用500行Julia代码开始深度学习之旅 Beginning deep learning with 500 lines of Julia
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用500行Julia代码开始深度学习之旅 Beginning deep learning with 500 lines of Julia相关的知识,希望对你有一定的参考价值。
Click here for a newer version (Knet7) of this tutorial. The code used in this version (KUnet) has been deprecated.
There are a number of deep learning packages out there. However most sacrifice readability for efficiency. This has two disadvantages: (1) It is difficult for a beginner student to understand what the code is doing, which is a shame because sometimes the code can be a lot simpler than the underlying math. (2) Every other day new ideas come out for optimization, regularization, etc. If the package used already has the trick implemented, great. But if not, it is difficult for a researcher to test the new idea using impenetrable code with a steep learning curve. So I started writing KUnet.jl which currently implements backprop with basic units like relu, standard loss functions like softmax, dropout for generalization, L1-L2 regularization, and optimization using SGD, momentum, ADAGRAD, Nesterov‘s accelerated gradient etc. in less than 500 lines of Julia code. Its speed is competitive with the fastest GPU packages (here is a benchmark). For installation and usage information, please refer to the GitHub repo. The remainder of this post will present (a slightly cleaned up version of) the code as a beginner‘s neural network tutorial (modeled afterHonnibal‘s excellent parsing example).
Contents
Layers and nets
The layer function
Prediction
Loss functions
Backpropagation Training
Activation functions
Preprocessing functions
Why Julia?
Future work
Layers and nets
A feed forward neural network consists of layers.
typealias Net Array{Layer,1}
Each layer represents a function which takes an input vector (or a matrix whose columns are input vectors) x, and outputs another vector (or matrix) y. The layer function is determined by a weight matrix w, and optionally a bias vector b, a preprocessing function fx (e.g.dropout), and an activation function f (e.g. sigmoid or relu).
type Layer w; b; f; fx; ... end
The layer function (forw)
Given its parameters and functions, here is how a layer computes its output from its input:
function forw(l::Layer, x)
l.x = l.fx(l, x) # preprocess the input
l.y = l.w * l.x # multiply with weight matrix
l.y = l.y .+ l.b # add the bias vector (to every column)
l.y = l.f(l,l.y) # apply the activation fn to the output
end
I hope that the code is self-explanatory. A couple of things to note: the layer has fields l.x, l.y to remember its last input and output, these will come in handy when calculating gradients. The ".+" operation is the "broadcasting" version of "+", which means if l.y is a matrix, then the vector l.b will be added to each of its columns. Finally Julia automatically returns the value of the last expression in a function, so there is no need for an explicit return statement. The version in the actual source, net.jl, is a bit uglier because (1) it tries to make each operation (except multiplying with the weight matrix) optional, and (2) it uses macros from InplaceOps.jl to avoid allocating matrices for each operation (which hopefully will become unnecessary once Julia decides on a standard syntax for in-place operations).
Prediction
Once we have forw for a single layer, calculating a prediction for the whole network is literally a one-liner:
forw(n::Net, x)=(for l=n x=forw(l,x) end; x)
This is the compact function definition syntax of Julia. There is no need to give this function a different name, Julia can distinguish it from forw(l::Layer,x) using the type of the first argument. I find myself thinking of silly names for related functions a lot less in Julia. The loop "for l=n" sets the variable l to each layer of the network n in turn, and we keep feeding the output of one layer as input to the next layer. The output of the final layer is returned. The source code also provides a "predict" function which is just a wrapper around "forw(n::Net,x)", its only difference is to chop up the input into minibatches and feed them to forw one batch at a time, mainly to allow the limited GPU memory to process large datasets.
Loss functions
In order to train the network, we need a loss function. A loss function takes y, the network output, and dy, the desired output, and returns a loss value which we try to minimize during training. In addition, it calculates the gradient of the loss with respect to y, which tells us how small changes in the network output will effect the loss. As an example, here is the implementation of softmaxloss (albeit a bit low level) in func.jl:
function softmaxloss(y, dy)
yrows,ycols = size(y)
loss = zero(eltype(y))
prob = similar(y, yrows)
for j=1:ycols
ymax = y[1,j]
for i=2:yrows y[i,j] > ymax && (ymax = y[i,j]) end
psum = zero(ymax)
for i=1:yrows
yij = y[i,j] - ymax
prob[i] = exp(yij)
psum += prob[i]
dy[i,j] == 1 && (loss += yij)
end
loss -= log(psum)
for i=1:yrows
prob[i] /= psum
dy[i,j] = (prob[i] - dy[i,j]) / ycols
end
end
return loss
end
By convention KUnet does not use an activation function in the last layer, so y is just the linear output of the last layer (prediction only cares about the max y). Softmax treats these y values as unnormalized log-probabilities, and all but the last few lines of the code is for normalizing them in a numerically stable manner. In fact only this single line calculates the gradient: dy[i,j] = (prob[i] - dy[i,j]) / ycols. We should note a couple of important design decisions here: (1) y and dy should have the same dimensionality, so use one-of-k encoding for desired classification outputs. (2) The loss function overwrites dy with the gradient of the loss with respect to y.
Backpropagation
Backpropagation is the algorithm that calculates the gradient of the loss with respect to network weights, given the gradient of the loss with respect to the network output. This can be accomplished taking a backward pass through the layers after the forward pass and the loss calculation:
function backprop(net::Net, x, dy, loss=softmaxloss)
y = forw(net, x) # y: network output
loss(y, dy) # dy: desired output -> gradient
back(net, dy) # calculate derivatives
end
Remember that the loss function overwrites its second argument dy with the loss gradient. The backward pass through the network simply calls the backward pass through each layer, from the output to the input:
back(n::Net, dy) = (for i=length(n):-1:1 dy=back(n[i],dy) end)
The backward pass through each layer takes the gradient with respect to its output, calculates the gradient with respect to its weights, and returns the gradient with respect to its input (i.e. the output of the previous layer):
function back(l::Layer, dy)
dy = l.f(l,l.y,dy)
l.dw = dy * l.x‘
l.db = sum!(l.db, dy)
l.dx = l.w‘ * dy
l.dx = l.fx(l,l.x,l.dx)
end
Note how the operations in back mirror the ones in forw. The arrays dy, l.dw, l.db and l.dx are the loss gradients with respect to l.y, l.w, l.b, and l.x. We saw l.f and l.fx as the activation and preprocessing functions in forw. Here, their three argument versions calculate gradients instead. That way we don‘t need to invent new names for the backward versions and run the risk of the user pairing the wrong forward and backward functions. Specifically l.f(l,l.y,dy) takes dy, the gradient wrt the layer output f(wx+b), and returns the gradient wrt the linear output wx+b. From that we compute the gradient with respect to w, b, and x. Finally the three argument version of l.fx calculates the gradient of the original input x (i.e. the output of the previous layer) from the gradient of the preprocessed x so the backpropagation can continue with the previous layer. By the end of this process, each layer has the gradients of its parameters stored in l.dw and l.db. I really think this is one case where the code is easier to understand than the math or the English explanation.
Training
The gradients calculated by backprop, l.dw and l.db, tell us how much small changes in corresponding entries in l.w and l.b will effect the loss (for the last instance, or minibatch). Small steps in the gradient direction will increase the loss, steps in the opposite direction will decrease the loss. This suggests the following update rule:
w = w - dw
This is the basic idea behind Stochastic Gradient Descent (SGD): Go over the training set instance by instance (or minibatch by minibatch). Run the backpropagation algorithm to calculate the loss gradients. Update the weights and biases in the opposite direction of these gradients. Rinse and repeat...
Over the years, people have noted many subtle problems with this approach and suggested improvements:
Step size: If the step sizes are too small, the SGD algorithm will take too long to converge. If they are too big it will overshoot the optimum and start to oscillate. So we scale the gradients with an adjustable parameter called the learning rate:
w = w - learningRate * dw
Step direction: More importantly, it turns out the gradient (or its opposite) is often NOT the direction you want to go in order to minimize loss. Let us illustrate with a simple picture:
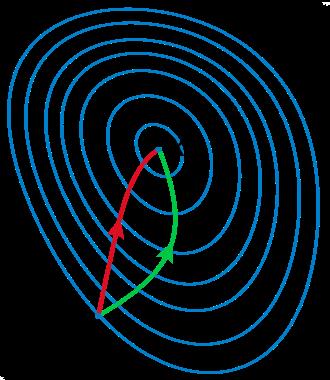
The two axes are w1 and w2, two parameters of our network, and the contour plot represents the loss with a minimum at x. If we start at x0, the Newton direction (in red) points almost towards the minimum, whereas the gradient (in green), perpendicular to the contours, points to the right.
Unfortunately Newton‘s direction is expensive to compute. However, it is also probably unnecessary for several reasons: (1) Newton gives us the ideal direction for second degree objective functions, which our neural network loss almost certainly is not, (2) The loss function whose gradient backprop calculated is the loss for the last minibatch/instance only, which at best is a very noisy version of the real loss function, so we shouldn‘t spend too much effort getting it exactly right.
So people have come up with various approximate methods to improve the step direction. Instead of multiplying each component of the gradient with the same learning rate, these methods scale them separately using their running average (momentum, Nesterov), or RMS (Adagrad, Rmsprop). I realize this necessarily short summary barely covers what has been implemented in KUnet and doesn‘t do justice to the literature or cover most of the important ideas. The interested reader can start with a standard textbook on numerical optimization, and peruse the latest papers on optimization in deep learning.
Minimize what? The final problem with gradient descent, other than not telling us the ideal step size or direction, is that it is not even minimizing the right objective! We want small loss on never before seen test data, not just on the training data. The truth is, a sufficiently large neural network with a good optimization algorithm can get arbitrarily low loss on any finite training data (e.g. by just memorizing the answers). And it can typically do so in many different ways (typically many different local minima for training loss in weight space exist). Some of those ways will generalize well to unseen data, some won‘t. And unseen data is (by definition) not seen, so how will we ever know which weight settings will do well on it? There are at least three ways people deal with this problem: (1) Bayes tells us that we should use all possible networks and weigh their answers by how well they do on training data (see Radford Neal‘s fbm), (2) New methods like dropout or adding distortions and noise to inputs and weights during training seem to help generalization, (3) Pressuring the optimization to stay in one corner of the weight space (e.g. L1, L2, maxnorm regularization) helps generalization.
KUnet views dropout (and other distortion methods) as a preprocessing step of each layer. The other techniques (learning rate, momentum, regularization etc.) are declared as UpdateParam‘s for l.w in l.pw and for l.b in l.pb for each layer:
type UpdateParam learningRate; l1reg; l2reg; maxnorm; adagrad; momentum; nesterov; ... end
Even though it is possible to set these parameters for each w and each b separately, KUnet provides convenience functions to set them for the whole layer, or the whole network:
setparam!(p::UpdateParam,k,v) setparam!(l::Layer,k,v) setparam!(net::Net,k,v)
The update function takes a parameter w, its gradient dw, and its UpdateParams o, and performs the necessary update. Here is the definition from update.jl:
function update(w, dw, o::UpdateParam)
initupdate(w, dw, o)
nz(o,:l1reg) && l1reg!(o.l1reg, w, dw)
nz(o,:l2reg) && l2reg!(o.l2reg, w, dw)
nz(o,:adagrad) && adagrad!(o.adagrad, o.ada, dw)
nz(o,:learningRate,1f0) && (dw = dw .* o.learningRate)
nz(o,:momentum) && momentum!(o.momentum, o.mom, dw)
nz(o,:nesterov) && nesterov!(o.nesterov, o.nes, dw)
w = w .- dw
nz(o,:maxnorm) && maxnorm!(o.maxnorm, w)
end
nz(o,n,v=0f0)=(isdefined(o,n) && (o.(n) != v))
The reader can peruse update.jl for the definitions of each of the helpers. This is one part of the code I haven‘t had time to "mathematize". I am hoping the helpers will be unnecessary one day and update will be expressed in easy to understand natural mathematical notation once Julia has in-place array operation syntax that is generic for GPUs.
The "train" function in net.jl is just a wrapper around "backprop" and "update". It goes through the training set once, splitting it into minibatches, and feeding each minibatch through backprop and update.
Activation functions
The activation function follows the linear transformation (wx+b) in a layer and is typically a non-linear element-wise function. Without an activation function, multiple layers in a neural network would be useless because the composition of several linear functions is still a linear function. As an example activation function l.f, here is the definition of the relu (rectified linear unit) from func.jl:
relu(l,y)=for i=1:length(y) (y[i]<0) && (y[i]=0) end relu(l,y,dy)=for i=1:length(y) (y[i]==0) && (dy[i]=0) end
The two argument version handles the forward calculation, i.e. replacing negative y values with 0. The three argument version handles the backward calculation, i.e. replacing dy gradients with 0 where y was 0. Unlike some other high-level languages, for loops are very efficient in Julia. These can probably be made even faster using "@parallel for" and multiple threads, but people who need performance will want to use the GPU versions:
relu(l,y::CudaArray)=ccall((:reluforw,libkunet),
Void,(Cint,Cmat),length(y),y)
relu(l,y::CudaArray,dy::CudaArray)=ccall((:reluback,libkunet),
Void,(Cint,Cmat,Cmat),length(dy),y,dy)
Being able to write GPU kernels directly in Julia is still work in progress. So for now I write a couple of lines of CUDA (the reluforw and reluback functions, which are basically the C versions of relu), compile it to a shared library (libkunet.so), and use Julia‘s (very convenient) ccall function to directly call them. This does not quite satisfy my "generic readable code" requirement but it is the simplest solution I found at this stage of JuliaGPU development. The nice thing is Julia automatically calls the GPU version if the y argument is a CudaArray and falls back on the pure Julia version otherwise. This allows the user to control whether calculations will be performed on the CPU or the GPU by declaring l.w and l.b as regular arrays or CudaArrays.
Preprocessing functions
A preprocessing function precedes the linear transformation (wx+b) modifying the input of the layer. Preprocessing functions typically add some noise to the input to improve generalization. For example dropout can be implemented as a preprocessing function of a layer where each input is dropped (replaced by 0) with a given probability. Adding Gaussian noise, or elastic transformations of image inputs can also be implemented as preprocessing functions. Here is the (simplified) dropout implementation from func.jl:
function drop(l, x)
rand!(l.xdrop)
drop(x, l.xdrop, l.dropout, 1/(1-l.dropout))
end
function drop(l, x, dx)
drop(dx, l.xdrop, l.dropout, 1/(1-l.dropout))
end
function drop(x, xdrop, dropout, scale)
for i=1:length(x)
x[i] = (xdrop[i] < dropout ? 0 : scale * x[i])
end
end
function drop(x::CudaArray, xdrop::CudaArray, dropout, scale)
ccall((:drop,libkunet),Void,(Cint,Cmat,Cmat,Cfloat,Cfloat),
length(x),x,xdrop,dropout,scale)
end
The two argument drop is for the forward calculation, the three argument version is for the backward calculation, and the last two are the CPU and GPU versions of the common helper. This implementation uses three fields of the layer type: l.fx is set to "drop", l.xdrop is an array of random numbers between 0 and 1 that has the same dimensionality as l.x, and l.dropout is the probability of dropping an input. Every time we receive a new x, rand! fills xdrop with new random numbers and a different subset of the input is dropped. The rest of the input is rescaled. Preprocessing is applied during training, not prediction, so the actual forw implementation takes an optional flag "apply_fx" that determines whether fx is to be applied.
Why Julia?
I wanted to write something that is concise, easy to understand, easy to extend, and reasonably efficient. There is a subtle trade-off between conciseness and extensibility: If we use a very high level language that already has a "neural_network_train" function, we can write very concise code but we lose the ability to change the training algorithm. If we use a very low level language that only provides primitive arithmetic operations, all the algorithm details are exposed and modifiable but the code is bulky and difficult to understand. For a happy medium, the code should reflect the level at which I think of the problem: e.g. I should be able to say A*B if I want to multiply two matrices, and I shouldn‘t constantly worry about the location and element types of my arrays. That restricts the playing field to a handful of languages. Efficiency requires being able to work with a GPU. Ideally the code should be generic, i.e. algorithms should be expressed once and work whether the data is on the GPU or the CPU memory. Julia has fledgling GPU support but it does have concise matrix arithmetic and it excels at generic operations. So I struggled a bit with trying to get generic matrix operations to work on the GPU (which is nowhere nearly complete but currently good enough to run the KUnet code), and to express each algorithm in as mathematical and concise a manner as possible (which is still work in progress, largely due to the lack of GPU generics and a standard syntax for in-place operations). But the progress so far (and the invaluable support I got from the Julia community) convinced me that this is a worthwhile endeavor.
Future work
With very little extra effort (and lines of code) one should be able to extend KUnet to implement convolutional and recurrent nets and new tricks like maxout units, maxnorm regularization, rmsprop optimization etc. You can send me suggestions for improvement (both in coding style and new functionality) using comments to this blog post, or using issuesor pull requests on GitHub.
from: http://www.denizyuret.com/2015/02/beginning-deep-learning-with-500-lines.html
以上是关于用500行Julia代码开始深度学习之旅 Beginning deep learning with 500 lines of Julia的主要内容,如果未能解决你的问题,请参考以下文章