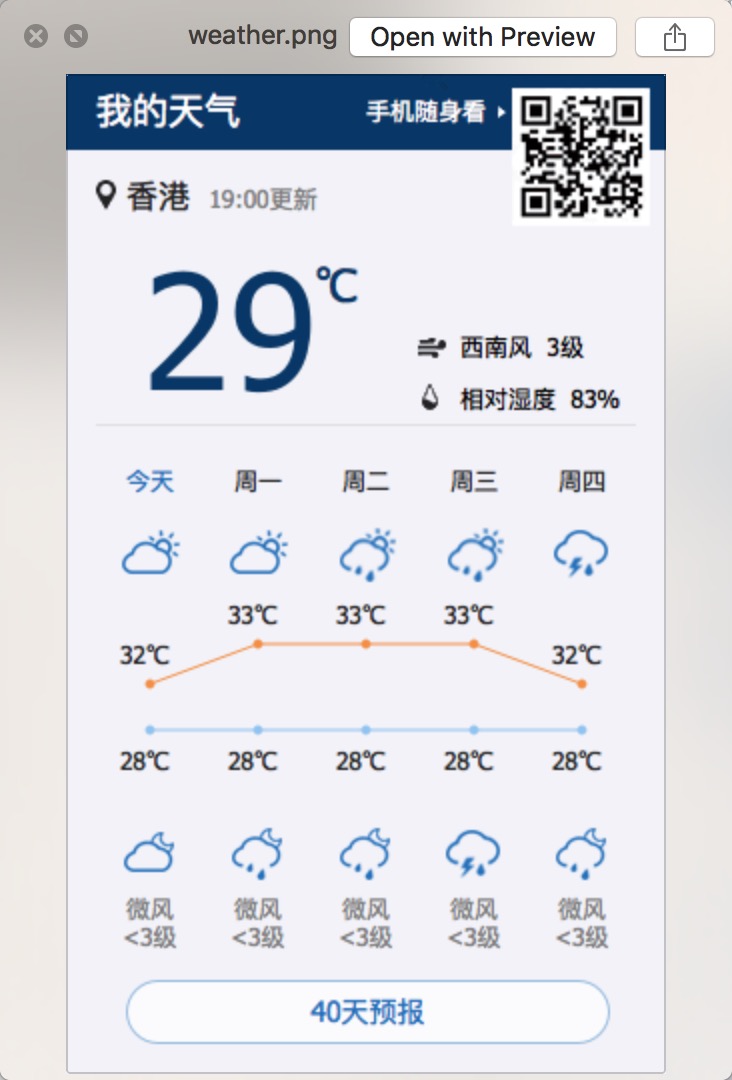
图:phantom_get_weather
三行代码怒怼”反爬虫”
正常用户访问
当我们正常使用浏览器访问https://media.om.qq.com/media/5054676/list 时,一切正常,如下图:
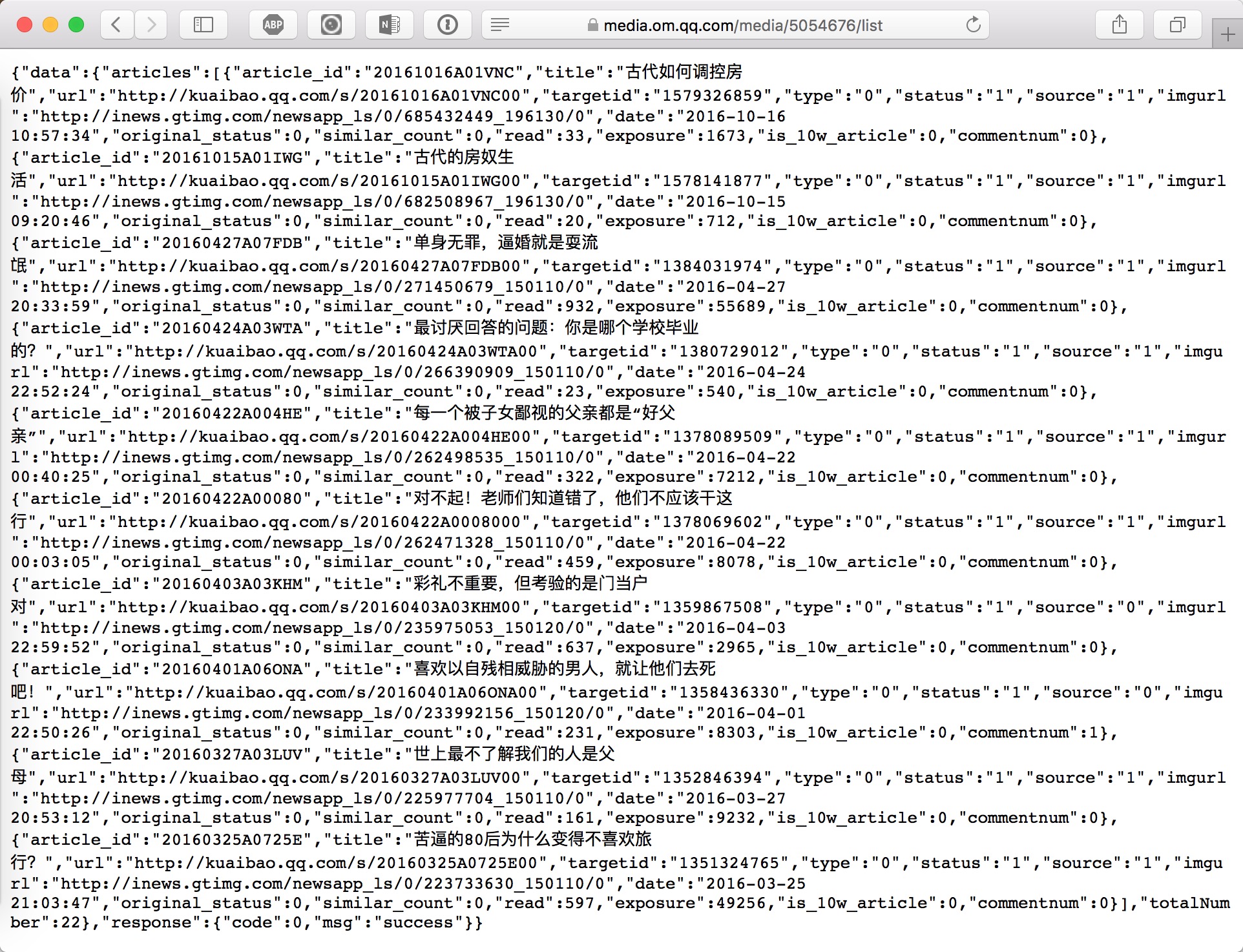
图:safari_get_omqq
根据这套反爬虫作者的解释,客户端经过JavaScript计算出来一个票据,包含在cookie将在服务端再次验证,验证通过则返回数据,验证不通过则不返回数据。如下图所示:
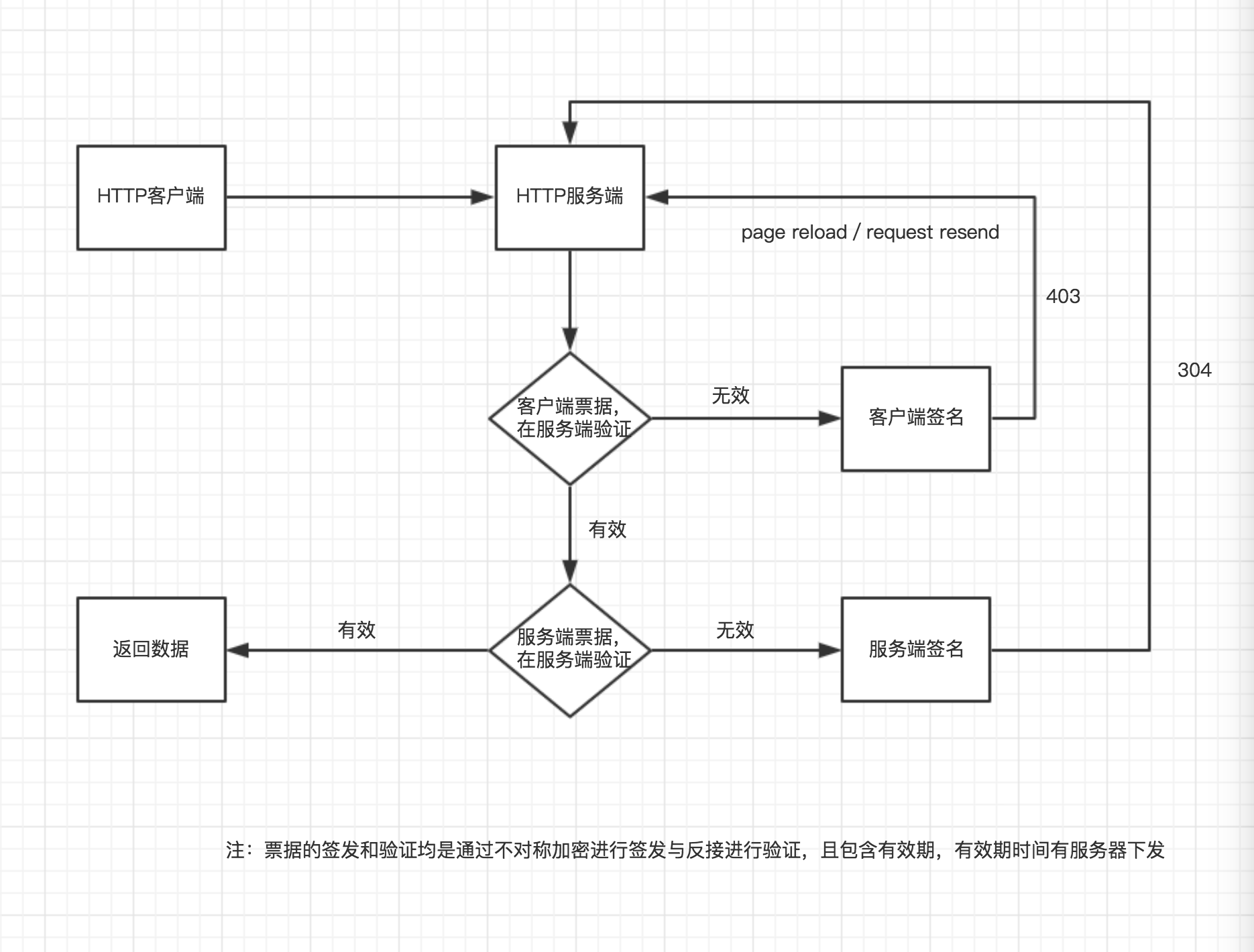
图:anti_spide
下面我们通过脚本来自动拉去这个页面数据试试
普通静态爬虫
- curl get
首先我们先用最简答的curl来get这个页面看看能都拿到这个页面的数据:
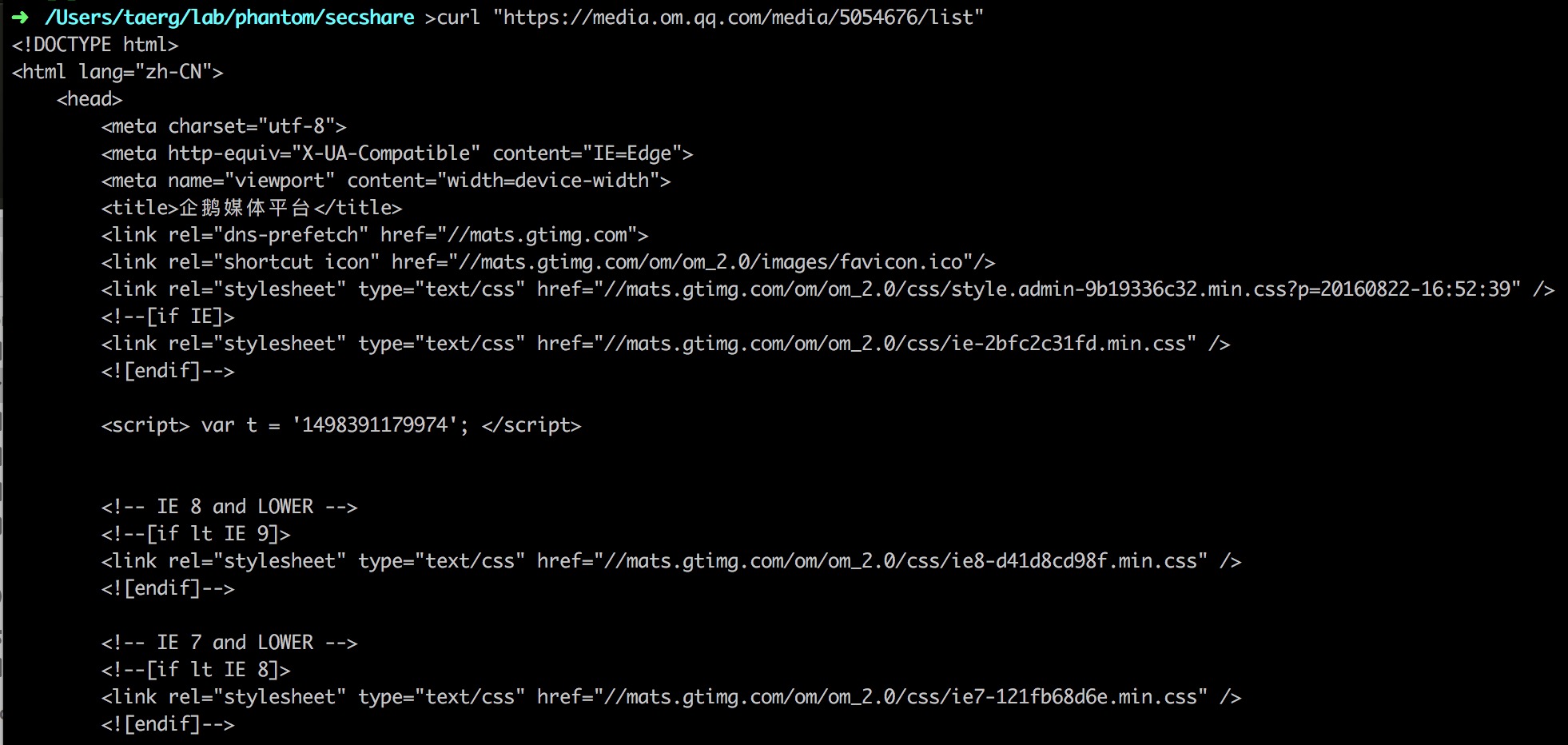
图: curl_get_omqq
如上图所示,被反爬虫系统拦截了。
我们再用Python试试,使用最通用的“HTTP for humans”的requests.get请求:
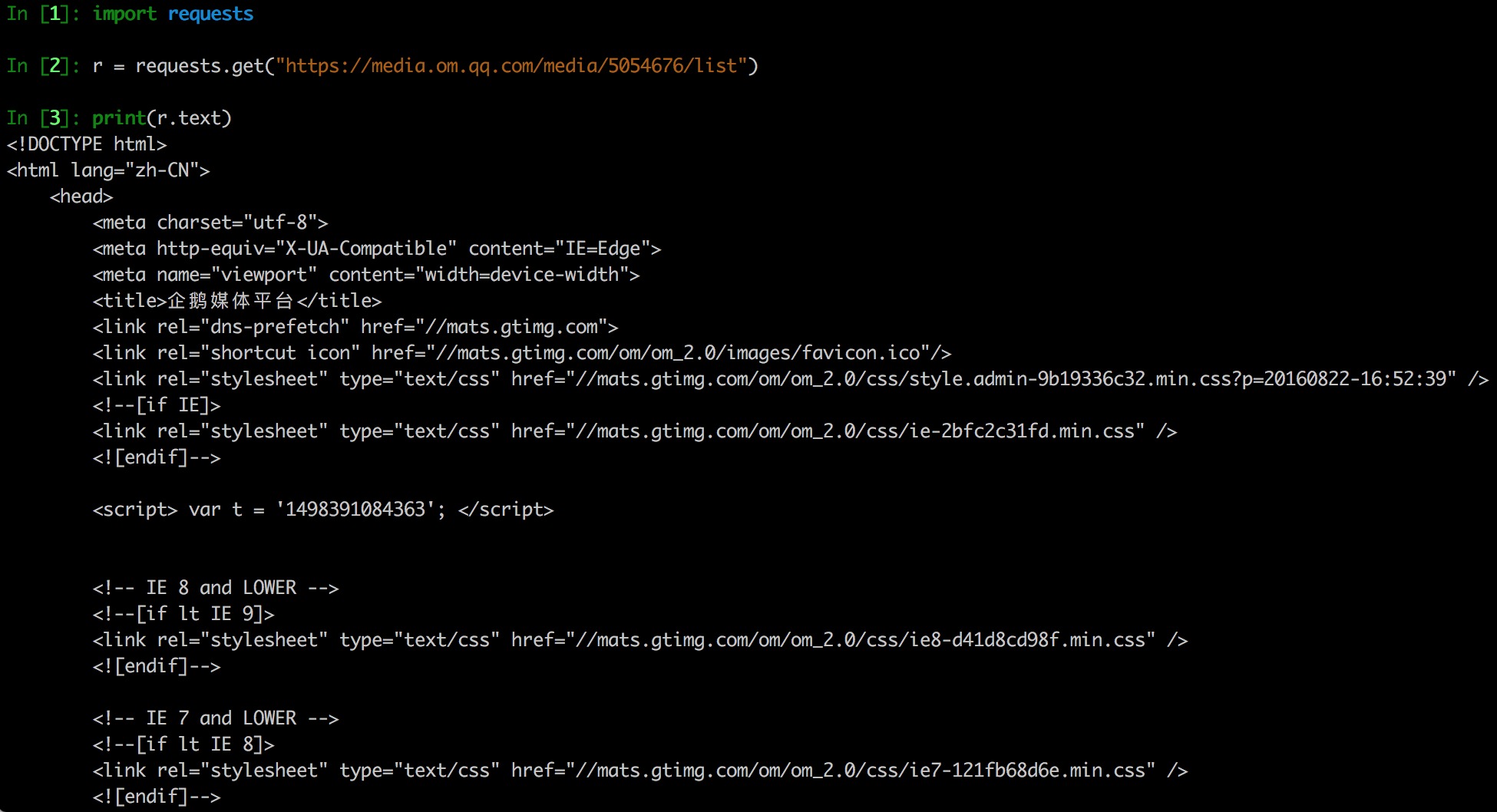
图: request_get_omqq
可以看到依旧会被反爬虫机制拦截。
反爬虫原理分析
通过人工浏览器访问、抓包分析,我们可以看到:
1 . 人工访问这个网页一共发起了6条请求
2 . 第1条请求时直接请求目标url,由于没有合法票据,返回403。同时在403页面中包含了2个JavaScript文件
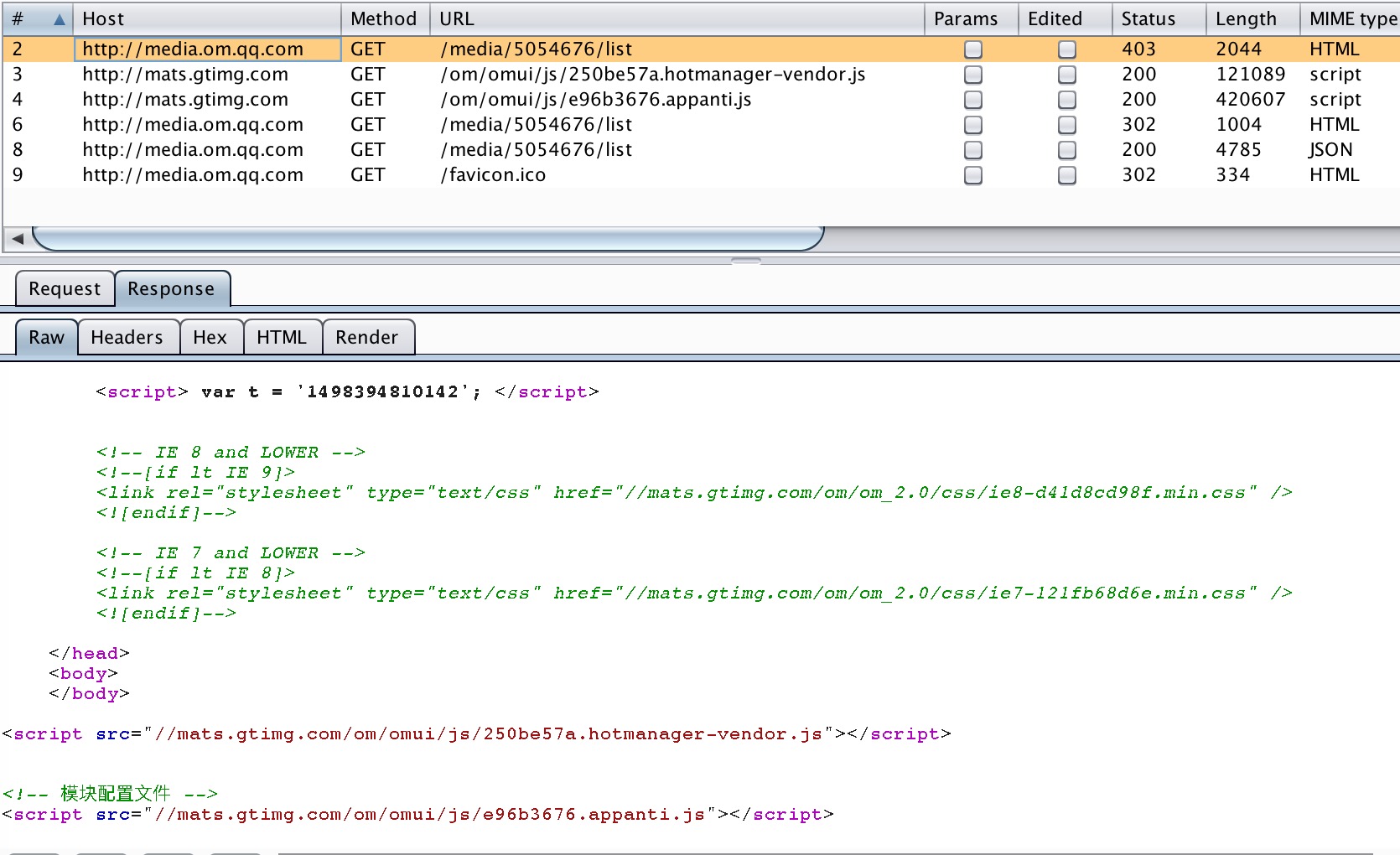
图: load_js
3 .接下来的2个请求分别为对403页面中的JavaScript脚本进行加载
4 .加载运行完毕后,获得了合法票据并添加进cookie中再次发起请求,产生了第4条请求。如下图:
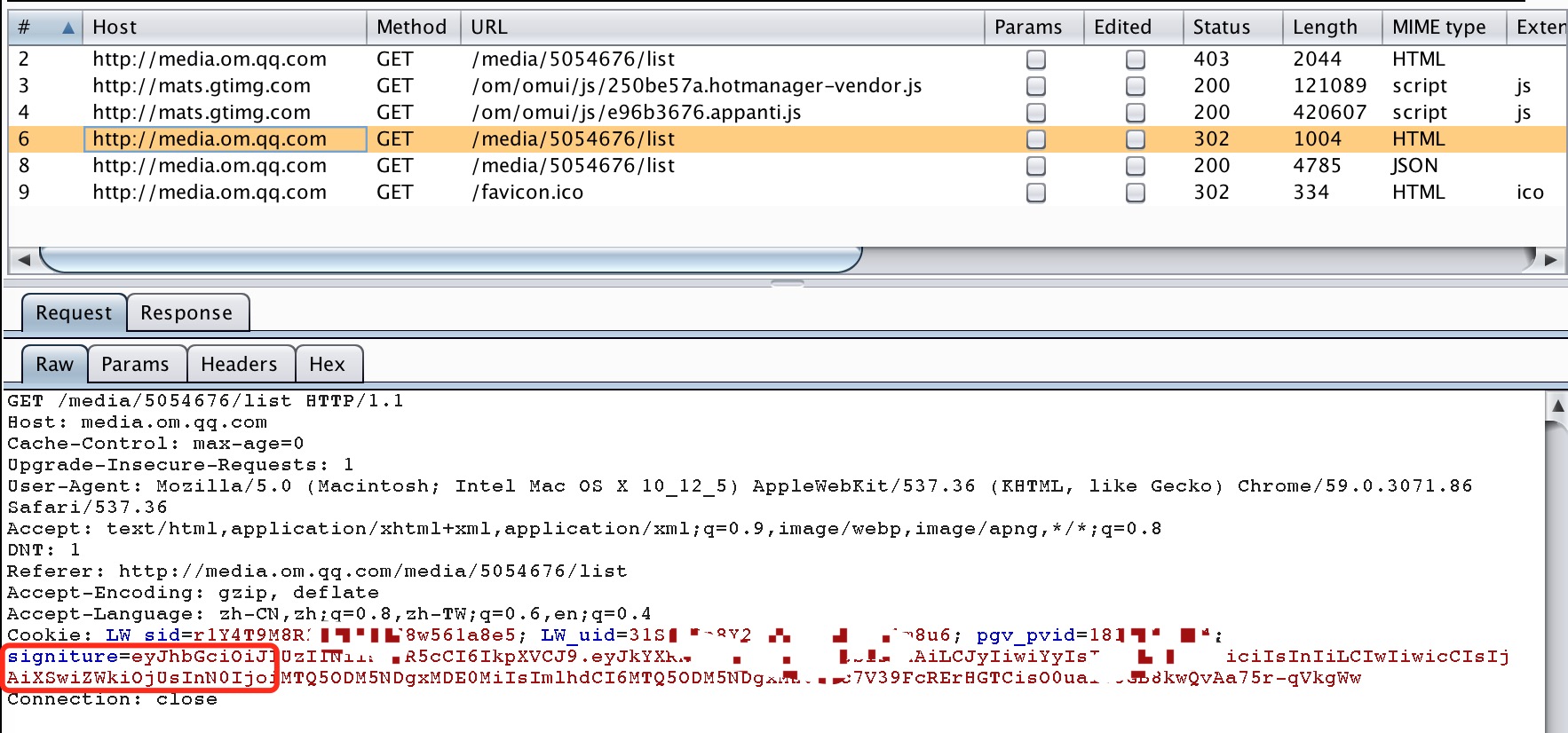
图:omqq_signiture
5.第4条请求带有合法票据,因此没有被403forbidden掉,而是增加一个客户id标示后302跳转到了数据页面。如下图:Set-cookie中添加了id签名。
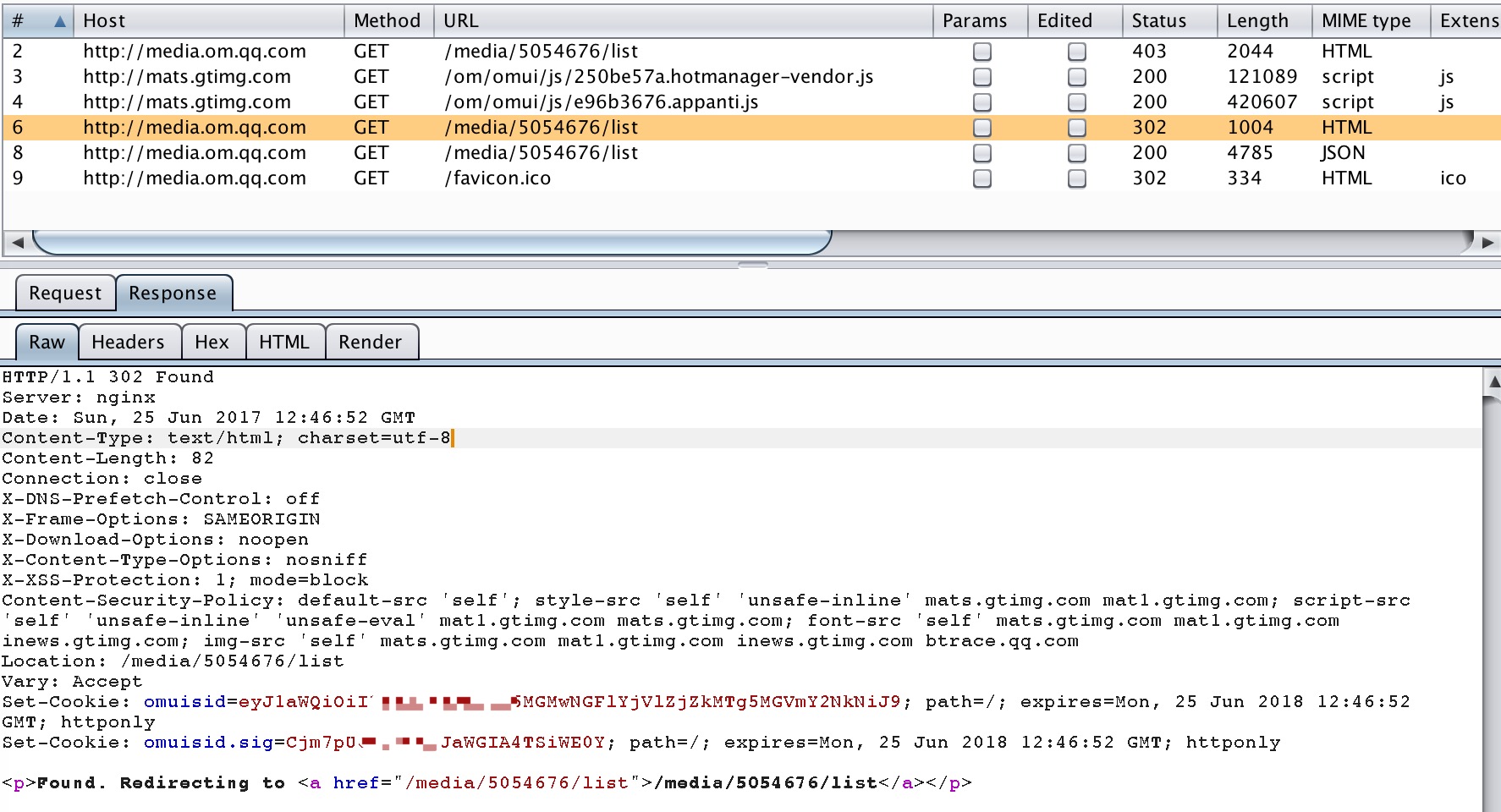
图: redirect
6 .此时,cookie中已经包含有了合法的签名以及客户id,请求到了JSON数据。得到了正常的页面:
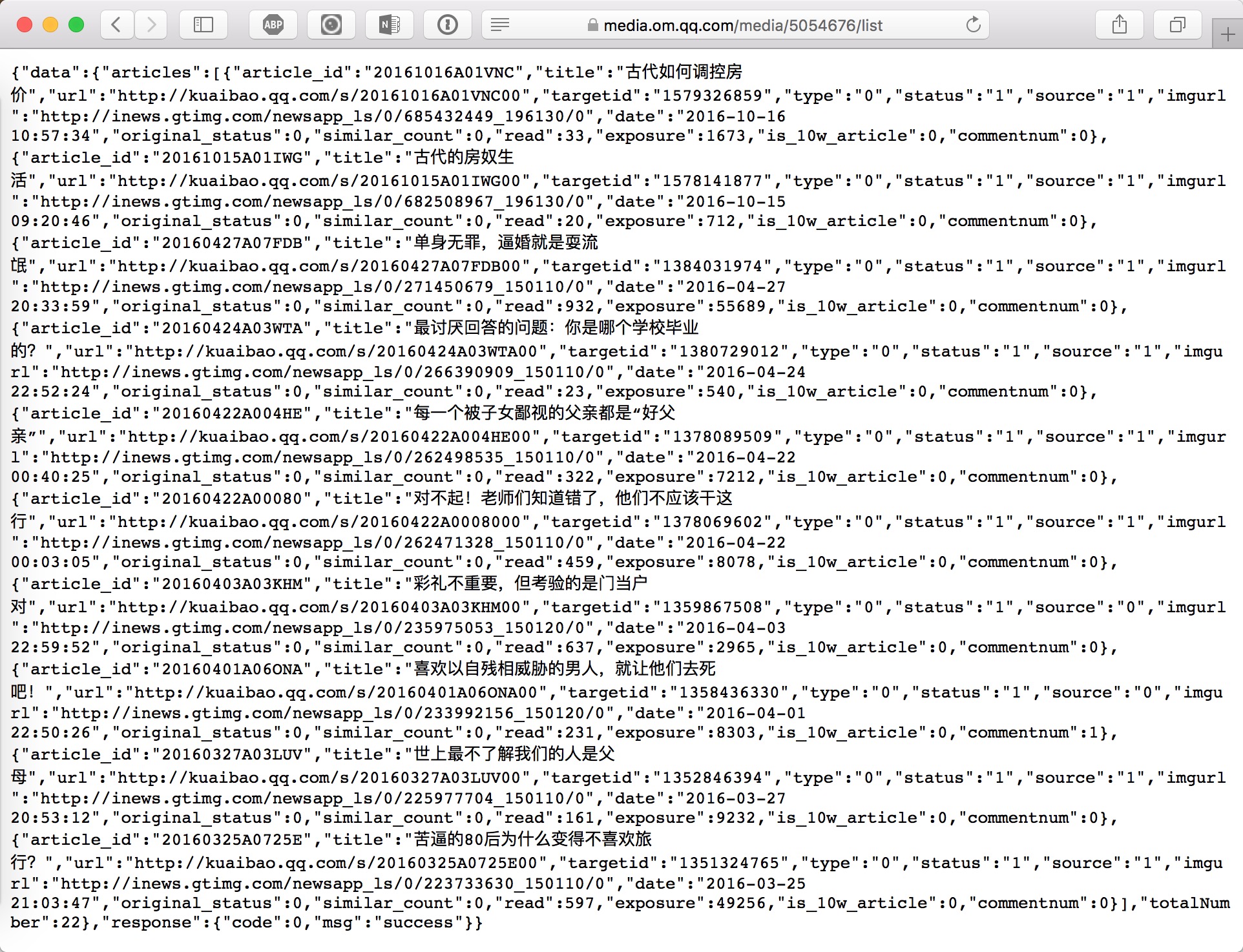
图: safafi_get)omqq
基于Phantomjs的动态爬虫
至此,我们就可以根据前面的分析使用Phantomjs来逐步模拟人工请求,从而绕过反爬虫系统。先看代码:
/**************************************************************** * phjs_antispider.js * anti-anti-spider script for https://media.om.qq.com/media/5054676/list * auther : Taerg * date : 12/05/2017 *****************************************************************/ var page = require("webpage").create(); var system = require("system") url = system.args[1]; headers = {}; page.customHeaders = headers; page.settings = { javascriptEnabled: true, userAgent: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36‘, }; page.viewportSize = { width: 1024, height: 768 }; page.open(url, function(status) { page.injectJs(‘jquery321.js‘); if (status !== ‘success‘) { console.log(‘Unable to access network‘); } else { page.evaluate(function() { var allElements = $(‘*‘); for ( var i = 0; i<allElements.length; i++ ) { if (allElements[i].href) { javascript_code = allElements[i].href.match("javascript:(.+)"); if (javascript_code){ console.log(javascript_code[0]); eval(javascript_code[0]); } } } }); } window.setTimeout( function() { console.log("crawl_content:"+page.content+"content_end") phantom.exit() }, 1000 ); phantom.exit(); });
在上述代码中:
- 我们先修改page.settings,设置请用JavaScript,
- 同时自定义user-agent,伪造浏览器,
- 设置分辨率,进一步伪造人工浏览,
- 打开页面时引入jQuery文件,
- 使用jQuery的选择器选出页面中的所有元素,
- 如果元素中存在JavaScript脚本,则运行这些脚本,
- 设置页面超时时间,并打印出页面内容。
运行结果如下:可见,我们的请求已经绕过了反爬虫机制。
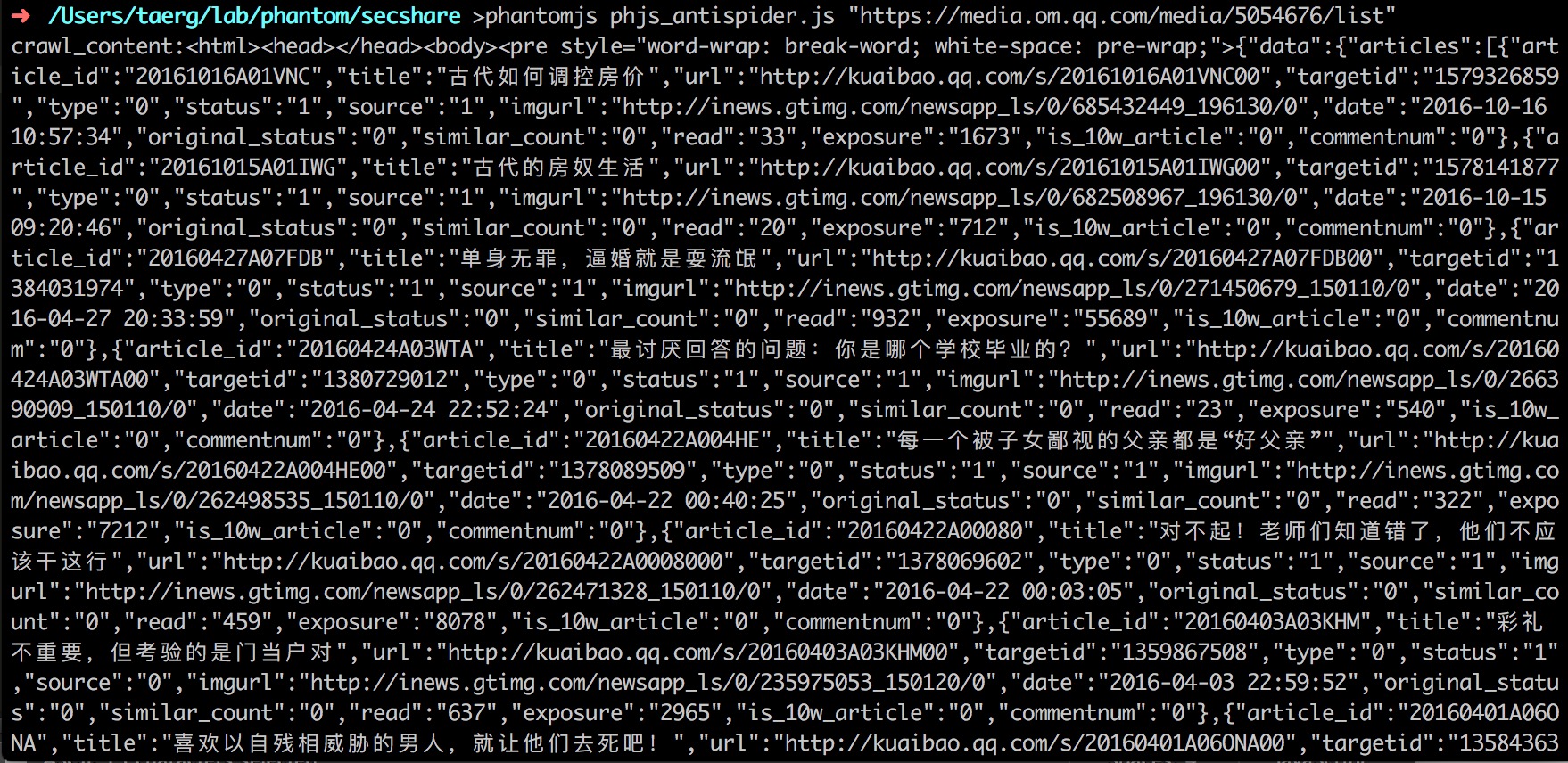
图: phantomjs_get_omqq
3行代码爬取:基于Casperjs的类人动态爬虫
卧槽,我就是个开发,你跟我说抓包分析啥的我不会啊!!宝宝只想爬点数据而已啊…
那就用三行代码来实现吧:
- 第一行创建一个casper实例
- 第二行发起请求
- 第三行执行并退出
/**************************************************************** * crawl the anti-aipder website: om.qq.com * auther : Taerg * date : 17/05/2017 *****************************************************************/ var casper = require("casper").create(); casper.start(‘https://media.om.qq.com/media/5054676/list‘, function() { require(‘utils‘).dump(JSON.parse(this.getPageContent())); }); casper.run(function() { this.exit(); });
结果如下:
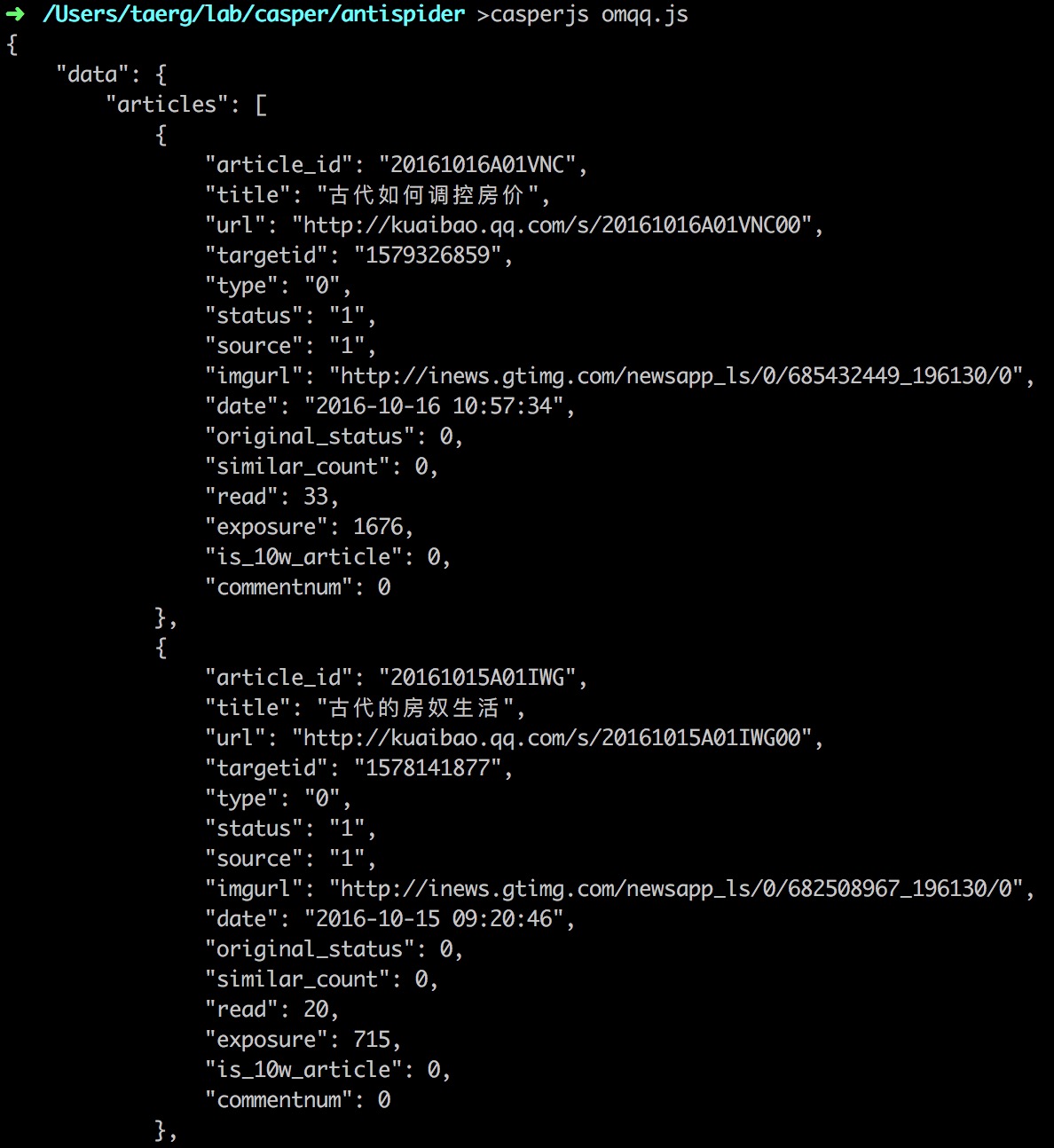
图:casper_get_omqq
这三行代码不仅成功绕过了反爬虫的限制,而且自带的JSON方法也将也数据结构化显示(存储),对于复杂爬虫的开发可以极大的简化开发复杂度。
这三行代码中用到的就是—CasperJS。
CasperJS官方自称是一个开源的导航脚本和测试工具,但实际用起来爽的不行不行的。具体包括:
- defining & ordering navigation steps
* filling forms - clicking links
- capturing screenshots of a page (or an area)
- making assertions on remote DOM
- logging & events
- downloading resources, even binary ones
- catching errors and react accordingly
- writing functional test suites, exporting results as JUnit XML (xUnit)
此外,CasperJS最为强大的地方在于我在这里给大家简单介绍之后,我就不用再说什么了,CasperJS拥有极其丰富的文档及实例代码。这一点对比核心文档还是TODO,需要我们来撰写各类文档的Phantomjs来说友好太多了。
最后,鉴于CasperJS拥有的丰富的文档,我也就不再班门弄斧了,本文就此打住。下次和大家分享讨论基于Phantomjs的XSS检测工具。
相关阅读
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://cloud.tencent.com/community/article/636391
以上是关于反-反爬虫:用几行代码写出和人类一样的动态爬虫的主要内容,如果未能解决你的问题,请参考以下文章
动态ip代理:反网络爬虫之设置User-Agent的常规方法