count(*),count,count(字段)
Posted 吴大哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了count(*),count,count(字段)相关的知识,希望对你有一定的参考价值。
如果null参与聚集运算,则除count(*)之外其它聚集函数都忽略null.
如:
ID DD
1 e
2 null
select count(*) from table --结果是2
select count(DD) from table ---结果是1
按地区查询企业数目 实际上我只有4个企业填写了其区域编码测试的 count(字段) ,结果正确
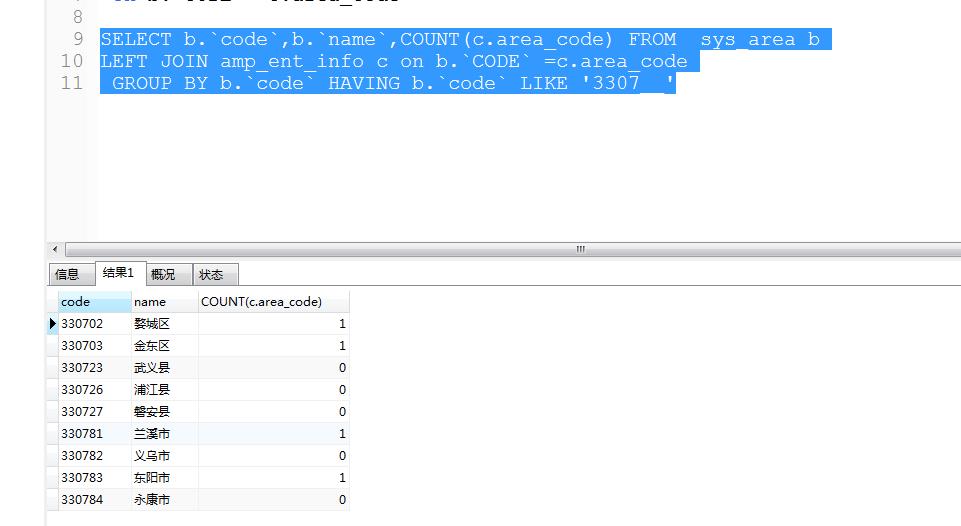
然而,用count(*),就不对。所以 数数的表字段的有null(空的没写的)请用字段来数,但是最后肯定是所以数据度不会空的,所以也一样
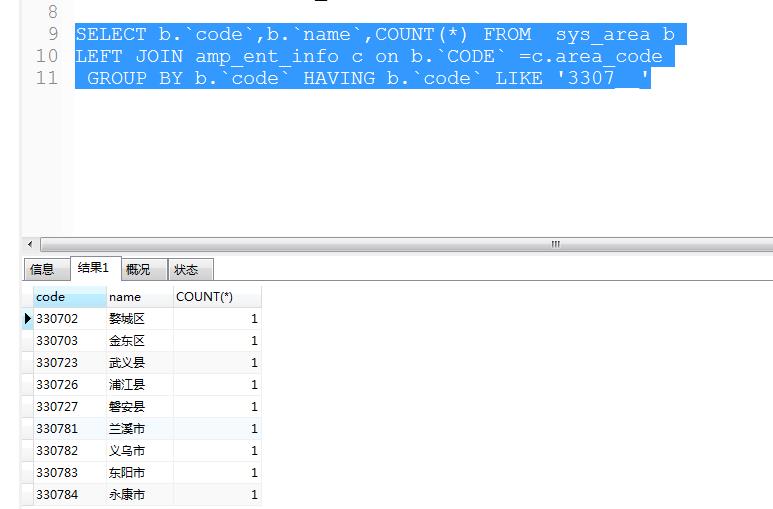
我在300万业务数据上测试的结果是count(ROWID),count(1),count(主键)这个三种情况速度差不多,
count(*)这种明显慢,察看执行计划,COUNT(*)时候走的是全表查询。
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!
从执行计划来看,count(1)和count(*)的效果是一样的。
但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
这个也与表的记录数多少有关!如果1w以外的数据量,做过表分析之后,反而count(1)的用时比count(*)多了。
另外,当数据量达到10w多的时候,使用count(1)要比使用count(*)的用时稍微少点!
如果你的数据表没有主键,那么count(1)比count(*)快
如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快
如果你的表只有一个字段的话那count(*)就是最快的啦
count(*) count(1) 两者比较。主要还是要count(1)所相对应的数据字段。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*),自动会优化指定到那一个字段。所以没必要去count(1),用count(*),sql会帮你完成优化的
因此:count(1)和count(*)基本没有差别!
sql调优,主要是考虑降低:consistent gets和physical reads的数量。
以上是关于count(*),count,count(字段)的主要内容,如果未能解决你的问题,请参考以下文章