分布式一致性算法Raft
Posted 小猴子爱吃桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式一致性算法Raft相关的知识,希望对你有一定的参考价值。
什么是分布式一致性?
我们先来看一个例子:
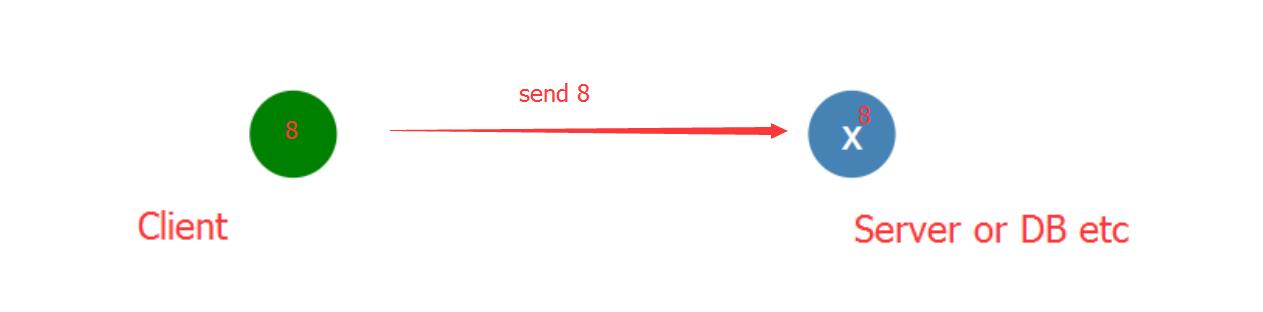
我们有一个单节点node,这个节点可以是数据库,也可以是一台服务器,当client向node发送data时,X节点收到data,记录下来
由此可见对于单个节点,一致性是很容易实现的。
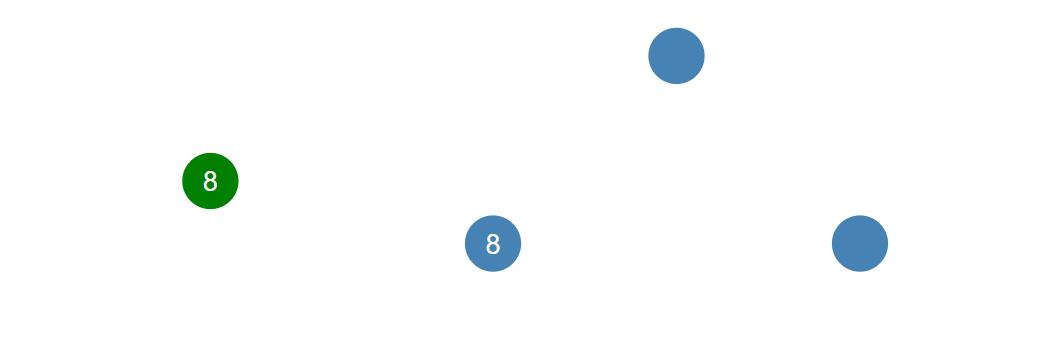
然而对于多个节点,我们如何来实现一致性,这就是分布式一致性的问题。
Raft就是一个实现分布式一致性的协议
下面让我们来看看它是如何工作的?
node介绍:
每一个节点有三种state
(1) follower state
(2) leader state
(3) candidate state
Leader Election
所有的节点都是从follower state开始的,如果一个follower状态的节点没有被某个leader所控制,它就有可能成为候选者。而当一个节点成为候选者时,它就会向其他节点收集选票,而其他节点在收到候选者发出的信号后,就会把选票发给候选者。如果某个候选者获取了大多数选票,则会成为领导者。这个过程就是领导者选举。
整个选举过程是有一个时间限制的,如下图:
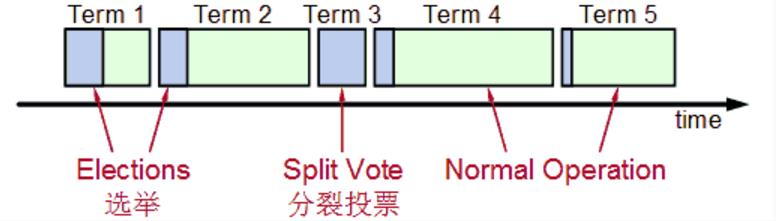
Splite Vote是因为如果同时有两个候选人向大家邀票,这时通过类似加时赛来解决,两个候选者在一段timeout比如300ms互相不服气的等待以后,因为双方得到的票数是一样的,一半对一半,那么在300ms以后,再由这两个候选者发出邀票,这时同时的概率大大降低,那么首先发出邀票的的候选者得到了大多数同意,成为领导者Leader,而另外一个候选者后来发出邀票时,那些Follower选民已经投票给第一个候选者,不能再投票给它,它就成为落选者了,最后这个落选者也成为普通Follower一员了。
Log Replication
选出领导者后,对于这些节点组成的一个系统中的所有变化都会经过这个领导者,由它掌管全局。
领导者收到client发来的消息后,会把每一次的请求操作记录在日志上,在这条日志记录没被提交之前,其他节点的值不会有任何改变。
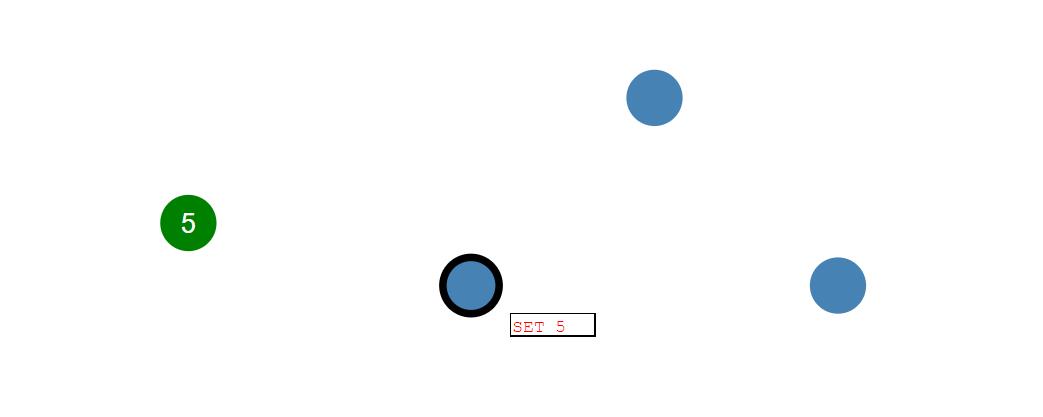
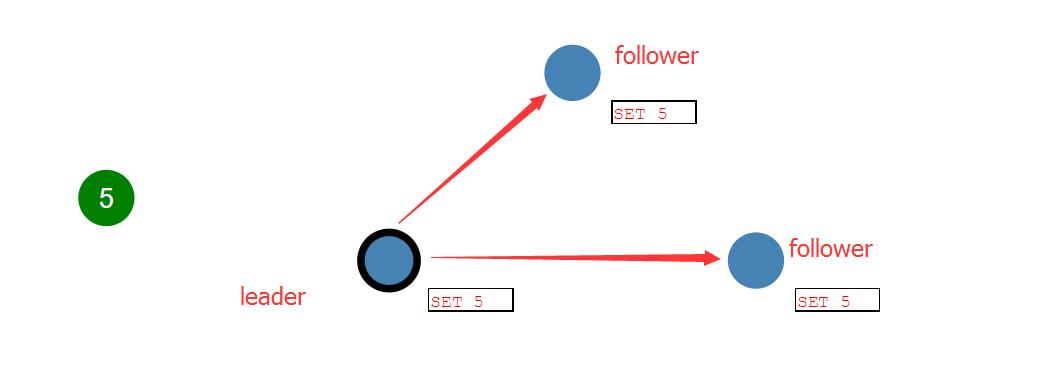
领导者先把日志条目set 5 拷贝到跟随者节点中,当大多数的跟随者节点已经把日志记录追加到本节点的日志时,领导者就开始执行该条日志,即把5写入改节点。然后在下一个heartbeat中,领导者就会通知followers,该日志条目已经提交,follows也会写入5。这时整个集群保持了数据的一致性。这个过程叫做日志复制。
对于每个新的日志记录,重复上述过程。
如果在这一过程中,发生了网络分区或者网络通信故障,使得Leader不能访问大多数Follwers了,那么Leader只能正常更新它能访问的那些Follower服务器,而大多数的服务器Follower因为没有了Leader,他们重新选举一个候选者作为Leader,然后这个Leader作为代表于外界打交道,如果外界要求其添加新的日志,这个新的Leader就按上述步骤通知大多数Followers,如果这时网络故障修复了,那么原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新。
以上是关于分布式一致性算法Raft的主要内容,如果未能解决你的问题,请参考以下文章