个人第二次作业
Posted 摇滚帝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了个人第二次作业相关的知识,希望对你有一定的参考价值。
0前言
本次作业要求做一个词频统计的软件,功能简单来说是实现英文文章的单词总数,以及每个单词出现次数的统计。
编程语言语言:C++
工具:CodeBlocks
git地址:https://git.coding.net/Vrocker/wf.git
一、主要功能
0.简述:
题目要求总共为四部分,通过对这四部分功能需求的研究,可以将主要功能细分成以下部分:
1.可以读入本地txt格式的文件,要求内容是英文书籍或者文章。
2.统计文件中不重复出现单词的总数,并输出。
3.统计文件中英文单词的词频,即出现的单词以及这个单词出现的次数,并且降序输出。
4.要求在命令提示符中直接控制程序,即输入相应参数实现相应的功能。
5.支持单一文件,同时支持指定文件夹下的所有文件中英文单词的词频统计。
6.在多文件统计时只输出出现次数最多的十个单词。
二、设计思路
要实现题目要求的功能,我首先想到的是用数组或者链表来进行操作:
首先读入输入的文本文件,将文本文件的各个字符包括标点符号等逐一放进数组中。然后设置一个指针从头开始进行遍历,一旦遇到标点或者空格的时候(我认为“-”连接的两个或多个英文单词应该算作一个单词,所以“-”不用排除掉)就可以分割单词,将这个单词保存到另外一个数组中。然后再设置另外一个指针,对新数组进行遍历,统计每个单词出现的次数,以及这个单词本身。最后利用排序算法,例如冒泡排序,进行降序排序。这样就可以大致实现主要的功能。
但我在查阅资料的时候,我看到一篇博客名为”【tips】【词频统计】中可能用到的资源,以C++为例“的博客,网址是:http://www.cnblogs.com/Z-XML/p/3329234.html(真的很感谢这位作者)。看完这篇博客我了解到在C++中有一个MAP容器,可以更好更简单,而且更快的完成想要的功能。因为之前接触C++的时候,并不了解map容器,所以便开始了学习的过程。同时在这篇博客中我了解到利用vector以及自带的sort函数可以排序数组。这样就大大减少了工作量。但是由于之前我也没接触过这些,所以也要开始学习这些对我来说新的概念和方法。所以我放弃了最开始选择的设计思路,改用这个来设计我的程序。
三、难点
1.参数
功能要求通过命令提示符输入相应的参数可以直接进行操作。这样的设计方法,之前我并不了解。所以开始查询资料,找解决方案。因为选择了C++进行编程,所以也开始看相关的C++书籍。这个功能花费了我相当多的时间来解决。首先的难题是不知道怎么可以获取到这些参数,同时也不清楚怎么样对参数进行判断,以便进行不同的操作。
在学习之后,知道了C++中可以用int main(int argc, char* argv[])定义主函数,从而直接实现参数的功能。部分代码如下:
1 for(int i=1; i<argc; i++)//用于接受从命令提示符传递进来的参数 2 { 3 str = argv[i]; 4 if(str=="-s")//如果从命令提示符传递的第一个参数是“-s”执行以下操作 5 { 6 char const *a = "g:\\\\"; 7 char const *b = argv[i+1]; 8 std::string const& cc = std::string(a) + std::string(b); 9 char const *c = cc.c_str();//将两个char进行拼接,以便传入fin.open函数中 10 fin.open(c); 11 break;//跳出判断 12 } 13 else if(str=="floder")//如果从命令提示符传递的第一个参数是floder执行以下操作 14 { 15 system("dir /b /a-d G:\\\\floder\\\\*.* >d:\\\\allfiles.txt");//读取指定文件夹下的所有txt文件 16 for(int j=2; j<argc; j++)//将所有的txt文件写入流文件 17 { 18 ............//此功能未能实现 19 } 20 } 21 else//当传递的第一个参数是txt文件的文件名时 22 { 23 char const *a = "g:\\\\"; 24 char const *b = argv[i]; 25 char const *d = ".txt"; 26 std::string const& cc = std::string(a) + std::string(b) + std::string(d); 27 char const *c = cc.c_str(); 28 fin.open(c); 29 } 30 }
2.拼接char*
要求的功能中,要实现在命令提示符输入wf和书名来实现词频统计。而在我设计的程序中,要用到被统计文件的实际地址。例如"c:\\\\a.txt"。但是文件的名字又是不确定的所以我在这里要用到拼接char*来实现。在查询大量资料后,发现可以实现。代码如下:
1 if(str=="-s")//如果从命令提示符传递的第一个参数是“-s”执行以下操作 2 { 3 char const *a = "g:\\\\"; 4 char const *b = argv[i+1]; 5 std::string const& cc = std::string(a) + std::string(b); 6 char const *c = cc.c_str();//将两个char进行拼接,以便传入fin.open函数中 7 fin.open(c); 8 break;//跳出判断 9 }
3.去除标点
要实现统计词频的功能,标点就一定会影响统计。所以要除去标点,才能正确的统计单词,并且最后完整正确的输出。为此定义了一个函数,来实现这个功能。代码如下:
1 void StringToLower(string &theString)//将字符串转化成全小写 2 { 3 int nLen = theString.length(); 4 for(int i = 0; i < nLen; i++) 5 { 6 theString[i] = tolower(theString[i]); 7 } 8 }
并且在输入文本之后,调用这个函数,将不相关的符号排除。代码如下:
1 set<char> ignoreSet;//除去标点符号或者会影响判断单词等符号 2 ignoreSet.insert(\',\'); 3 ignoreSet.insert(\'.\'); 4 ignoreSet.insert(\'?\'); 5 ignoreSet.insert(\':\'); 6 ignoreSet.insert(\'!\'); 7 ignoreSet.insert(\';\'); 8 ignoreSet.insert(\'\\\'\'); 9 ignoreSet.insert(\'"\');
4.转换大小写
我在第一次测试程序的时候,发现自己犯了一个错误。就是大小写没有转换,导致同样的单词只是大小写不一样,会有两个结果。这显然不符合题目的要求。所以为了让大小写统一,这里把统计到的所有单词都转化成小写字母。这样就不会有问题。代码如下:
1 void StringToLower(string &theString)//将字符串转化成全小写 2 { 3 int nLen = theString.length(); 4 for(int i = 0; i < nLen; i++) 5 { 6 theString[i] = tolower(theString[i]); 7 } 8 }
5.排序输出
最后要对统计过的单词以及出现的次数,以次数为标准降序排列输出。这里就用到了排序的函数。最开始,我想用冒泡排序或者其他相应的算法进行。但是在了解C++中各种排序的方法之后。我了解到C++自带一个sort函数可以用于排序。所以在这里我选择这个方法。在看了一些用map容器最后进行排序的相关代码之后,我发现这些代码最后大部分都是把map转化成vector之后再进行排序。但是对于这个知识点我之前也是没有接触过。所以再进行学习之后,模仿同样方法的排序代码尝试进行自己编写。代码如下:
1 struct CmpByValue 2 { 3 bool operator()(const PAIR& lhs, const PAIR& rhs) 4 { 5 return lhs.second > rhs.second; 6 } 7 }; 8 .................. 9 vector<PAIR> wmap_vec(wmap.begin(), wmap.end()); 10 sort(wmap_vec.begin(), wmap_vec.end(), CmpByValue());
利用wmap_vec.size()可以直接输出总数。
这时候每个单词存放在对应的wmap_vec[i].first 中。而出现的次数存放在对应的wmap_vec[i].second中。再用一个for循环就可以输出。
1 float sum=0; 2 for (int i = 0; i != wmap_vec.size(); ++i)//利用map输出总字数 3 { 4 sum=sum+1; 5 } 6 cout<<"total "<<sum<<" words"<<endl<<endl<<endl; 7 for (int i = 0; i != wmap_vec.size(); ++i)//利用map输出每个单词以及其出现次数 8 { 9 cout << left << setw(50) << wmap_vec[i].first << wmap_vec[i].second << endl; 10 }
四、功能测试
1.

2.
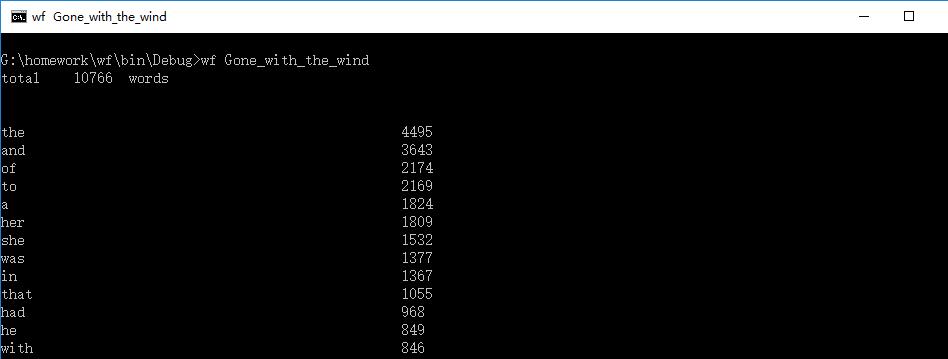
3.
这个部分支持命令行输入存储有英文作品文件的目录名,批量统计。这个功能花费了我很长的时间来做。但是还是没有做好。试了很多方法,但是都没有成功。上述代码有出现str = argv[i];else if(str=="floder");判断参数成功的时候试过设置一个flag,当主函数运行到输出部分的时,如果flag正确则多次输出结果。但是没有成功。
五、总结
刚开始我看到这个题目的时候,第一感觉是挺简单的。逻辑不复杂,而且应该比较容易实现。所以一直没觉得会花费我太多时间。但当我真正开始着手写代码的时候发现,可以用更简单便捷的方法实现。所以我就开始研究这个新的方法。因为觉得代码量并不大,所以又一次估算时间应该没有多久。然而,写着写着我开始发现自己的知识掌握的太不牢固,同时也发现自己想要用的这个方法里面,有太多东西是我之前没有接触过的。但是既然选择了这个方法,况且这个方法看起来确实比较简洁,我就硬着头皮边写边学。
首先map容器和vector之前我并不知道。所以两个知识点我花了相当大的时间来处理。之后参数的相关知识也是一知半解,再查了很多资料之后才开始着手编写,这个环节花费的时间也不少。虽然知识点不多,但是由于没有实际编写过,所以在调试,测试的过程中出现了很多很多的问题。同时,char*的拼装,也是在查阅资料之后在知乎看到一个回答,才让我很好的解决。这些只是花费时间比较多的环节,实际上每个步骤我都花费了相当长的时间。总结来看,预估的时间远远小于我真实花费的时间。
通过这次编写程序,让我最感触的就是预估的时间可能会远远低于花费的时间。一个看上去不难的程序,在编写的过程中也会遇到很多难题。同时,这次编写程序让我开始知道自己掌握的知识点,远远不够,需要不断的学习同时不断地练习才能保证熟练的掌握一门语言。
PSP表格
|
分类 |
预计时间(分钟) |
实际时间(分钟) |
实际总时间(分钟) |
时间差(分钟) |
|
功能一 |
90 |
95 |
155 |
65 |
|
测试1 |
60 |
|||
|
功能二 |
150 |
150 |
240 |
90
|
|
测试2 |
90 |
|||
|
功能三 |
120 |
240 |
330 |
110 |
|
测试3 |
90 |
|||
|
功能四 |
180 |
90 |
150 |
-30 |
|
测试4 |
60 |
|||
|
总体调试 |
60 |
90 |
90 |
30 |
以上是关于个人第二次作业的主要内容,如果未能解决你的问题,请参考以下文章