第二周作业-词频统计
Posted huyr000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二周作业-词频统计相关的知识,希望对你有一定的参考价值。
本周作业是词频统计,编程具体要求如下:
https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/922
对实现功能进行简要的介绍:
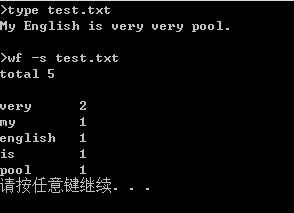
功能一:小文件输入,为表明程序能跑。需要在控制台下输入命令,得到文件中不重复的总单词数。并对单词出现的次数进行排序输出。
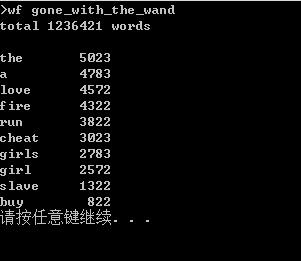
功能二:支持命令行输入英文作品的文件名,亲自录入,输出显示不重复单词总数,并对出现频率最高的前10的单词进行输出
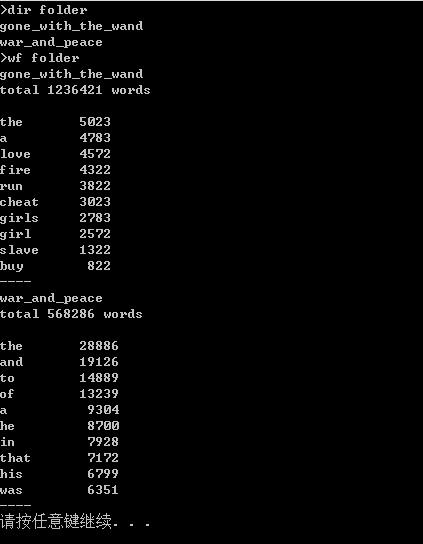
功能三:支持命令行输入存储有英文作品文件的目录名,批量统计词频。
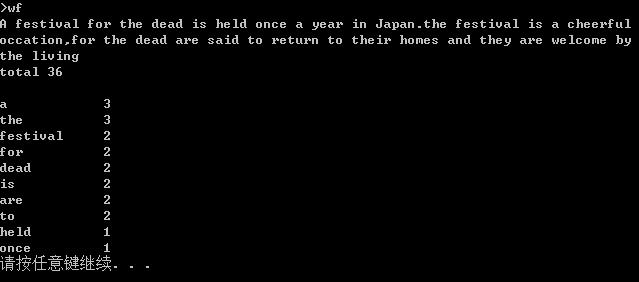
功能四:从控制台读入英文单篇作品,表名你能提供更适合嵌入脚本的作品或者bing:linux重定向。
第二周我的前两篇随笔写得很随意,主要记录了实现词频统计功能一和功能二的遇到的难点和怎么解决的。它们同时也展现出来了我对老师给出题意的不理解,因为实现后,虽然达到目的,但其实有很多小错误,例如我对单词定义的不理解,以及对命令行参数的不理解,还有对输入输出格式的不注意等。
这篇随笔主要讲我的作业完成情况,对实现作业每个功能遇到的重点/难点,以及我感到得意,突破,有困难的地方进行详细讲解。
这篇博客主要分为六个部分:
1.我的编程和学习过程
2.完成过程中遇到的难点
3.重要代码段以及功能完成截图
4.PSP阶段表格
5.代码及版本控制
6.学习总结
一.我的编程和学习过程
周四下课之后,晚上老师便在群里发表了具体的作业要求,看完要求之后,和liusx讨论了一下决定用不熟悉的c#语言实现这个小程序,因为老师说不懂的去学才会有进步。第二天,我上完课便去图书馆借了两本书《c#从入门到精通》,《c#项目实战》,拿到书之后,大概翻阅了一下书的目录,了解各个章节主要讲了什么内容。午休之后,才真正进行看《c#从入门到精通》这本书,看书的过程是痛苦的,因为发现本科选修课学的c#全交还给老师了,果然编程语言是要多实践才能有所进步,不学习就会变成白痴。无奈只能硬着头皮重新再学了,我唯一有点印象的章节就是窗口应用程序这块,基于UI的设计。
写代码之前,首先需要开发环境,由于电脑上没有visual studio 的安装包,当时求助了度娘。如果有需要vs安装包的同学可以借鉴一下这个链接http://blog.csdn.net/chunleixiahe/article/details/52874158,里面vs2003-2015的版本都有,推荐。由于网速问题,我下载安装包都花费了半个小时。
看到题目,我基于对窗口设计的熟悉,就直接用Windows窗口程序完成了文件的查找,读取和统计字数,然后询问老师是否可以Windows窗口程序完成,发现这次作业后续功能需要重定向输入,必须得做成控制台,否则无法做重定向输入,所以放弃了窗口程序。然后开始老老实实看书,一步步自行学习c#,主要学习的章节是输入输出格式,对文件的处理,泛型,多线程等章节。
二.完成作业遇到的难点
实现功能一遇到的困难
1.读入整本英文小说内容有困难
2.对整个英文小说进行单词总数统计遇见困难。
3.字符串数组的空字符串处理问题。因为我开始用空格来代替标点等不是英文单词来进行对单词分割,其中用到了正则表达式,后来统计对单词出现频数时,发现空格竟然排第一名,有4万多空格。
实现功能三遇到的困难
1.文件夹的读取以及遍历文件夹下面的文档输出有困难
2.经常会报地址不合法不存在,会报异常
实现功能四遇到的困难
1.没理解题意
2.对四个功能整合在一个文件进行命令行操作遇见困难
版本控制,用Git遇到的困难
1.不会使用git
2.不会版本控制
三.重要代码段和功能完成截图
下面给出的代码实现的功能是词频统计,主要的操作有读取文本内容,并对文本的单词进行处理,使用了正则表达式处理非单词字符,且使用隶属于泛型集合的ForEach方法循环获取非空空字符串,来对空字符串进行处理,词频统计主要使用了哈希表,用自带的函数对哈希表的值进行排序,然后进行输出。
public void countT(string theName) { string[] fs = Directory.GetFiles(theName); string rline = null; foreach (string file in fs) { rline = ReadFile(theName); rline = rline.ToLower(); //使用正则表达式 //Regex regex = new Regex(@"\\b[A-Za-z]+[A-Za-z0-9]*"); rline = Regex.Replace(rline, @"[^a-zA-Z0-9\\u4e00-\\u9fa5\\s]", " "); rline = Regex.Replace(rline, "[!@#$%^&*()`,./;\':\\"<>`?...]", " "); string[] S = rline.Split(\' \'); //使用List泛型集合的ForEach方法循环获取非空空字符串 //这里使用了匿名方法 List<string> list = new List<string>(); S.ToList().ForEach( (s) => { if (!string.IsNullOrEmpty(s)) { list.Add(s); } } ); S = list.ToArray(); Hashtable ha = new Hashtable();//建立一个哈希表 for (int i = 0; i < S.Length; i++) { if (ha.ContainsKey(S[i])) { ha[S[i]] = (int)ha[S[i]] + 1; } else { ha.Add(S[i], 1); } } string[] arrKey = new string[ha.Count];//存哈希表的键 int[] arrValue = new int[ha.Count];//存哈希表的值 ha.Keys.CopyTo(arrKey, 0); ha.Values.CopyTo(arrValue, 0); Array.Sort(arrValue, arrKey);//按哈希表的值进行排序 Console.WriteLine("total " + arrKey.Length + " words"); Console.WriteLine(); wf.Program p = new wf.Program(); p.ShowArr2(arrKey, arrValue); } }
四.PSP阶段表格
PSP阶段表格如下:
| PSP阶段 | 预计花费时间 | 实际花费时间 | 时间差距和原因分析 |
| 功能一 | 60min | 118min |
时间差距58min,主要是因为对c#语言的文件操作不熟悉字符统计 开始没想到用哈希表来处理
|
| 文件的查找,读取 | 20min | 30min | |
| 字符统计 | 30min | 60min | |
| 命令行参数读入处理 | 10min | 8min | |
| 代码调试 | 10min | 20min | |
| 功能二 | 55min | 65min |
时间差距10min,主要在使用正则表达式和对空字符串处理优化耗费了较长时间 |
| 读取小说的内容 | 15min | 10min | |
| 字符统计 | 20min | 10min | |
| 测试 | 10min | 5min | |
| 改进优化 | 20min | 40min | |
| 功能三 | 40min | 88min |
时间差距48min,原因主要是对前两个功能修改完之后出现了bug,不断修正调试,还有版本控制这块使用了较长时间。 |
| 遍历文件夹 | 10min | 7min | |
| 在前两个功能进行修改 | 10min | 15min | |
| 测试 | 5min | 20min | |
| 版本控制 | 15min | 46min | |
| 功能四 | 60min | 98min |
时间差距38min,原因主要在对题意没理解,例重定向输入,花费了较长时间。 |
| 需求分析 | 10min | 44min | |
| 代码规范 | 5min | 6min | |
| 代码复查 | 20min | 10min | |
| 测试 | 10min | 20min | |
| 版本控制 | 15min | 18min |
五.代码及版本控制
git地址:https://coding.net/u/huyr000/p/countWord/git
六.学习总结
通过做字符统计这个小程序,大致熟悉了c#语言对文件的操作,并且自己能够独立动手完成这四个功能,还是很开心的,四个功能大同小异,最后把四个功能整合在一个命名空间里进行操作,虽然实现的过程中,遇到了很多困难,但当把bug解决掉的那刻是开心且得意的。还有最大的收获是学会了git的使用,在多次使用命令行都无法pull,最后是郑蕊师姐手把手教我和刘淑霞还有彩虹使用git,在此特别感谢。
以上是关于第二周作业-词频统计的主要内容,如果未能解决你的问题,请参考以下文章