spark 算子分析
Posted LazyJoJo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark 算子分析相关的知识,希望对你有一定的参考价值。
别的不说先上官网:
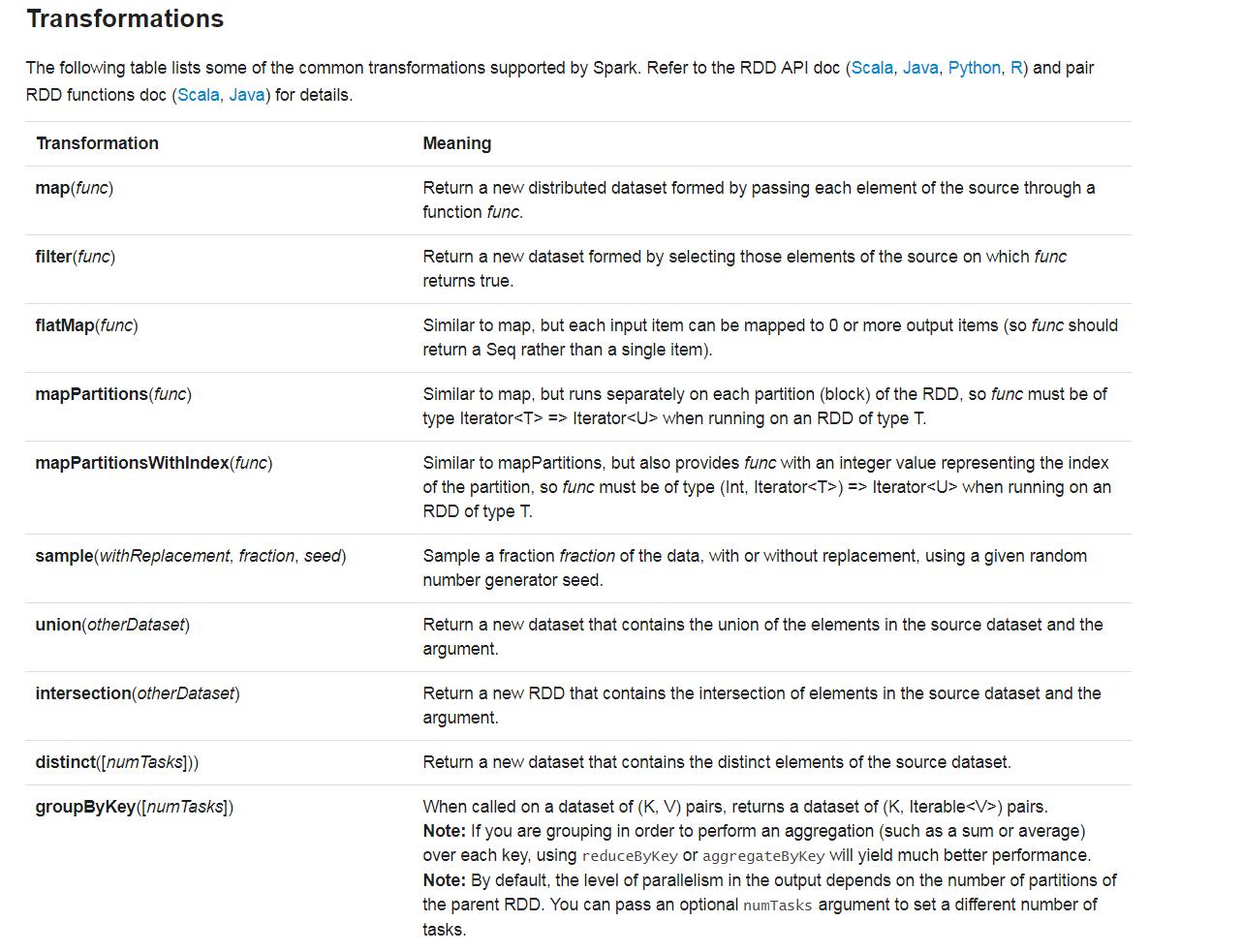
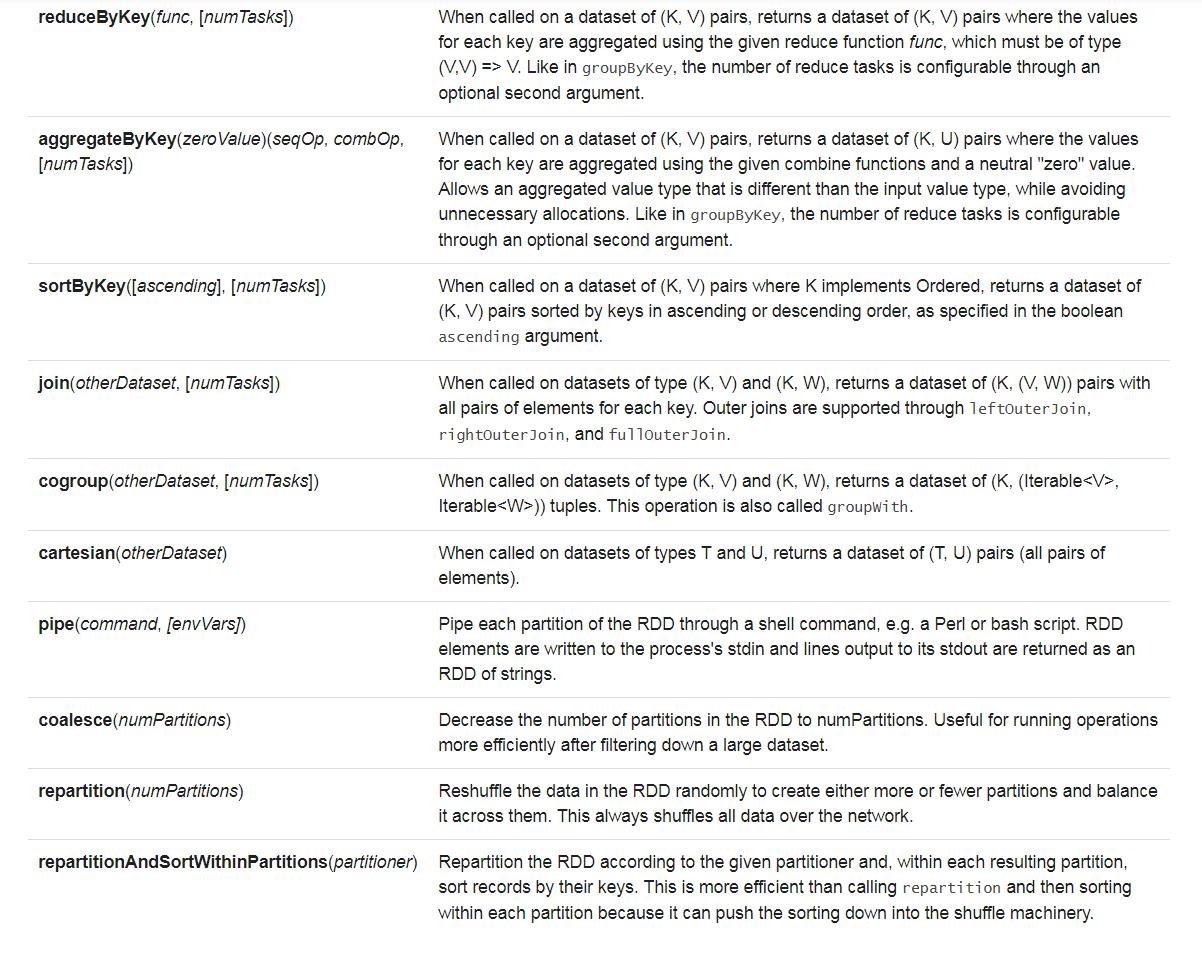
action
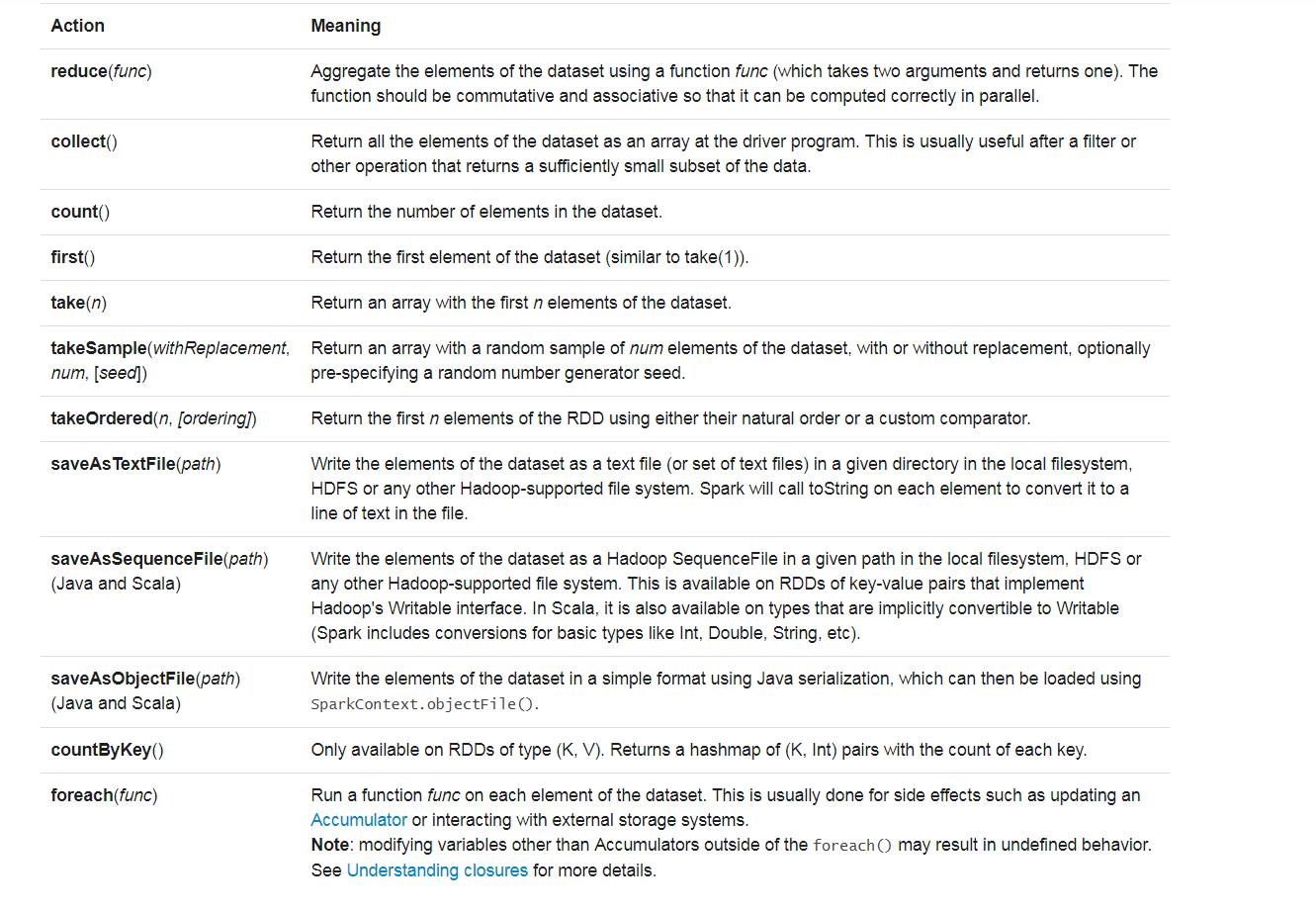
这些算子中需要注意:
1、reduce 和 reduceByKey 虽说都有reduce,但是一个是action级别,一个是transformation级别,速度上会有很大的差异
2、groupBy的使用如下
groupBy :将元素通过函数生成相应的 Key,数据就转化为 Key-Value 格式,之后将 Key 相同的元素分为一组。
val a = sc.parallelize(1 to 9, 3)
a.groupBy(x => { if (x % 2 == 0) "even" else "odd" }).collect //分成两组
/*结果 Array( (even,ArrayBuffer(2, 4, 6, 8)), (odd,ArrayBuffer(1, 3, 5, 7, 9)) ) */
groupBy 实际上就是提供一个function,里面是一个if..else..表达式,这个表达式的值就是最后group出来的key的值
图1 中方框代表一个 RDD 分区,相同key 的元素合并到一个组。例如 V1 和 V2 合并为 V, Value 为 V1,V2。形成 V,Seq(V1,V2)。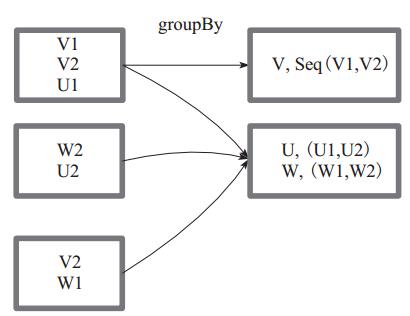
图 1 groupBy 算子对 RDD 转换
3、cartesian的使用
对 两 个 RDD 内 的 所 有 元 素 进 行 笛 卡 尔 积 操 作。 操 作 后, 内 部 实 现 返 回CartesianRDD。图6中左侧大方框代表两个 RDD,大方框内的小方框代表 RDD 的分区。右侧大方框代表合并后的 RDD,大方框内的小方框代表分区。图6中的大方框代表 RDD,大方框中的小方框代表RDD分区。
例 如: V1 和 另 一 个 RDD 中 的 W1、 W2、 Q5 进 行 笛 卡 尔 积 运 算 形 成 (V1,W1)、(V1,W2)、 (V1,Q5)。
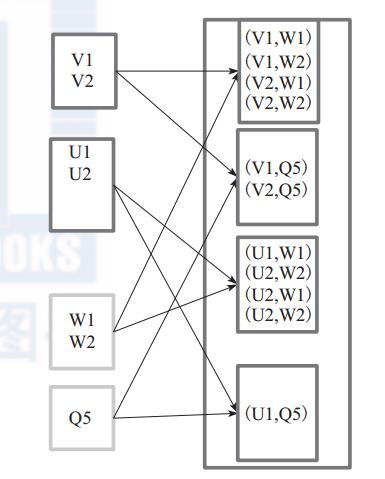
图 2 cartesian 算子对 RDD 转换
4、sample的使用
sample 将 RDD 这个集合内的元素进行采样,获取所有元素的子集。用户可以设定是否有放回的抽样、百分比、随机种子,进而决定采样方式。内部实现是生成 SampledRDD(withReplacement, fraction, seed)。
函数参数设置:
withReplacement=true,表示有放回的抽样。
withReplacement=false,表示无放回的抽样。
图 3中 的 每 个 方 框 是 一 个 RDD 分 区。 通 过 sample 函 数, 采 样 50% 的 数 据。V1、 V2、 U1、 U2、U3、U4 采样出数据 V1 和 U1、 U2 形成新的 RDD。
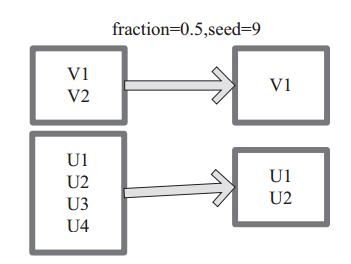
图3 sample 算子对 RDD 转换
5、takesample的使用
takeSample()函数和上面的sample函数是一个原理,但是不使用相对比例采样,而是按设定的采样个数进行采样,同时返回结果不再是RDD,而是相当于对采样后的数据进行
Collect(),返回结果的集合为单机的数组。
图4中左侧的方框代表分布式的各个节点上的分区,右侧方框代表单机上返回的结果数组。 通过takeSample对数据采样,设置为采样一份数据,返回结果为V1。
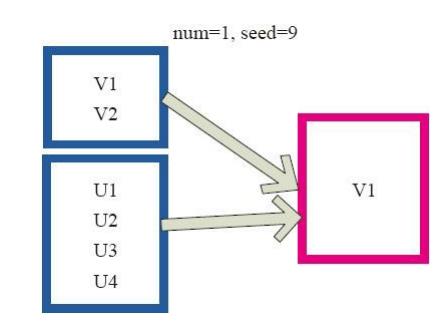
图4 takeSample算子对RDD转换
6、persist的使用 (常用的其实还是cache)
persist 函数对 RDD 进行缓存操作。数据缓存在哪里依据 StorageLevel 这个枚举类型进行确定。 有以下几种类型的组合(见10), DISK 代表磁盘,MEMORY 代表内存, SER 代表数据是否进行序列化存储。
下面为函数定义, StorageLevel 是枚举类型,代表存储模式,用户可以通过图 14-1 按需进行选择。
persist(newLevel:StorageLevel)
图 5-1 中列出persist 函数可以进行缓存的模式。例如,MEMORY_AND_DISK_SER 代表数据可以存储在内存和磁盘,并且以序列化的方式存储,其他同理。
图 5-1 persist 算子对 RDD 转换
图 5-2 中方框代表 RDD 分区。 disk 代表存储在磁盘, mem 代表存储在内存。数据最初全部存储在磁盘,通过 persist(MEMORY_AND_DISK) 将数据缓存到内存,但是有的分区无法容纳在内存,将含有 V1、 V2、 V3 的RDD存储到磁盘,将含有U1,U2的RDD仍旧存储在内存。
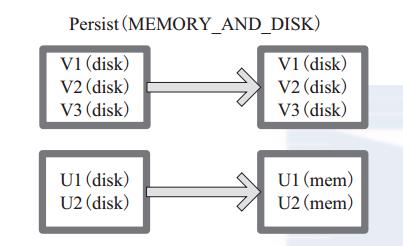
图 5-2 Persist 算子对 RDD 转换
7、mapValue的使用
mapValues :针对(Key, Value)型数据中的 Value 进行 Map 操作,而不对 Key 进行处理。
图 6 中的方框代表 RDD 分区。 a=>a+2 代表对 (V1,1) 这样的 Key Value 数据对,数据只对 Value 中的 1 进行加 2 操作,返回结果为 3。
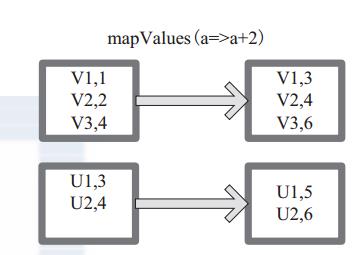
图 6 mapValues 算子 RDD 对转换
8、coGroup的使用
cogroup函数将两个RDD进行协同划分,cogroup函数的定义如下。
cogroup[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (Iterable[V], Iterable[W]))]
对在两个RDD中的Key-Value类型的元素,每个RDD相同Key的元素分别聚合为一个集合,并且返回两个RDD中对应Key的元素集合的迭代器。
(K, (Iterable[V], Iterable[W]))
其中,Key和Value,Value是两个RDD下相同Key的两个数据集合的迭代器所构成的元组。
图19中的大方框代表RDD,大方框内的小方框代表RDD中的分区。 将RDD1中的数据(U1,1)、 (U1,2)和RDD2中的数据(U1,2)合并为(U1,((1,2),(2)))。
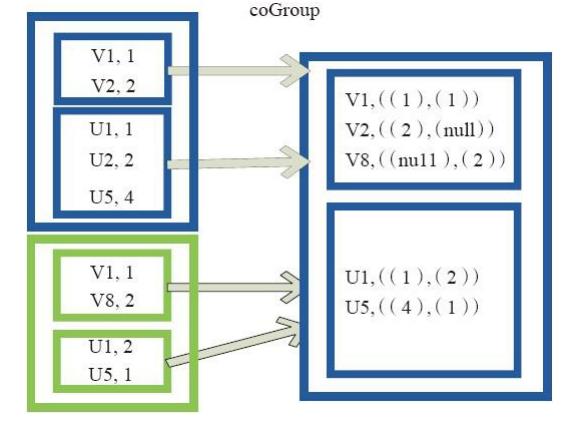
图7 Cogroup算子对RDD转换
9、join的使用
join 对两个需要连接的 RDD 进行 cogroup函数操作,将相同 key 的数据能够放到一个分区,在 cogroup 操作之后形成的新 RDD 对每个key 下的元素进行笛卡尔积的操作,返回的结果再展平,对应 key 下的所有元组形成一个集合。最后返回 RDD[(K, (V, W))]。
下 面 代 码 为 join 的 函 数 实 现, 本 质 是通 过 cogroup 算 子 先 进 行 协 同 划 分, 再 通 过flatMapValues 将合并的数据打散。
this.cogroup(other,partitioner).f latMapValues{case(vs,ws) => for(v<-vs;w<-ws)yield(v,w) }
图 8是对两个 RDD 的 join 操作示意图。大方框代表 RDD,小方框代表 RDD 中的分区。函数对相同 key 的元素,如 V1 为 key 做连接后结果为 (V1,(1,1)) 和 (V1,(1,2))。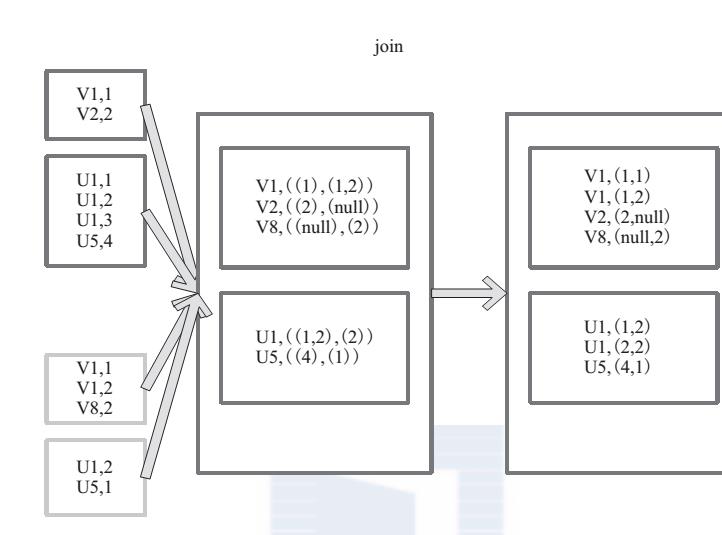
图 8 join 算子对 RDD 转换
以上是比较难的transformation算子的解析,之后是Action算子中易错算子的解析
1、saveAsTextFile 注意这个是默认写入hdfs中,不能写到本地目录的
下面为 saveAsTextFile 函数的内部实现,其内部
通过调用 saveAsHadoopFile 进行实现:
this.map(x => (NullWritable.get(), new Text(x.toString))).saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path)
将 RDD 中的每个元素映射转变为 (null, x.toString),然后再将其写入 HDFS。
图 9中左侧方框代表 RDD 分区,右侧方框代表 HDFS 的 Block。通过函数将RDD 的每个分区存储为 HDFS 中的一个 Block。
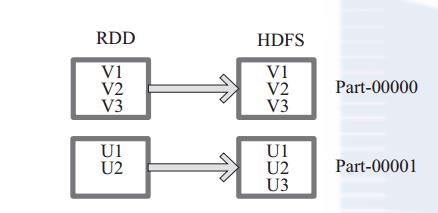
图 9 saveAsHadoopFile 算子对 RDD 转换
2、reduce的使用
reduce函数相当于对RDD中的元素进行reduceLeft函数的操作。 函数实现如下。
Some(iter.reduceLeft(cleanF))
reduceLeft先对两个元素<K,V>进行reduce函数操作,然后将结果和迭代器取出的下一个元素<k,V>进行reduce函数操作,直到迭代器遍历完所有元素,得到最后结果。在RDD中,先对每个分区中的所有元素<K,V>的集合分别进行reduceLeft。 每个分区形成的结果相当于一个元素<K,V>,再对这个结果集合进行reduceleft操作。
例如:用户自定义函数如下。
f:(A,B)=>(A._1+"@"+B._1,A._2+B._2)
图10中的方框代表一个RDD分区,通过用户自定函数f将数据进行reduce运算。 示例
最后的返回结果为V1@[1]V2U!@U2@U3@U4,12。
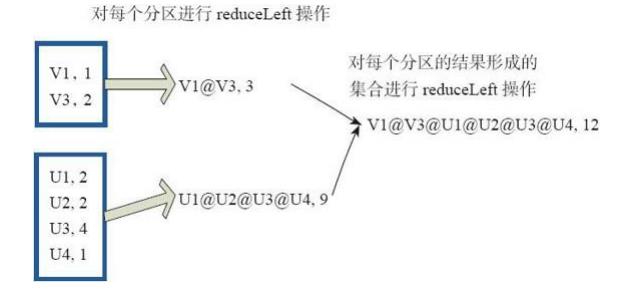
图10 reduce算子对RDD转换
其余算子的使用参见:http://www.cnblogs.com/zlslch/p/5723857.html
以上是关于spark 算子分析的主要内容,如果未能解决你的问题,请参考以下文章