简单的爬取网页图片
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单的爬取网页图片相关的知识,希望对你有一定的参考价值。
import re
import urllib.request
# ------ 获取网页源代码的方法 ---
def gethtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
# ------ getHtml()内输入任意帖子的URL ------
html = getHtml("http://tieba.baidu.com/p/3205263090")
# ------ 修改html对象内的字符编码为UTF-8 ------
html = html.decode(‘UTF-8‘)
# ------ 获取帖子内所有图片地址的方法 ------
def getImg(html):
# ------ 利用正则表达式匹配网页内容找到图片地址 ------
reg = r‘src="([.*\\S]*\\.jpg)" pic_ext="jpeg"‘
imgre = re.compile(reg);
imglist = re.findall(imgre, html)
return imglist
imgList = getImg(html)
imgName = 0
for imgPath in imgList:
# ------ 这里最好使用异常处理及多线程编程方式 ------
f = open("F:/pic/"+str(imgName)+".jpg", ‘wb‘)
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgName += 1
print("All Done!")
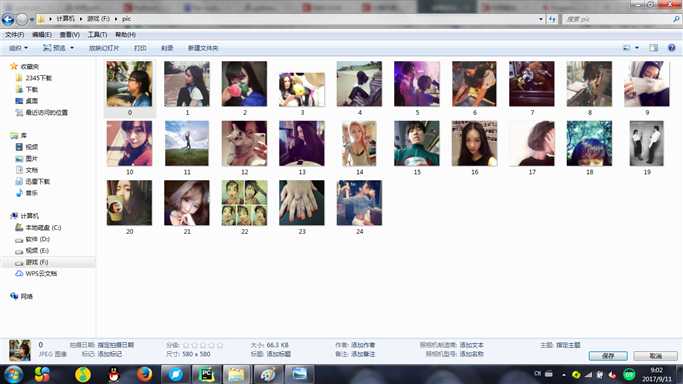
以上是关于简单的爬取网页图片的主要内容,如果未能解决你的问题,请参考以下文章