Hive之 hive架构
Posted 张冲andy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive之 hive架构相关的知识,希望对你有一定的参考价值。
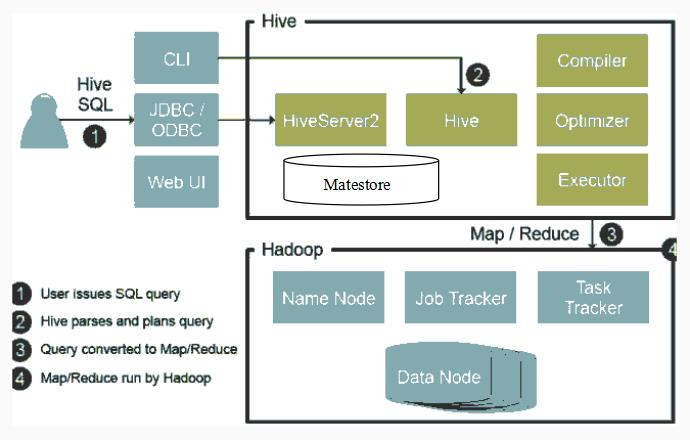
Hive架构图
主要分为以下几个部分:
- 用户接口,包括 命令行CLI,Client,Web界面WUI,JDBC/ODBC接口等
- 中间件:包括thrift接口和JDBC/ODBC的服务端,用于整合Hive和其他程序。
- 元数据metadata存储,通常是存储在关系数据库如 mysql, derby 中的系统参数
- 底层驱动:包括HiveQL解释器、编译器、优化器、执行器(引擎)。
- Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算。
- 用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
- Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译生成执行计划、优化以及生成最佳执行计划。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from tbl 不会生成 MapRedcue 任务)。
以上是关于Hive之 hive架构的主要内容,如果未能解决你的问题,请参考以下文章