pandas 数据处理遇到的问题
Posted zhengyyao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas 数据处理遇到的问题相关的知识,希望对你有一定的参考价值。
数据为DataFrame格式,如下:
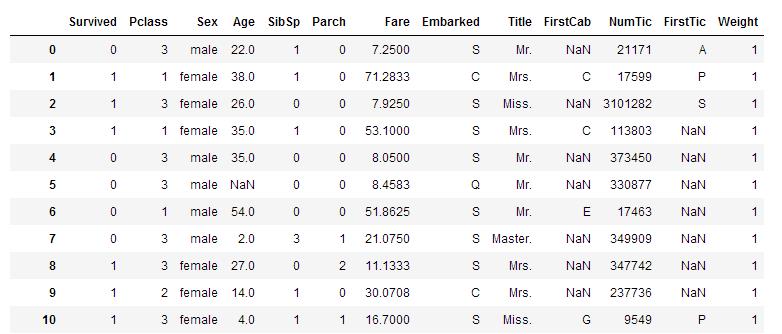
1.对每一行,FirstCab的值为空时,Weight的值乘以0.8
方法一(可行):df.loc[df[\'FirstCab\'].isnull(),\'Weight\'] *= 0.8
方法二(可行):df[\'Weight\'] = np.where(df[\'FirstCab\'].isnull(),df[\'Weight\']*0.8,df[\'Weight\'])
方法三(不可行):df[df[\'FirstCab\'].isnull()][\'Weight\'] *= 0.8 或者 df.loc[df[\'FirstCab\'].isnull(),:][\'Weight\'] *= 0.8
错误提示:A value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value instead.
方法四(不可行):df.assign(Weight=lambda x: x[\'Weight\']*0.8 if x[\'FirstCab\'].isnull() else x[\'Weight\'])
或者df.assign(Weight=lambda x: x[\'Weight\']*0.8 if x[\'FirstCab\'] == np.nan else x[\'Weight\'])
错误提示:ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
2.提取Ticket列末尾的数字,之后需要比较大小
Ticket列的值如:A/5. 2151 或者PP 9549 或者 333223或者LINE,提取末尾的数字,没有则返回NaN
方法一(可行):df[\'NumTic\']= df[\'Ticket\'].str.extract(\'(\\d{3,8})\',expand=False).astype(float)
方法二(不可行): df[\'NumTic\']= df[\'Ticket\'].str.extract(\'(\\d{3,8})\',expand=False)
错误提示: 保存的是字符型值,在比较大小或加减运算时出错
方法三(不可行):df[\'NumTic\']= df[\'Ticket\'].str.extract(\'(\\d{3,8})\',expand=False).astype(int)
错误提示:NaN不能转换为int型
3.对索引赋值是报错ValueError: Length mismatch: Expected axis has 678 elements, new values have 677 elements
代码如下:
attrValues = df[\'NumTic\'].sort_values()
#去重
attrValues = attrValues.drop_duplicates()
#修改index
attrValues.index = range(attrValues.count()) ###出错在这里
原因:attrValues中有一个NaN值, attrValues.count()不统计NaN值,所以attrValues.index的个数,比attrValues.count()大1

解决办法:
在首行代码中去掉df中的NaN值行,即attrValues = df[df[\'NumTic\'].notnull()].NumTic.sort_values()。
以上是关于pandas 数据处理遇到的问题的主要内容,如果未能解决你的问题,请参考以下文章