CNN可视化可行性
Posted The_kat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CNN可视化可行性相关的知识,希望对你有一定的参考价值。


PAD=1(就是上下左右各加数值为0的行列)


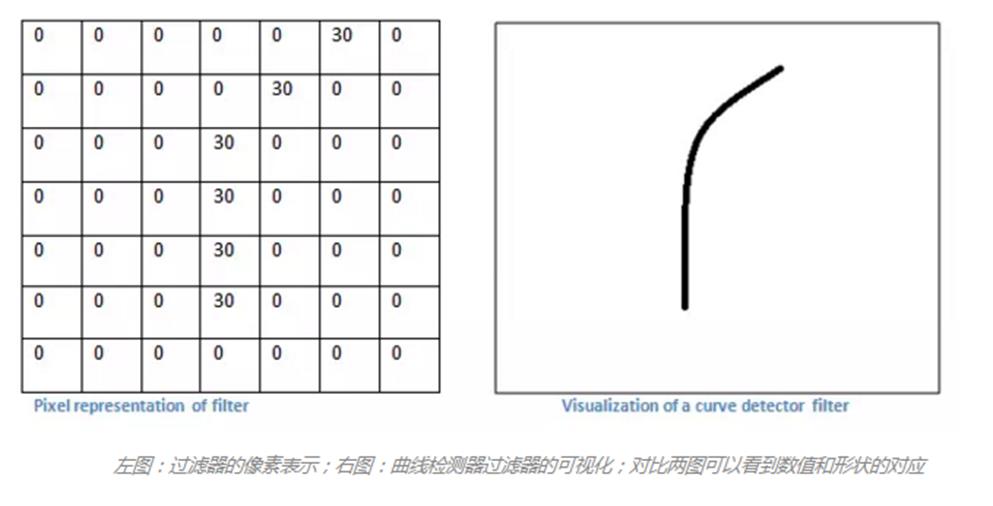




一次卷积过程类似于下图,下面动图是GIF图(上下图数据一致,但是只看方法),不过是三维的(可以看做比二维的多一个颜色维,RGB)。如果将上下图结合来看,下图只看两维的话,下面第一行就是把目标图(pad=1,上下左右各加一层0的行列。需要识别的图)利用过滤器求积,步长是2(每次向右向下移动两格,如果是1的话因为PAD=1,所以原来图像5*5卷积后不会变还是5*5)。
对这个三维数据的图像来说,卷积操作后,数据降为两维(RGB维度在卷积的时候求和加起来了,压缩至一维)。
那么,卷积后的维度便只跟filters的个数有关,如果有10个filters,那么卷积后的数据是10*3*3(如果步长是1,数据就是10*5*5,原来3*5*5的3是RGB维度,现在的10是神经元的维度)
那么对上图的理解就是,有一个过滤器(曲线)对整个图进行每个局部的求积,从而找到与其对应的最相似的局部(积最大),每个layer层都有若干过滤器,过滤器的值需要机器学习进行一次一次迭代修改,从而让机器自己找到最理想的卷积核(过滤器)例如上图的曲线是一个代表性的,或者一个圆等等,第一层一般都是边界,没有具体语义。
第一层的卷积核人类还可以进行一点解释,但是随着层数的深入,人类越难越能理解机器的识别出这个图片的方法和思维(即三层四层,以及更往后的层数),这就是所谓的“黑盒子”,我们不知道自己训练的机器自己学出了什么,到底什么影响了机器识别出图片、语言等等。哪些(神经元)filter是好的哪些是坏的,是多了还是少了,专家经常只能靠自己的经验和不断的试错才能最终调试出最理想的层数,和每层过滤器最理想的个数(专家所能调出的最理想的,事实上可能还有更好的模型)
过滤器的个数需要专家自己去设定,多了少了都不好,一般是凭借经验,现在可视化是可以与其相结合,将“黑箱子”打开,当然,虽然无法完全“打开”这个“黑盒”,但是仍然出现了很多探索这个“黑盒”的尝试工作。其中一个工作就是今天我们讨论的重点:可视化CNN模型,这里的可视化指的是可视化CNN模型中的卷积核。
可视化工作分为两大类:
一类是非参数化方法:这种方法不分析卷积核具体的参数,而是先选取图片库,然后将图片在已有模型中进行一次前向传播,对某个卷积核,我们使用对其响应最大的图片块来对之可视化
而另一类方法着重分析卷积核中的参数,使用参数重构出图像。
最初的可视化工作见于AlexNet[1]论文中。在这篇开创Deep Learning新纪元的论文中,Krizhevshy直接可视化了第一个卷积层的卷积核

我们知道,AlexNet[1]首层卷积层(conv1)的filters是(96,3,11,11)的四维blob:96个神经元,3个颜色分类(RGB),11*11的卷积核。
这样我们就可以得到上述96个11*11的图片块了。显然,这些重构出来的图像基本都是关于边缘,条纹以及颜色的信息。但是这种简单的方法却只适用于第一层卷积层,对于后面的卷积核我们就无法使用这种方法进行直接可视化了。
最开始使用图片块来可视化卷积核是在RCNN[2]论文中

Girshick[2]的工作显示了数据库中对AlexNet模型较高层(pool5)某个channel具有较强响应的图片块;
之后,在ZFNet[4]论文中,系统化地对AlexNet进行了可视化,并根据可视化结果改进了AlexNet得到了ZFNet,拿到了ILSVRC2014的冠军。这篇文章可以视为CNN可视化的真正开山之作,我们下面将重点分析一下这一篇:[1311.2901] Visualizing and Understanding Convolutional Networks
然后再2015年,Yosinski[5]根据以往的可视化成果(包括参数化和非参数化方法)开发了一个可用于可视化任意CNN模型的toolbox:yosinski/deep-visualization-toolbox,通过简单的配置安装之后,我们就可以对CNN模型进行可视化了。
以上是关于CNN可视化可行性的主要内容,如果未能解决你的问题,请参考以下文章